 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Static and Adaptive Probing Schedules for Rapid Event Detection
Sep 10, 2015We formulate and study a fundamental search and detection problem, Schedule Optimization, motivated by a variety of real-world applications, ranging from monitoring content changes on the web, social networks, and user activities to detecting failure on large systems with many individual machines. We consider a large system consists of many nodes, where each node has its own rate of generating new events, or items. A monitoring application can probe a small number of nodes at each step, and our goal is to compute a probing schedule that minimizes the expected number of undiscovered items at the system, or equivalently, minimizes the expected time to discover a new item in the system. We study the Schedule Optimization problem both for deterministic and randomized memoryless algorithms. We provide lower bounds on the cost of an optimal schedule and construct close to optimal schedules with rigorous mathematical guarantees. Finally, we present an adaptive algorithm that starts with no prior information on the system and converges to the optimal memoryless algorithms by adapting to observed data.
Efficient Discovery of Association Rules and Frequent Itemsets through Sampling with Tight Performance Guarantees
Feb 22, 2013
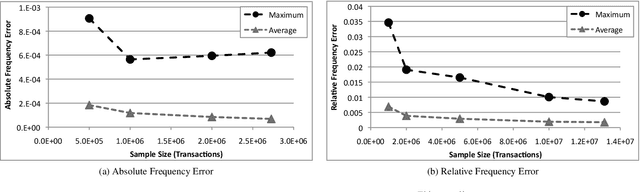
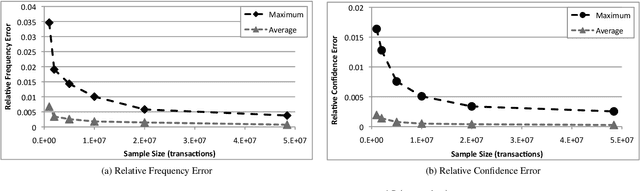

The tasks of extracting (top-$K$) Frequent Itemsets (FI's) and Association Rules (AR's) are fundamental primitives in data mining and database applications. Exact algorithms for these problems exist and are widely used, but their running time is hindered by the need of scanning the entire dataset, possibly multiple times. High quality approximations of FI's and AR's are sufficient for most practical uses, and a number of recent works explored the application of sampling for fast discovery of approximate solutions to the problems. However, these works do not provide satisfactory performance guarantees on the quality of the approximation, due to the difficulty of bounding the probability of under- or over-sampling any one of an unknown number of frequent itemsets. In this work we circumvent this issue by applying the statistical concept of \emph{Vapnik-Chervonenkis (VC) dimension} to develop a novel technique for providing tight bounds on the sample size that guarantees approximation within user-specified parameters. Our technique applies both to absolute and to relative approximations of (top-$K$) FI's and AR's. The resulting sample size is linearly dependent on the VC-dimension of a range space associated with the dataset to be mined. The main theoretical contribution of this work is a proof that the VC-dimension of this range space is upper bounded by an easy-to-compute characteristic quantity of the dataset which we call \emph{d-index}, and is the maximum integer $d$ such that the dataset contains at least $d$ transactions of length at least $d$ such that no one of them is a superset of or equal to another. We show that this bound is strict for a large class of datasets.
