 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Methodological Framework for the Comparative Evaluation of Multiple Imputation Methods: Multiple Imputation of Race, Ethnicity and Body Mass Index in the U.S. National COVID Cohort Collaborative
Jun 13, 2022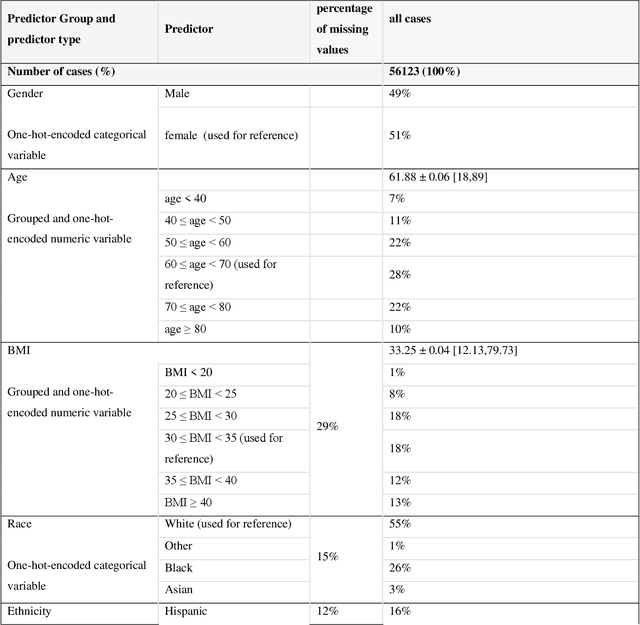
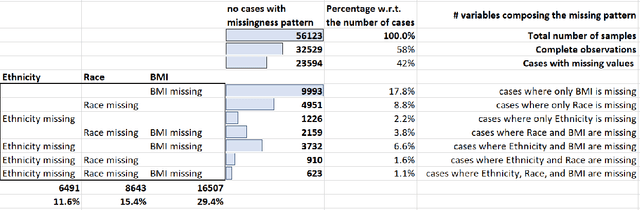

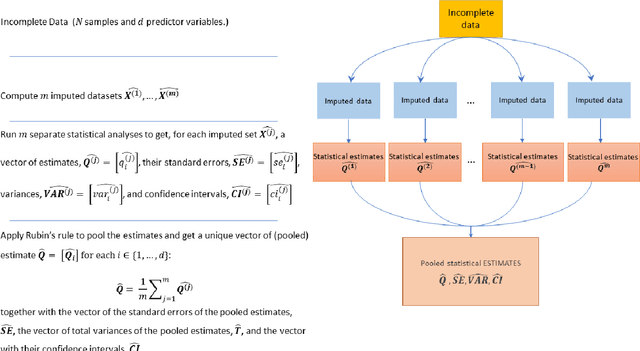
While electronic health records are a rich data source for biomedical research, these systems are not implemented uniformly across healthcare settings and significant data may be missing due to healthcare fragmentation and lack of interoperability between siloed electronic health records. Considering that the deletion of cases with missing data may introduce severe bias in the subsequent analysis, several authors prefer applying a multiple imputation strategy to recover the missing information. Unfortunately, although several literature works have documented promising results by using any of the different multiple imputation algorithms that are now freely available for research, there is no consensus on which MI algorithm works best. Beside the choice of the MI strategy, the choice of the imputation algorithm and its application settings are also both crucial and challenging. In this paper, inspired by the seminal works of Rubin and van Buuren, we propose a methodological framework that may be applied to evaluate and compare several multiple imputation techniques, with the aim to choose the most valid for computing inferences in a clinical research work. Our framework has been applied to validate, and extend on a larger cohort, the results we presented in a previous literature study, where we evaluated the influence of crucial patients' descriptors and COVID-19 severity in patients with type 2 diabetes mellitus whose data is provided by the National COVID Cohort Collaborative Enclave.
