 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaining Insights into Unrecognized User Utterances in Task-Oriented Dialog Systems
Apr 11, 2022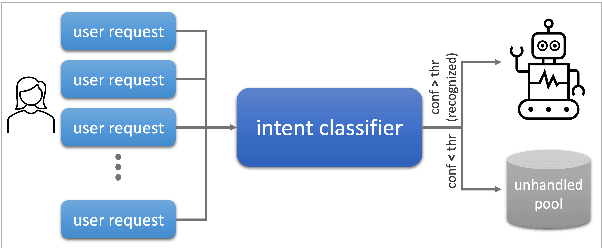

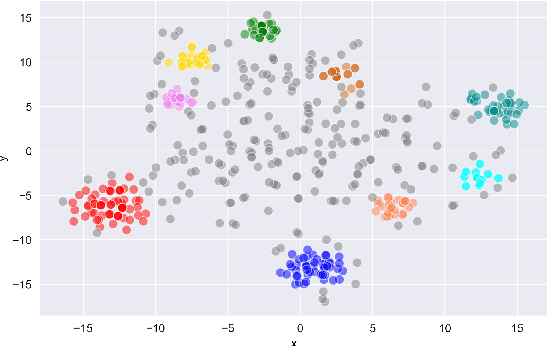
The rapidly growing market demand for dialogue agents capable of goal-oriented behavior has caused many tech-industry leaders to invest considerable efforts into task-oriented dialog systems. The performance and success of these systems is highly dependent on the accuracy of their intent identification -- the process of deducing the goal or meaning of the user's request and mapping it to one of the known intents for further processing. Gaining insights into unrecognized utterances -- user requests the systems fails to attribute to a known intent -- is therefore a key process in continuous improvement of goal-oriented dialog systems. We present an end-to-end pipeline for processing unrecognized user utterances, including a specifically-tailored clustering algorithm, a novel approach to cluster representative extraction, and cluster naming. We evaluated the proposed clustering algorithm and compared its performance to out-of-the-box SOTA solutions, demonstrating its benefits in the analysis of unrecognized user requests.
We've had this conversation before: A Novel Approach to Measuring Dialog Similarity
Oct 12, 2021
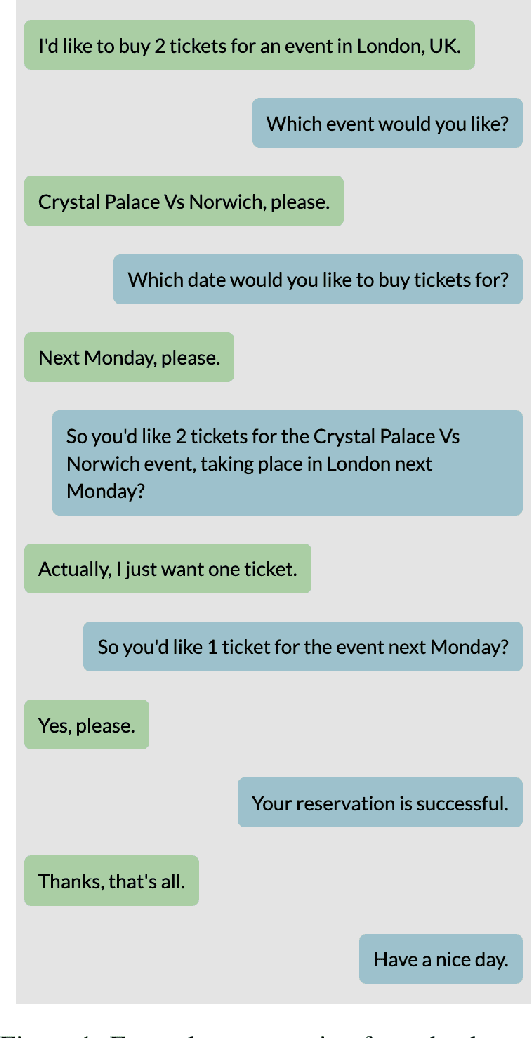
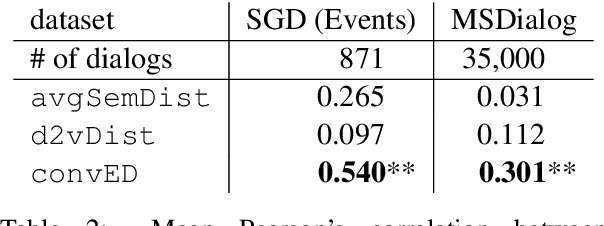
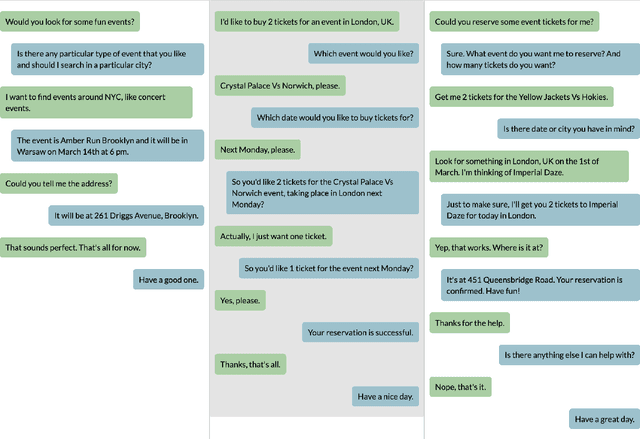
