 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on Accuracy, Miscalibration, and Popularity Bias in Recommendations
Mar 01, 2023



Recent research has suggested different metrics to measure the inconsistency of recommendation performance, including the accuracy difference between user groups, miscalibration, and popularity lift. However, a study that relates miscalibration and popularity lift to recommendation accuracy across different user groups is still missing. Additionally, it is unclear if particular genres contribute to the emergence of inconsistency in recommendation performance across user groups. In this paper, we present an analysis of these three aspects of five well-known recommendation algorithms for user groups that differ in their preference for popular content. Additionally, we study how different genres affect the inconsistency of recommendation performance, and how this is aligned with the popularity of the genres. Using data from LastFm, MovieLens, and MyAnimeList, we present two key findings. First, we find that users with little interest in popular content receive the worst recommendation accuracy, and that this is aligned with miscalibration and popularity lift. Second, our experiments show that particular genres contribute to a different extent to the inconsistency of recommendation performance, especially in terms of miscalibration in the case of the MyAnimeList dataset.
Adversarial Inter-Group Link Injection Degrades the Fairness of Graph Neural Networks
Sep 13, 2022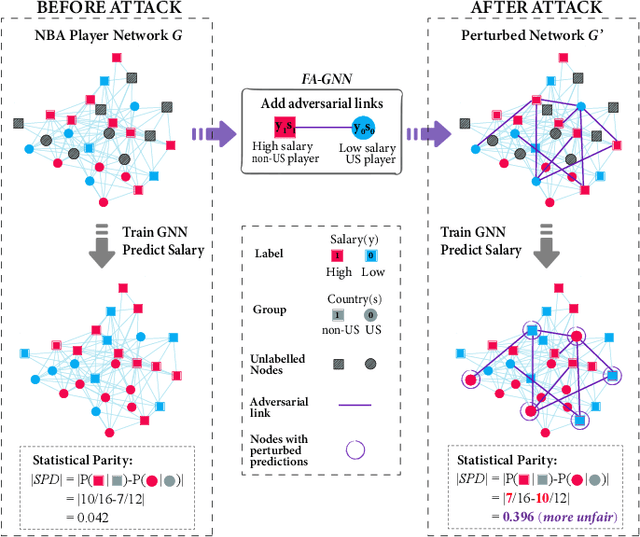
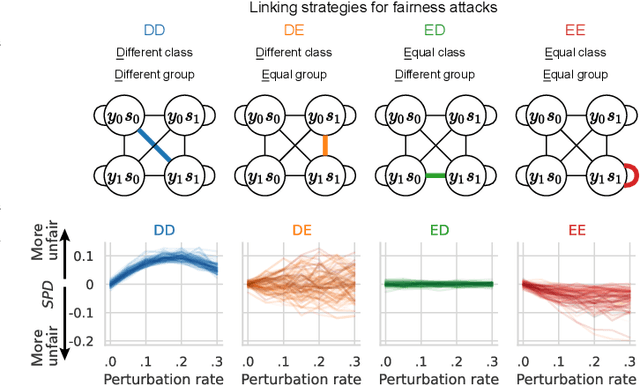
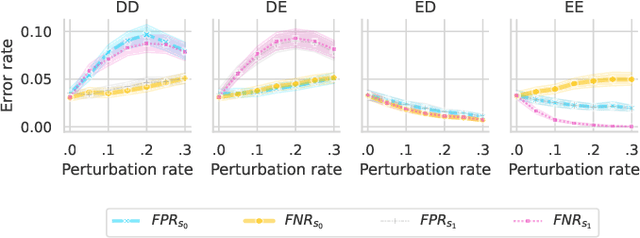
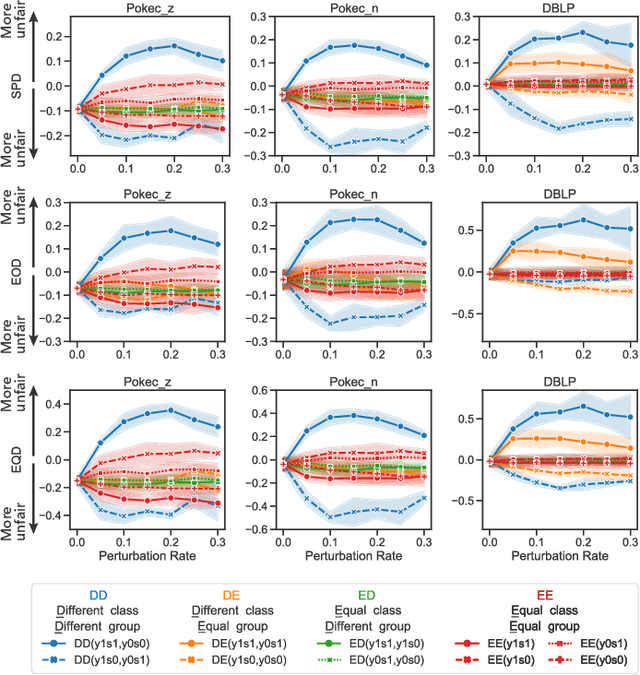
We present evidence for the existence and effectiveness of adversarial attacks on graph neural networks (GNNs) that aim to degrade fairness. These attacks can disadvantage a particular subgroup of nodes in GNN-based node classification, where nodes of the underlying network have sensitive attributes, such as race or gender. We conduct qualitative and experimental analyses explaining how adversarial link injection impairs the fairness of GNN predictions. For example, an attacker can compromise the fairness of GNN-based node classification by injecting adversarial links between nodes belonging to opposite subgroups and opposite class labels. Our experiments on empirical datasets demonstrate that adversarial fairness attacks can significantly degrade the fairness of GNN predictions (attacks are effective) with a low perturbation rate (attacks are efficient) and without a significant drop in accuracy (attacks are deceptive). This work demonstrates the vulnerability of GNN models to adversarial fairness attacks. We hope our findings raise awareness about this issue in our community and lay a foundation for the future development of GNN models that are more robust to such attacks.
