 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControversy in Context
Paper and Code
Aug 20, 2019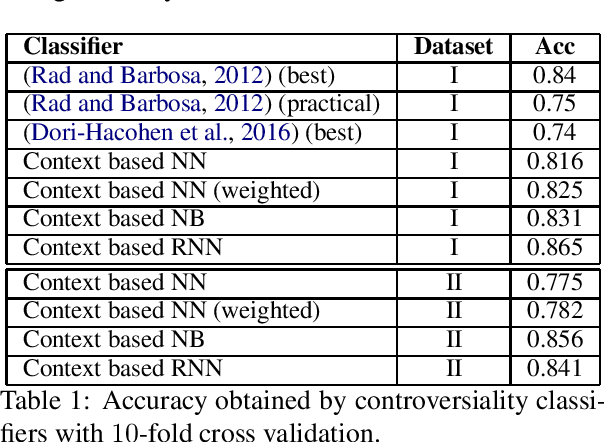
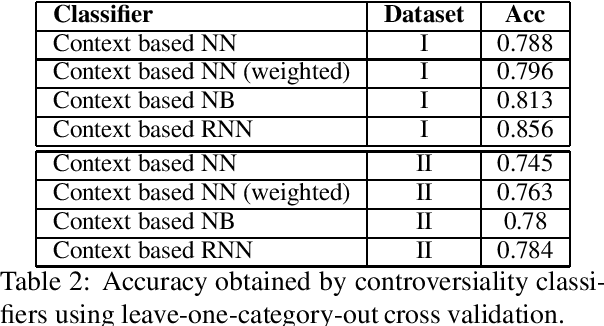
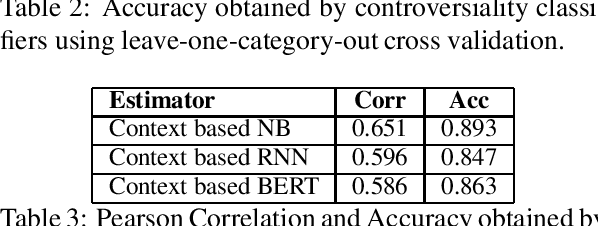
With the growing interest in social applications of Natural Language Processing and Computational Argumentation, a natural question is how controversial a given concept is. Prior works relied on Wikipedia's metadata and on content analysis of the articles pertaining to a concept in question. Here we show that the immediate textual context of a concept is strongly indicative of this property, and, using simple and language-independent machine-learning tools, we leverage this observation to achieve state-of-the-art results in controversiality prediction. In addition, we analyze and make available a new dataset of concepts labeled for controversiality. It is significantly larger than existing datasets, and grades concepts on a 0-10 scale, rather than treating controversiality as a binary label.