Dialog is a core building block of human natural language interactions. It contains multi-party utterances used to convey information from one party to another in a dynamic and evolving manner. The ability to compare dialogs is beneficial in many real world use cases, such as conversation analytics for contact center calls and virtual agent design. We propose a novel adaptation of the edit distance metric to the scenario of dialog similarity. Our approach takes into account various conversation aspects such as utterance semantics, conversation flow, and the participants. We evaluate this new approach and compare it to existing document similarity measures on two publicly available datasets. The results demonstrate that our method outperforms the other approaches in capturing dialog flow, and is better aligned with the human perception of conversation similarity.
Quantifying Cognitive Factors in Lexical Decline
Oct 12, 2021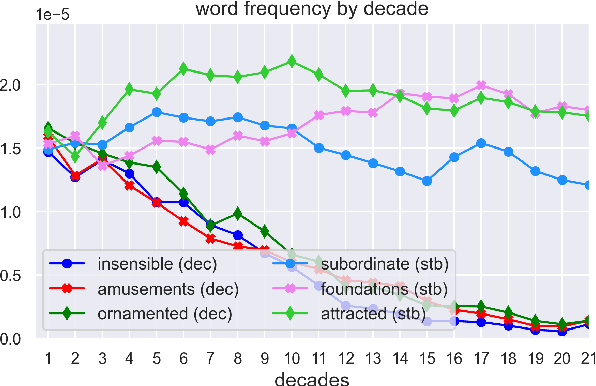
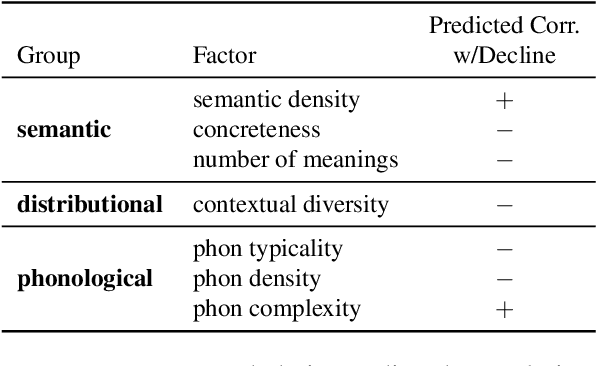
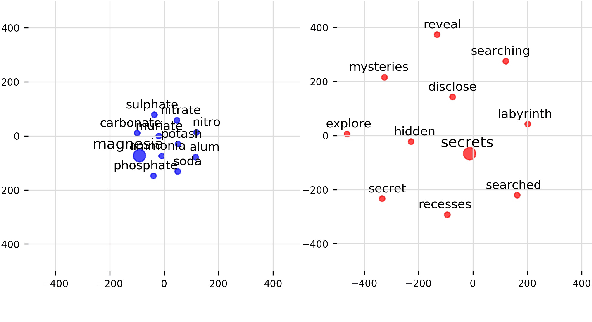
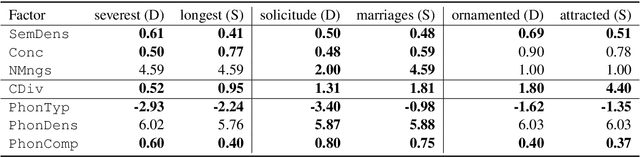
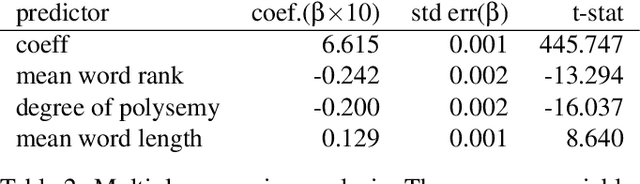
We adopt an evolutionary view on language change in which cognitive factors (in addition to social ones) affect the fitness of words and their success in the linguistic ecosystem. Specifically, we propose a variety of psycholinguistic factors -- semantic, distributional, and phonological -- that we hypothesize are predictive of lexical decline, in which words greatly decrease in frequency over time. Using historical data across three languages (English, French, and German), we find that most of our proposed factors show a significant difference in the expected direction between each curated set of declining words and their