ReuseKNN: Neighborhood Reuse for Privacy-Aware Recommendations
Jun 23, 2022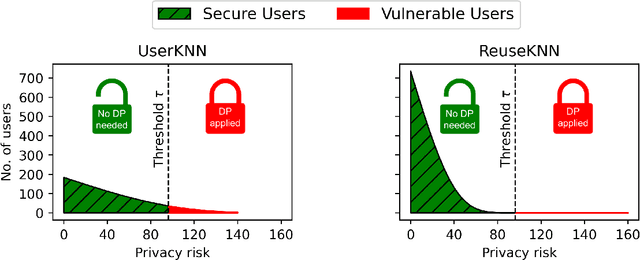

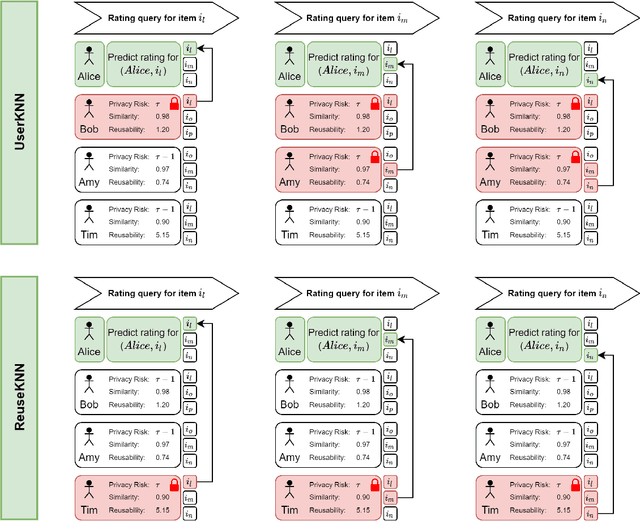
User-based KNN recommender systems (UserKNN) utilize the rating data of a target user's k nearest neighbors in the recommendation process. This, however, increases the privacy risk of the neighbors since their rating data might be exposed to other users or malicious parties. To reduce this risk, existing work applies differential privacy by adding randomness to the neighbors' ratings, which reduces the accuracy of UserKNN. In this work, we introduce ReuseKNN, a novel privacy-aware recommender system. The main idea is to identify small but highly reusable neighborhoods so that (i) only a minimal set of users requires protection with differential privacy, and (ii) most users do not need to be protected with differential privacy, since they are only rarely exploited as neighbors. In our experiments on five diverse datasets, we make two key observations: Firstly, ReuseKNN requires significantly smaller neighborhoods, and thus, fewer neighbors need to be protected with differential privacy compared to traditional UserKNN. Secondly, despite the small neighborhoods, ReuseKNN outperforms UserKNN and a fully differentially private approach in terms of accuracy. Overall, ReuseKNN's recommendation process leads to significantly less privacy risk for users than in the case of UserKNN
Position Paper on Simulating Privacy Dynamics in Recommender Systems
Sep 14, 2021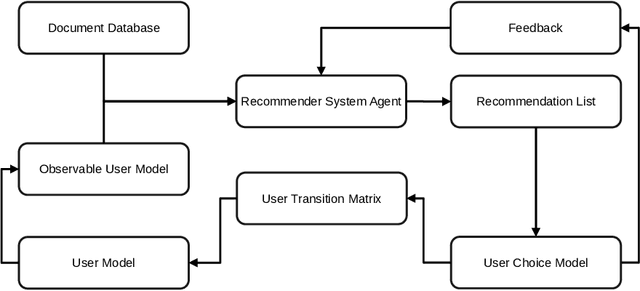
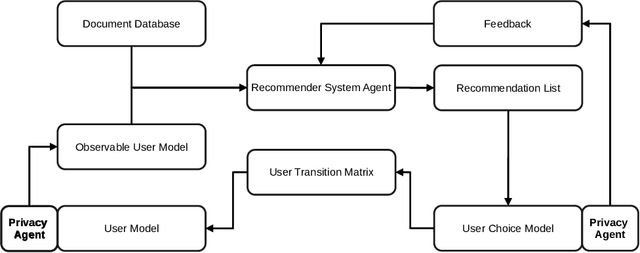
In this position paper, we discuss the merits of simulating privacy dynamics in recommender systems. We study this issue at hand from two perspectives: Firstly, we present a conceptual approach to integrate privacy into recommender system simulations, whose key elements are privacy agents. These agents can enhance users' profiles with different privacy preferences, e.g., their inclination to disclose data to the recommender system. Plus, they can protect users' privacy by guarding all actions that could be a threat to privacy. For example, agents can prohibit a user's privacy-threatening actions or apply privacy-enhancing techniques, e.g., Differential Privacy, to make actions less threatening. Secondly, we identify three critical topics for future research in privacy-aware