 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy Feature Importance Avoids Unrestricted Permutations
Apr 13, 2026Feature importance methods using unrestricted permutations are flawed due to extrapolation errors; such errors appear in all non-trivial variable importance approaches. We propose three new approaches: conditional model reliance and Knockoffs with Gaussian transformation, and restricted ALE plot designs. Theoretical and numerical results show our strategies reduce/eliminate extrapolation.
Doctor Rashomon and the UNIVERSE of Madness: Variable Importance with Unobserved Confounding and the Rashomon Effect
Oct 14, 2025



Variable importance (VI) methods are often used for hypothesis generation, feature selection, and scientific validation. In the standard VI pipeline, an analyst estimates VI for a single predictive model with only the observed features. However, the importance of a feature depends heavily on which other variables are included in the model, and essential variables are often omitted from observational datasets. Moreover, the VI estimated for one model is often not the same as the VI estimated for another equally-good model - a phenomenon known as the Rashomon Effect. We address these gaps by introducing UNobservables and Inference for Variable importancE using Rashomon SEts (UNIVERSE). Our approach adapts Rashomon sets - the sets of near-optimal models in a dataset - to produce bounds on the true VI even with missing features. We theoretically guarantee the robustness of our approach, show strong performance on semi-synthetic simulations, and demonstrate its utility in a credit risk task.
No for Some, Yes for Others: Persona Prompts and Other Sources of False Refusal in Language Models
Sep 09, 2025Large language models (LLMs) are increasingly integrated into our daily lives and personalized. However, LLM personalization might also increase unintended side effects. Recent work suggests that persona prompting can lead models to falsely refuse user requests. However, no work has fully quantified the extent of this issue. To address this gap, we measure the impact of 15 sociodemographic personas (based on gender, race, religion, and disability) on false refusal. To control for other factors, we also test 16 different models, 3 tasks (Natural Language Inference, politeness, and offensiveness classification), and nine prompt paraphrases. We propose a Monte Carlo-based method to quantify this issue in a sample-efficient manner. Our results show that as models become more capable, personas impact the refusal rate less and less. Certain sociodemographic personas increase false refusal in some models, which suggests underlying biases in the alignment strategies or safety mechanisms. However, we find that the model choice and task significantly influence false refusals, especially in sensitive content tasks. Our findings suggest that persona effects have been overestimated, and might be due to other factors.
Neural Conditional Transport Maps
May 21, 2025We present a neural framework for learning conditional optimal transport (OT) maps between probability distributions. Our approach introduces a conditioning mechanism capable of processing both categorical and continuous conditioning variables simultaneously. At the core of our method lies a hypernetwork that generates transport layer parameters based on these inputs, creating adaptive mappings that outperform simpler conditioning methods. Comprehensive ablation studies demonstrate the superior performance of our method over baseline configurations. Furthermore, we showcase an application to global sensitivity analysis, offering high performance in computing OT-based sensitivity indices. This work advances the state-of-the-art in conditional optimal transport, enabling broader application of optimal transport principles to complex, high-dimensional domains such as generative modeling and black-box model explainability.
The Mean Dimension of Neural Networks -- What causes the interaction effects?
Jul 11, 2022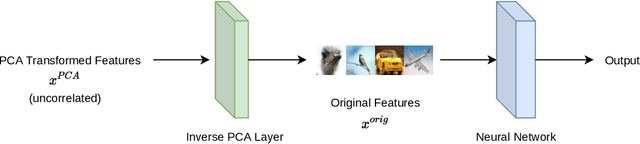

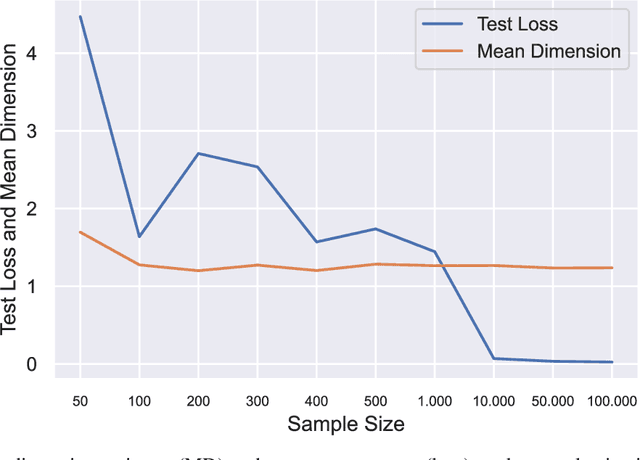
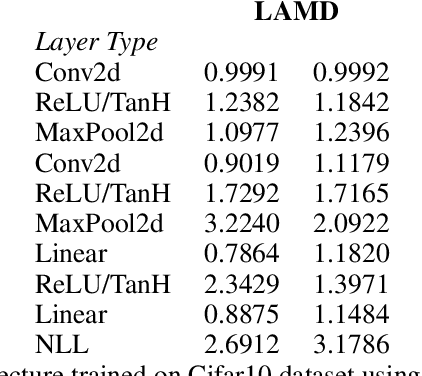
Owen and Hoyt recently showed that the effective dimension offers key structural information about the input-output mapping underlying an artificial neural network. Along this line of research, this work proposes an estimation procedure that allows the calculation of the mean dimension from a given dataset, without resampling from external distributions. The design yields total indices when features are independent and a variant of total indices when features are correlated. We show that this variant possesses the zero independence property. With synthetic datasets, we analyse how the mean dimension evolves layer by layer and how the activation function impacts the magnitude of interactions. We then use the mean dimension to study some of the most widely employed convolutional architectures for image recognition (LeNet, ResNet, DenseNet). To account for pixel correlations, we propose calculating the mean dimension after the addition of an inverse PCA layer that allows one to work on uncorrelated PCA-transformed features, without the need to retrain the neural network. We use the generalized total indices to produce heatmaps for post-hoc explanations, and we employ the mean dimension on the PCA-transformed features for cross comparisons of the artificial neural networks structures. Results provide several insights on the difference in magnitude of interactions across the architectures, as well as indications on how the mean dimension evolves during training.