matched stable words. Moreover, logistic regression analyses show that semantic and distributional factors are significant in predicting declining words. Further diachronic analysis reveals that declining words tend to decrease in the diversity of their lexical contexts over time, gradually narrowing their 'ecological niches'.
Pick a Fight or Bite your Tongue: Investigation of Gender Differences in Idiomatic Language Usage
Oct 31, 2020
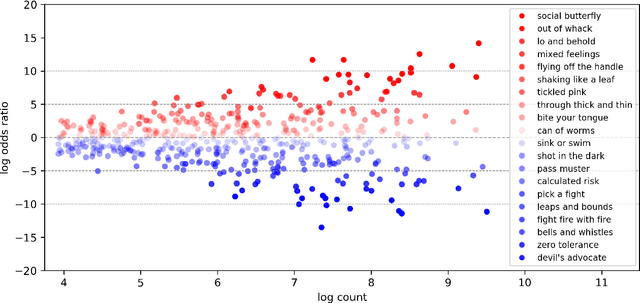
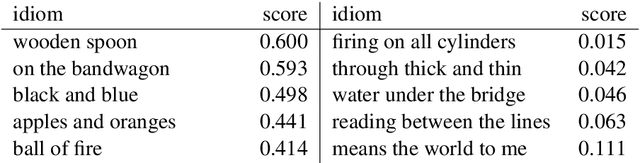
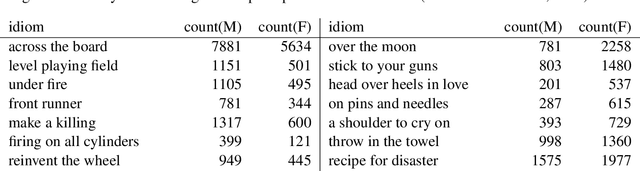
A large body of research on gender-linked language has established foundations regarding cross-gender differences in lexical, emotional, and topical preferences, along with their sociological underpinnings. We compile a novel, large and diverse corpus of spontaneous linguistic productions annotated with speakers' gender, and perform a first large-scale empirical study of distinctions in the usage of \textit{figurative language} between male and female authors. Our analyses suggest that (1) idiomatic choices reflect gender-specific lexical and semantic preferences in general language, (2) men's and women's idiomatic usages express higher emotion than their literal language, with detectable, albeit more subtle, differences between male and female authors along the dimension of dominance compared to similar distinctions in their literal utterances, and (3) contextual analysis of idiomatic expressions reveals considerable differences, reflecting subtle divergences in usage environments, shaped by cross-gender communication styles and semantic biases.