recommender system simulations: (i) How could we model users' privacy preferences and protect users from performing any privacy-threatening actions? (ii) To what extent do privacy agents modify the users' document preferences? (iii) How do privacy preferences and privacy protections impact recommendations and privacy of others? Our conceptual privacy-aware simulation approach makes it possible to investigate the impact of privacy preferences and privacy protection on the micro-level, i.e., a single user, but also on the macro-level, i.e., all recommender system users. With this work, we hope to present perspectives on how privacy-aware simulations could be realized, such that they enable researchers to study the dynamics of privacy within a recommender system.
Analyzing Item Popularity Bias of Music Recommender Systems: Are Different Genders Equally Affected?
Aug 16, 2021

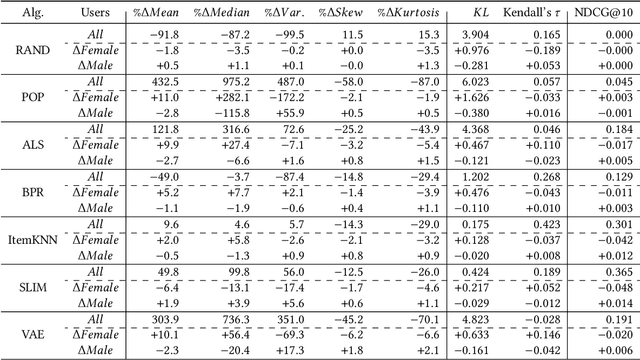
Several studies have identified discrepancies between the popularity of items in user profiles and the corresponding recommendation lists. Such behavior, which concerns a variety of recommendation algorithms, is referred to as popularity bias. Existing work predominantly adopts simple statistical measures, such as the difference of mean or median popularity, to quantify popularity bias. Moreover, it does so irrespective of user characteristics other than the inclination to popular content. In this work, in contrast, we propose to investigate popularity differences (between the user profile and recommendation list) in terms of median, a variety of statistical moments, as well as similarity measures that consider the entire popularity distributions (Kullback-Leibler divergence and Kendall's tau rank-order correlation). This results in a more detailed picture of the characteristics of popularity bias. Furthermore, we investigate whether such algorithmic popularity bias affects users of different genders in the same way. We focus on music recommendation and conduct experiments on the recently released standardized LFM-2b dataset, containing listening profiles of Last.fm users. We investigate the algorithmic popularity bias of seven common recommendation algorithms (five collaborative filtering and two baselines). Our experiments show that (1) the studied metrics provide novel insights into popularity bias in comparison with only using average differences, (2) algorithms less inclined towards popularity bias amplification do not necessarily perform worse in terms of utility (NDCG), (3) the majority of the investigated recommenders intensify the popularity bias of the female users.
