 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Generated Music Detection in Broadcast Monitoring
Feb 06, 2026AI music generators have advanced to the point where their outputs are often indistinguishable from human compositions. While detection methods have emerged, they are typically designed and validated in music streaming contexts with clean, full-length tracks. Broadcast audio, however, poses a different challenge: music appears as short excerpts, often masked by dominant speech, conditions under which existing detectors fail. In this work, we introduce AI-OpenBMAT, the first dataset tailored to broadcast-style AI-music detection. It contains 3,294 one-minute audio excerpts (54.9 hours) that follow the duration patterns and loudness relations of real television audio, combining human-made production music with stylistically matched continuations generated with Suno v3.5. We benchmark a CNN baseline and state-of-the-art SpectTTTra models to assess SNR and duration robustness, and evaluate on a full broadcast scenario. Across all settings, models that excel in streaming scenarios suffer substantial degradation, with F1-scores dropping below 60% when music is in the background or has a short duration. These results highlight speech masking and short music length as critical open challenges for AI music detection, and position AI-OpenBMAT as a benchmark for developing detectors capable of meeting industrial broadcast requirements.
Investigating the efficacy of music version retrieval systems for setlist identification
Jan 06, 2021
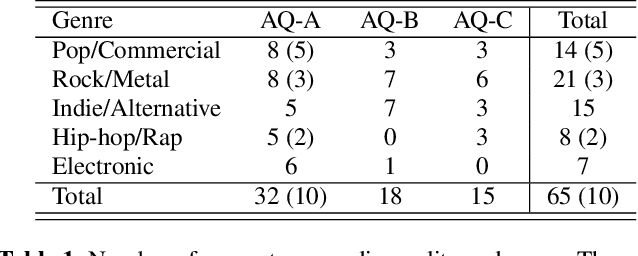

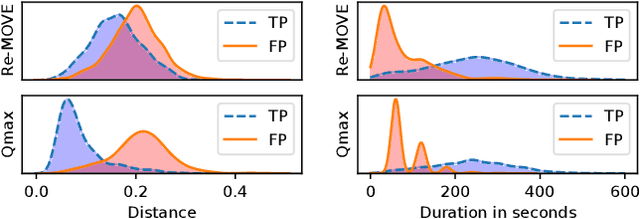
The setlist identification (SLI) task addresses a music recognition use case where the goal is to retrieve the metadata and timestamps for all the tracks played in live music events. Due to various musical and non-musical changes in live performances, developing automatic SLI systems is still a challenging task that, despite its industrial relevance, has been under-explored in the academic literature. In this paper, we propose an end-to-end workflow that identifies relevant metadata and timestamps of live music performances using a version identification system. We compare 3 of such systems to investigate their suitability for this particular task. For developing and evaluating SLI systems, we also contribute a new dataset that contains 99.5h of concerts with annotated metadata and timestamps, along with the corresponding reference set. The dataset is categorized by audio qualities and genres to analyze the performance of SLI systems in different use cases. Our approach can identify 68% of the annotated segments, with values ranging from 35% to 77% based on the genre. Finally, we evaluate our approach against a database of 56.8k songs to illustrate the effect of expanding the reference set, where we can still identify 56% of the annotated segments.