Exploration of Gender Differences in COVID-19 Discourse on Reddit
Aug 13, 2020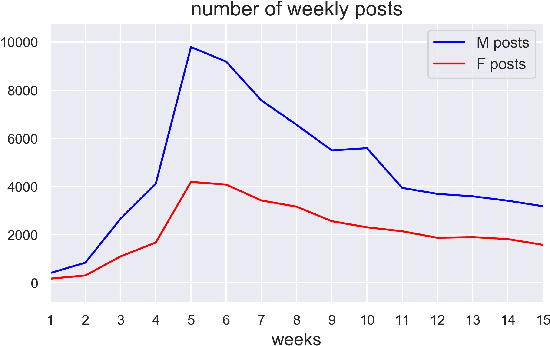

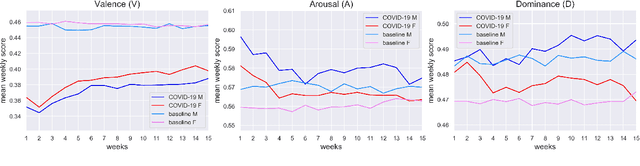

Decades of research on differences in the language of men and women have established postulates about preferences in lexical, topical, and emotional expression between the two genders, along with their sociological underpinnings. Using a novel dataset of male and female linguistic productions collected from the Reddit discussion platform, we further confirm existing assumptions about gender-linked affective distinctions, and demonstrate that these distinctions are amplified in social media postings involving emotionally-charged discourse related to COVID-19. Our analysis also confirms considerable differences in topical preferences between male and female authors in spontaneous pandemic-related discussions.
The Typology of Polysemy: A Multilingual Distributional Framework
Jun 02, 2020

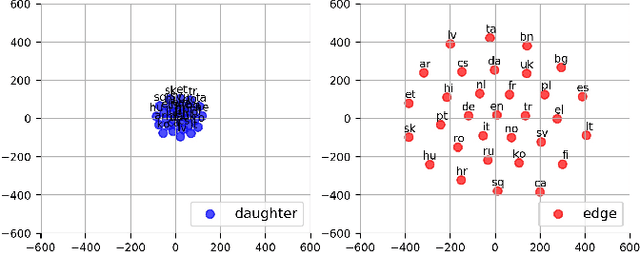
Lexical semantic typology has identified important cross-linguistic generalizations about the variation and commonalities in polysemy patterns---how languages package up meanings into words. Recent computational research has enabled investigation of lexical semantics at a much larger scale, but little work has explored lexical typology across semantic domains, nor the factors that influence cross-linguistic similarities. We present a novel computational framework that quantifies semantic affinity, the cross-linguistic similarity of lexical semantics for a concept. Our approach defines a common multilingual semantic space that enables a direct comparison of the lexical expression of concepts across languages. We validate our framework against empirical findings on lexical semantic typology at both the concept and domain levels. Our results reveal an intricate interaction between semantic domains and extra-linguistic factors, beyond language phylogeny, that co-shape the typology of polysemy across languages.
Where New Words Are Born: Distributional Semantic Analysis of Neologisms and Their Semantic Neighborhoods
Jan 21, 2020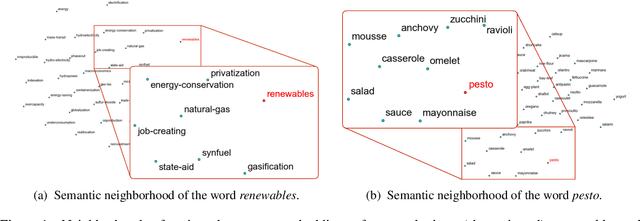
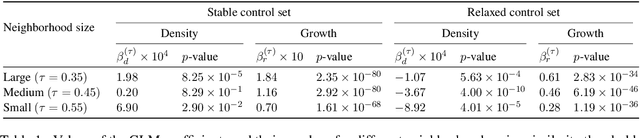
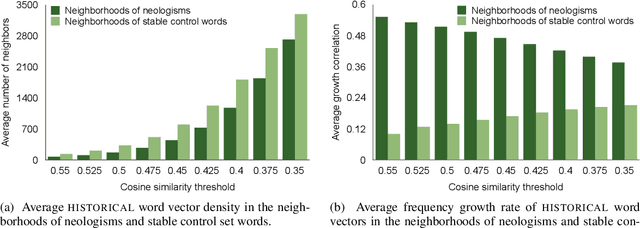

We perform statistical analysis of the phenomenon of neology, the process by which new words emerge in a language, using large diachronic corpora of English. We investigate the importance of two factors, semantic sparsity and frequency growth rates of semantic neighbors, formalized in the distributional semantics paradigm. We show that both factors are predictive of word emergence although we find more support for the latter hypothesis. Besides presenting a new linguistic application of distributional semantics, this study tackles the linguistic question of the role of language-internal factors (in our case, sparsity) in language change motivated by language-external factors (reflected in frequency growth).