Predicting Music Relistening Behavior Using the ACT-R Framework
Aug 05, 2021
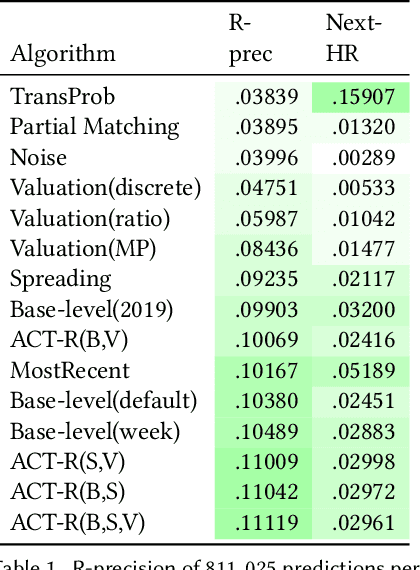
Providing suitable recommendations is of vital importance to improve the user satisfaction of music recommender systems. Here, users often listen to the same track repeatedly and appreciate recommendations of the same song multiple times. Thus, accounting for users' relistening behavior is critical for music recommender systems. In this paper, we describe a psychology-informed approach to model and predict music relistening behavior that is inspired by studies in music psychology, which relate music preferences to human memory. We adopt a well-established psychological theory of human cognition that models the operations of human memory, i.e., Adaptive Control of Thought-Rational (ACT-R). In contrast to prior work, which uses only the base-level component of ACT-R, we utilize five components of ACT-R, i.e., base-level, spreading, partial matching, valuation, and noise, to investigate the effect of five factors on music relistening behavior: (i) recency and frequency of prior exposure to tracks, (ii) co-occurrence of tracks, (iii) the similarity between tracks, (iv) familiarity with tracks, and (v) randomness in behavior. On a dataset of 1.7 million listening events from Last.fm, we evaluate the performance of our approach by sequentially predicting the next track(s) in user sessions. We find that recency and frequency of prior exposure to tracks is an effective predictor of relistening behavior. Besides, considering the co-occurrence of tracks and familiarity with tracks further improves performance in terms of R-precision. We hope that our work inspires future research on the merits of considering cognitive aspects of memory retrieval to model and predict complex user behavior.
Structack: Structure-based Adversarial Attacks on Graph Neural Networks
Jul 28, 2021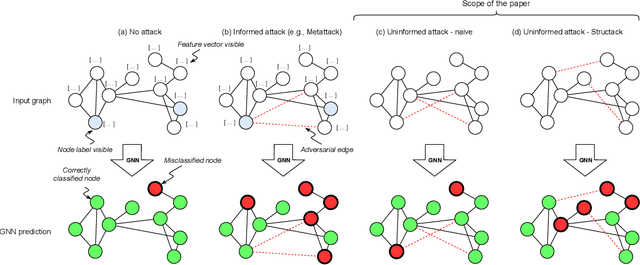
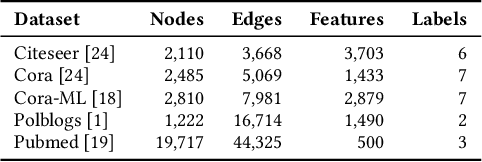
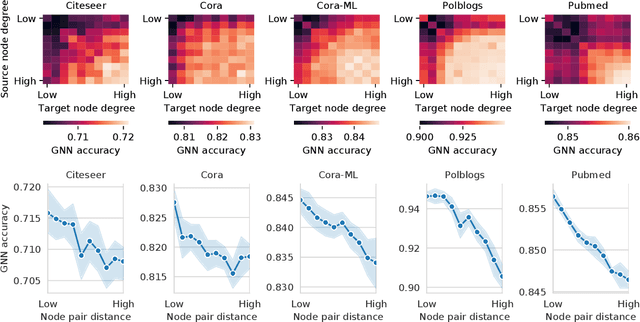

Recent work has shown that graph neural networks (GNNs) are vulnerable to adversarial attacks on graph data. Common attack approaches are typically informed, i.e. they have access to information about node attributes such as labels and feature vectors. In this work, we study adversarial attacks that are uninformed, where an attacker only has access to the graph structure, but no information about node attributes. Here the attacker aims to exploit structural knowledge and assumptions, which GNN models make about graph data. In particular, literature has shown that structural node centrality and similarity have a strong influence on learning with GNNs. Therefore, we study the impact of centrality and similarity on adversarial attacks on GNNs. We demonstrate that attackers can exploit this information to decrease the performance of GNNs by focusing on injecting links between nodes of low similarity and, surprisingly, low centrality. We show that structure-based uninformed attacks can approach the performance of informed attacks, while being computationally more efficient. With our paper, we present a new attack strategy on GNNs that we refer to as Structack. Structack can successfully manipulate the performance of GNNs with very limited information while operating under tight computational constraints. Our work contributes towards building more robust machine learning approaches on graphs.
