 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Regularization Based on Infrequent Classes for Audio Captioning
Paper and Code
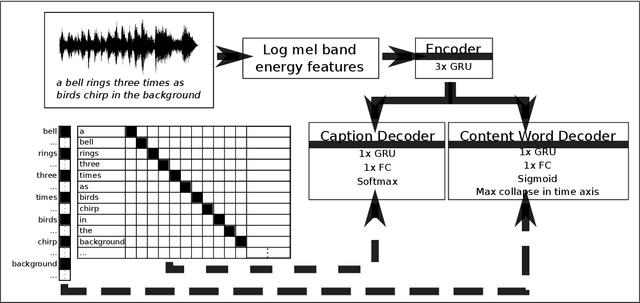
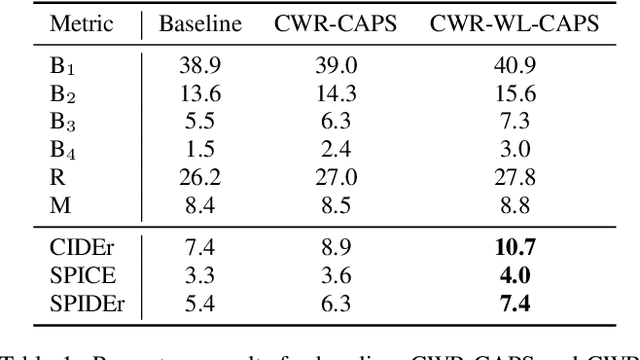
Audio captioning is a multi-modal task, focusing on using natural language for describing the contents of general audio. Most audio captioning methods are based on deep neural networks, employing an encoder-decoder scheme and a dataset with audio clips and corresponding natural language descriptions (i.e. captions). A significant challenge for audio captioning is the distribution of words in the captions: some words are very frequent but acoustically non-informative, i.e. the function words (e.g. "a", "the"), and other words are infrequent but informative, i.e. the content words (e.g. adjectives, nouns). In this paper we propose two methods to mitigate this class imbalance problem. First, in an autoencoder setting for audio captioning, we weigh each word's contribution to the training loss inversely proportional to its number of occurrences in the whole dataset. Secondly, in addition to multi-class, word-level audio captioning task, we define a multi-label side task based on clip-level content word detection by training a separate decoder. We use the loss from the second task to regularize the jointly trained encoder for the audio captioning task. We evaluate our method using Clotho, a recently published, wide-scale audio captioning dataset, and our results show an increase of 37\% relative improvement with SPIDEr metric over the baseline method.