* SCiL 2020
Say Anything: Automatic Semantic Infelicity Detection in L2 English Indefinite Pronouns
Sep 17, 2019
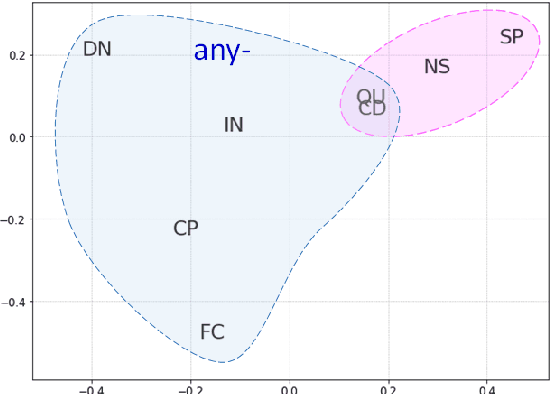

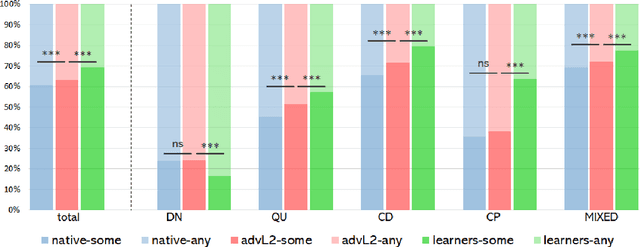
Computational research on error detection in second language speakers has mainly addressed clear grammatical anomalies typical to learners at the beginner-to-intermediate level. We focus instead on acquisition of subtle semantic nuances of English indefinite pronouns by non-native speakers at varying levels of proficiency. We first lay out theoretical, linguistically motivated hypotheses, and supporting empirical evidence on the nature of the challenges posed by indefinite pronouns to English learners. We then suggest and evaluate an automatic approach for detection of atypical usage patterns, demonstrating that deep learning architectures are promising for this task involving nuanced semantic anomalies.