Support the Underground: Characteristics of Beyond-Mainstream Music Listeners
Feb 24, 2021
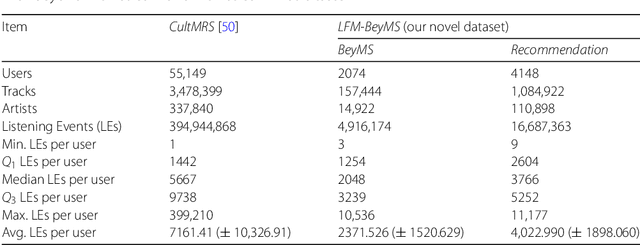
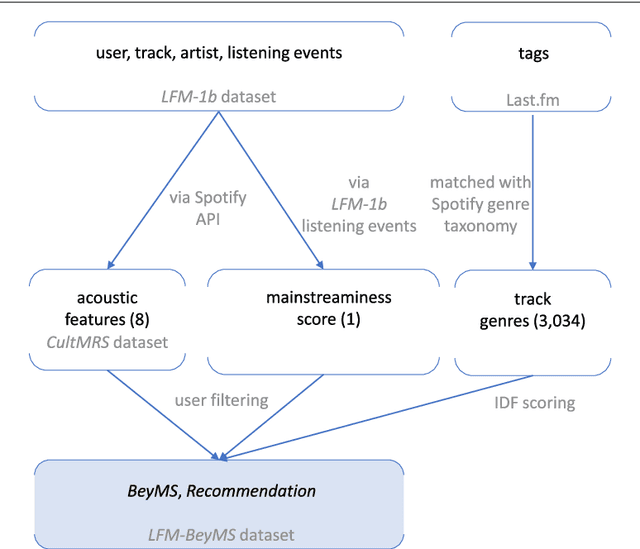

Music recommender systems have become an integral part of music streaming services such as Spotify and Last.fm to assist users navigating the extensive music collections offered by them. However, while music listeners interested in mainstream music are traditionally served well by music recommender systems, users interested in music beyond the mainstream (i.e., non-popular music) rarely receive relevant recommendations. In this paper, we study the characteristics of beyond-mainstream music and music listeners and analyze to what extent these characteristics impact the quality of music recommendations provided. Therefore, we create a novel dataset consisting of Last.fm listening histories of several thousand beyond-mainstream music listeners, which we enrich with additional metadata describing music tracks and music listeners. Our analysis of this dataset shows four subgroups within the group of beyond-mainstream music listeners that differ not only with respect to their preferred music but also with their demographic characteristics. Furthermore, we evaluate the quality of music recommendations that these subgroups are provided with four different recommendation algorithms where we find significant differences between the groups. Specifically, our results show a positive correlation between a subgroup's openness towards music listened to by members of other subgroups and recommendation accuracy. We believe that our findings provide valuable insights for developing improved user models and recommendation approaches to better serve beyond-mainstream music listeners.
