 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Polyphonic Sound Event Detection Using Convolutional Recurrent Neural Networks with Learned Time-Frequency Representation Input
Paper and Code
May 09, 2018
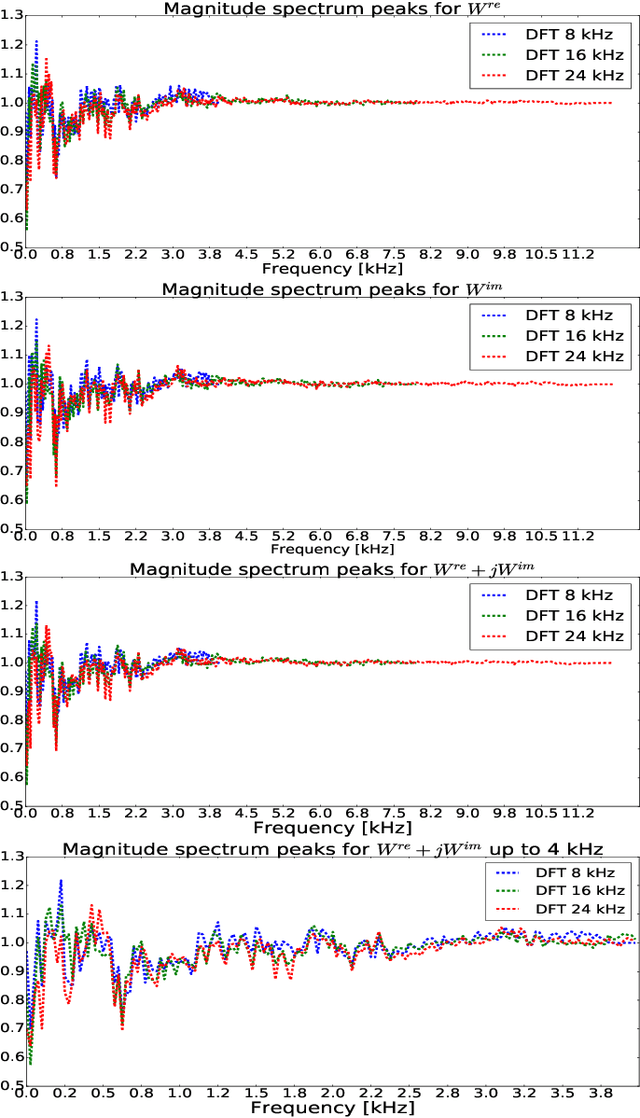
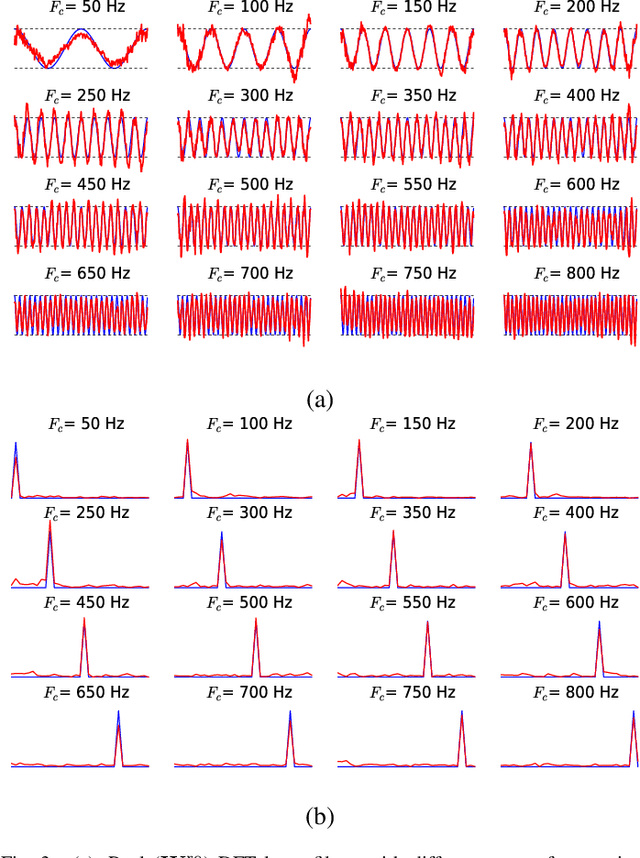
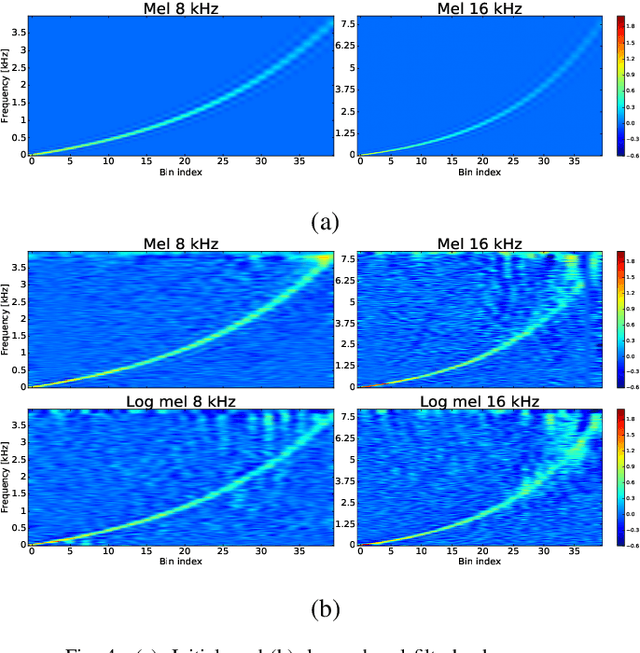
Sound event detection systems typically consist of two stages: extracting hand-crafted features from the raw audio waveform, and learning a mapping between these features and the target sound events using a classifier. Recently, the focus of sound event detection research has been mostly shifted to the latter stage using standard features such as mel spectrogram as the input for classifiers such as deep neural networks. In this work, we utilize end-to-end approach and propose to combine these two stages in a single deep neural network classifier. The feature extraction over the raw waveform is conducted by a feedforward layer block, whose parameters are initialized to extract the time-frequency representations. The feature extraction parameters are updated during training, resulting with a representation that is optimized for the specific task. This feature extraction block is followed by (and jointly trained with) a convolutional recurrent network, which has recently given state-of-the-art results in many sound recognition tasks. The proposed system does not outperform a convolutional recurrent network with fixed hand-crafted features. The final magnitude spectrum characteristics of the feature extraction block parameters indicate that the most relevant information for the given task is contained in 0 - 3 kHz frequency range, and this is also supported by the empirical results on the SED performance.