CodeSwitch-Reddit: Exploration of Written Multilingual Discourse in Online Discussion Forums
Aug 30, 2019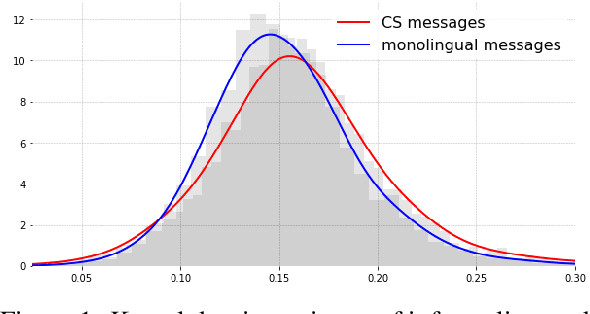
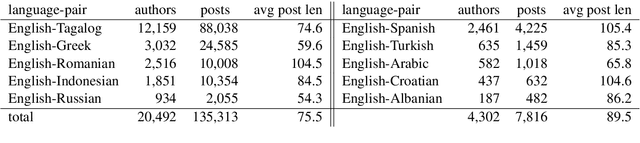
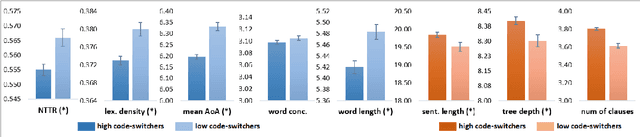
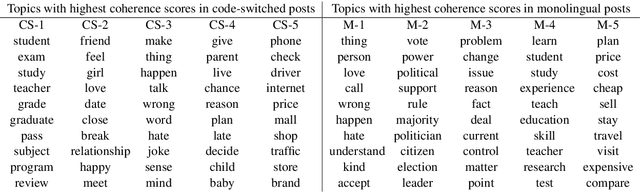
In contrast to many decades of research on oral code-switching, the study of written multilingual productions has only recently enjoyed a surge of interest. Many open questions remain regarding the sociolinguistic underpinnings of written code-switching, and progress has been limited by a lack of suitable resources. We introduce a novel, large, and diverse dataset of written code-switched productions, curated from topical threads of multiple bilingual communities on the Reddit discussion platform, and explore questions that were mainly addressed in the context of spoken language thus far. We investigate whether findings in oral code-switching concerning content and style, as well as speaker proficiency, are carried over into written code-switching in discussion forums. The released dataset can further facilitate a range of research and practical activities.
Controversy in Context
Aug 20, 2019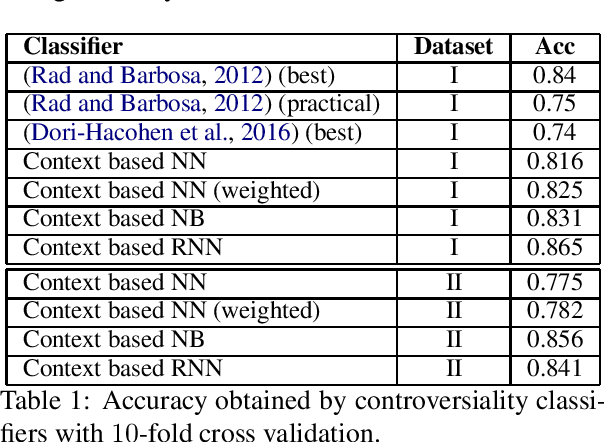
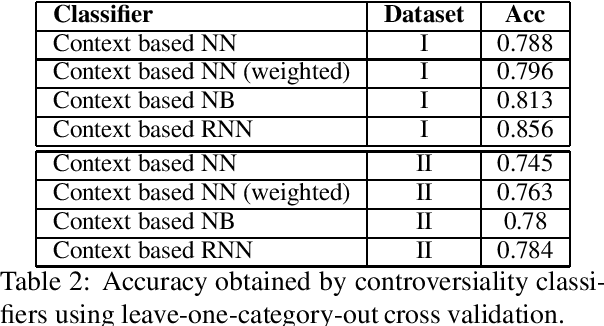
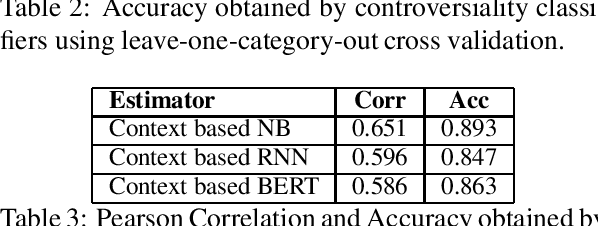
With the growing interest in social applications of Natural Language Processing and Computational Argumentation, a natural question is how controversial a given concept is. Prior works relied on Wikipedia's metadata and on content analysis of the articles pertaining to a concept in question. Here we show that the immediate textual context of a concept is strongly indicative of this property, and, using simple and language-independent machine-learning tools, we leverage this observation to achieve state-of-the-art results in controversiality prediction. In addition, we analyze and make available a new dataset of concepts labeled for controversiality. It is significantly larger than existing datasets, and grades concepts on a 0-10 scale, rather than treating controversiality as a binary label.