Robustness of Meta Matrix Factorization Against Strict Privacy Constraints
Jan 18, 2021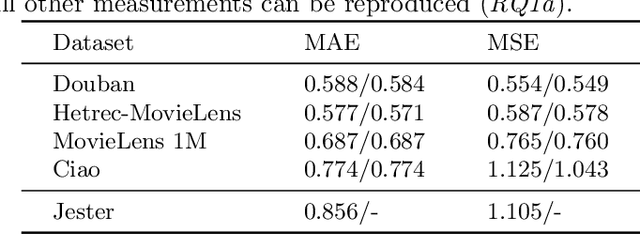
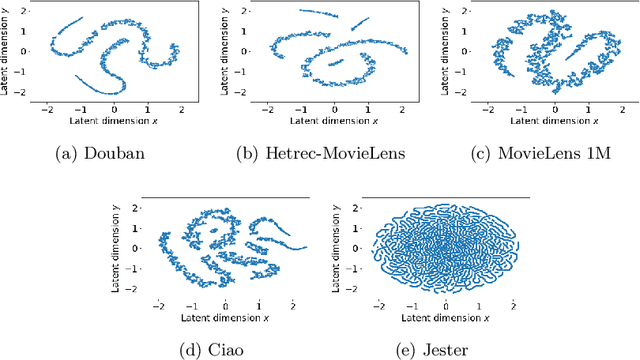
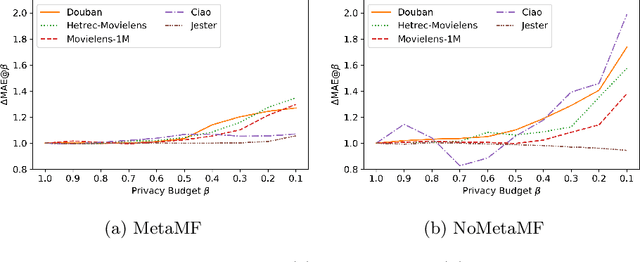
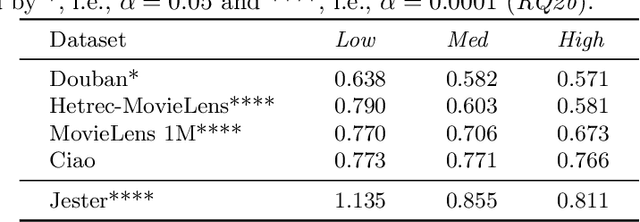
In this paper, we explore the reproducibility of MetaMF, a meta matrix factorization framework introduced by Lin et al. MetaMF employs meta learning for federated rating prediction to preserve users' privacy. We reproduce the experiments of Lin et al. on five datasets, i.e., Douban, Hetrec-MovieLens, MovieLens 1M, Ciao, and Jester. Also, we study the impact of meta learning on the accuracy of MetaMF's recommendations. Furthermore, in our work, we acknowledge that users may have different tolerances for revealing information about themselves. Hence, in a second strand of experiments, we investigate the robustness of MetaMF against strict privacy constraints. Our study illustrates that we can reproduce most of Lin et al.'s results. Plus, we provide strong evidence that meta learning is essential for MetaMF's robustness against strict privacy constraints.
On the Impact of Communities on Semi-supervised Classification Using Graph Neural Networks
Oct 30, 2020
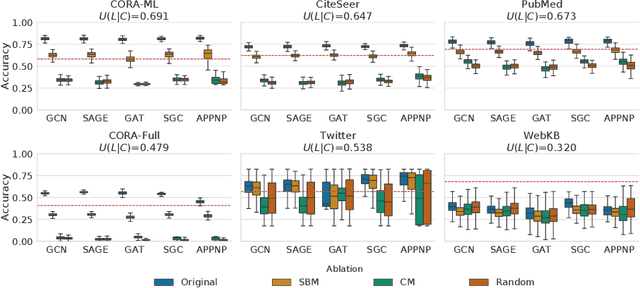
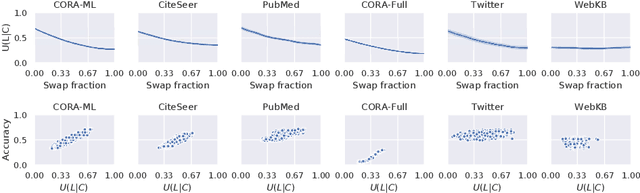
Graph Neural Networks (GNNs) are effective in many applications. Still, there is a limited understanding of the effect of common graph structures on the learning process of GNNs. In this work, we systematically study the impact of community structure on the performance of GNNs in semi-supervised node classification on graphs. Following an ablation study on six datasets, we measure the performance of GNNs on the original graphs, and the change in performance in the presence and the absence of community structure. Our results suggest that communities typically have a major impact on the learning process and classification performance. For example, in cases where the majority of nodes from one community share a single classification label, breaking up community structure results in a significant performance drop. On the other hand, for cases where labels show low correlation with communities, we find that the graph structure is rather irrelevant to the learning process, and a feature-only baseline becomes hard to beat. With our work, we provide deeper insights in the abilities and limitations of GNNs, including a set of general guidelines for model selection based on the graph structure.