An Open Natural Language Processing Development Framework for EHR-based Clinical Research: A case demonstration using the National COVID Cohort Collaborative (N3C)
Oct 20, 2021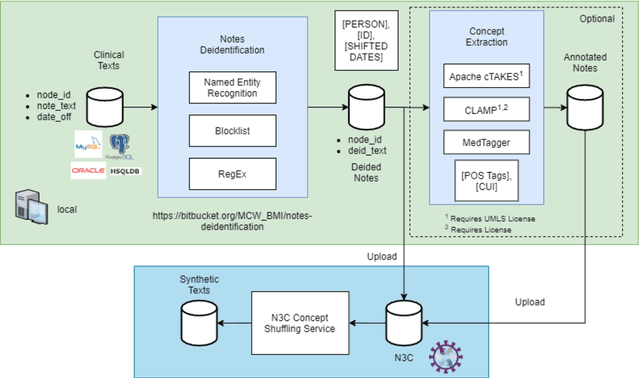

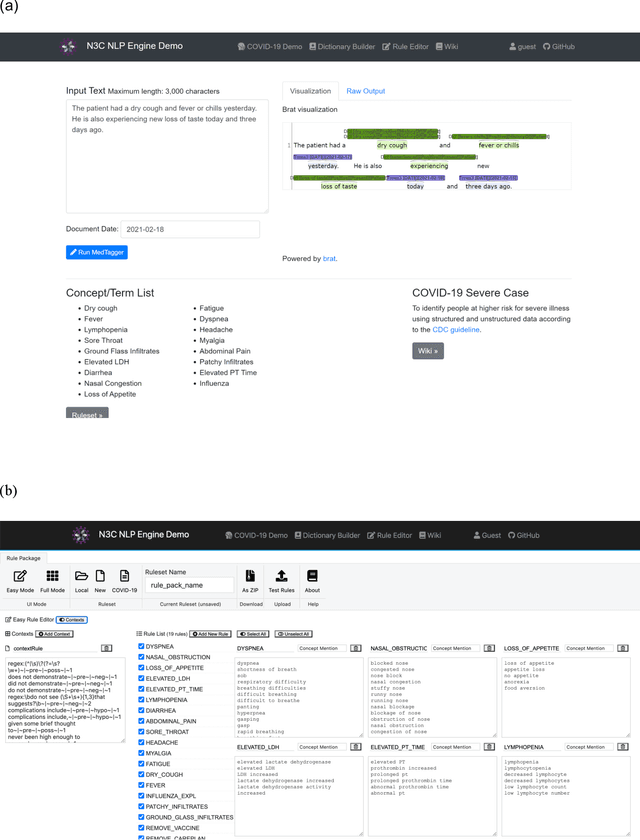
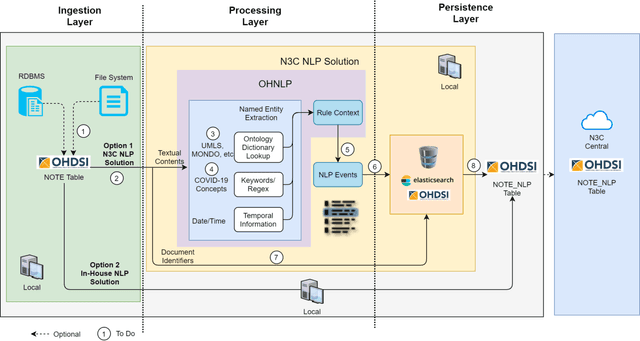
While we pay attention to the latest advances in clinical natural language processing (NLP), we can notice some resistance in the clinical and translational research community to adopt NLP models due to limited transparency, Interpretability and usability. Built upon our previous work, in this study, we proposed an open natural language processing development framework and evaluated it through the implementation of NLP algorithms for the National COVID Cohort Collaborative (N3C). Based on the interests in information extraction from COVID-19 related clinical notes, our work includes 1) an open data annotation process using COVID-19 signs and symptoms as the use case, 2) a community-driven ruleset composing platform, and 3) a synthetic text data generation workflow to generate texts for information extraction tasks without involving human subjects. The generated corpora derived out of the texts from multiple intuitions and gold standard annotation are tested on a single institution's rule set has the performances in F1 score of 0.876, 0.706 and 0.694, respectively. The study as a consortium effort of the N3C NLP subgroup demonstrates the feasibility of creating a federated NLP algorithm development and benchmarking platform to enhance multi-institution clinical NLP study.