A Clustering Approach to Solving Large Stochastic Matching Problems
Jan 10, 2013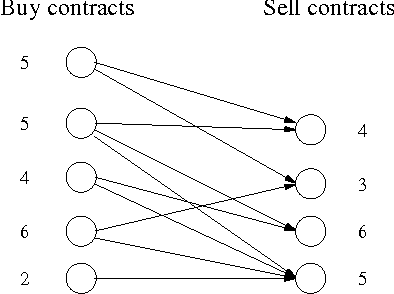
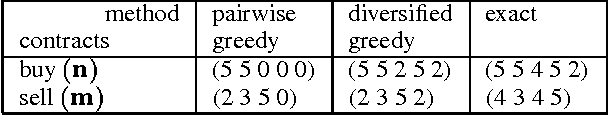
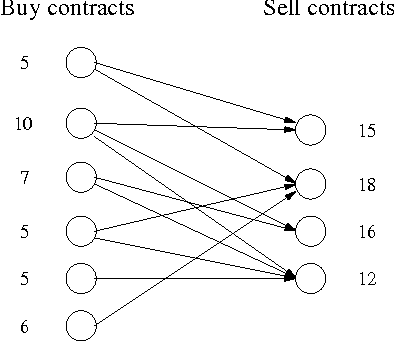
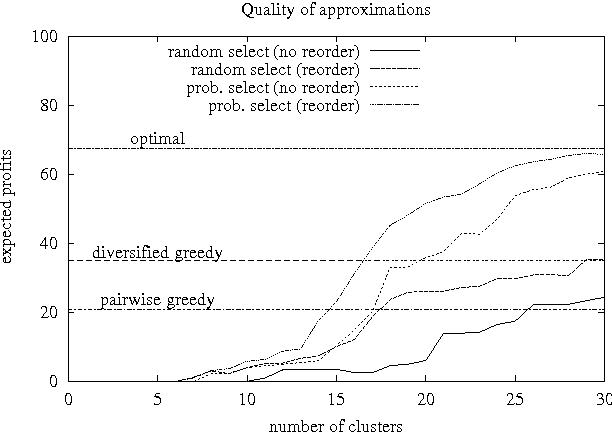
In this work we focus on efficient heuristics for solving a class of stochastic planning problems that arise in a variety of business, investment, and industrial applications. The problem is best described in terms of future buy and sell contracts. By buying less reliable, but less expensive, buy (supply) contracts, a company or a trader can cover a position of more reliable and more expensive sell contracts. The goal is to maximize the expected net gain (profit) by constructing a dose to optimum portfolio out of the available buy and sell contracts. This stochastic planning problem can be formulated as a two-stage stochastic linear programming problem with recourse. However, this formalization leads to solutions that are exponential in the number of possible failure combinations. Thus, this approach is not feasible for large scale problems. In this work we investigate heuristic approximation techniques alleviating the efficiency problem. We primarily focus on the clustering approach and devise heuristics for finding clusterings leading to good approximations. We illustrate the quality and feasibility of the approach through experimental data.
The VC-Dimension of Queries and Selectivity Estimation Through Sampling
Aug 11, 2011

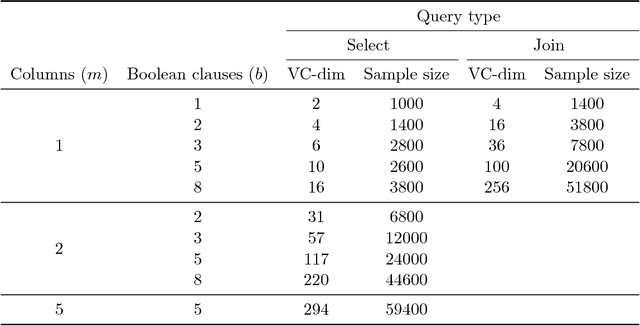
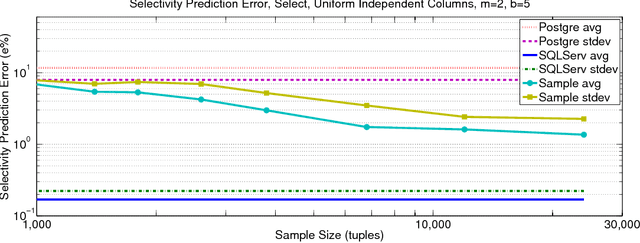
We develop a novel method, based on the statistical concept of the Vapnik-Chervonenkis dimension, to evaluate the selectivity (output cardinality) of SQL queries - a crucial step in optimizing the execution of large scale database and data-mining operations. The major theoretical contribution of this work, which is of independent interest, is an explicit bound to the VC-dimension of a range space defined by all possible outcomes of a collection (class) of queries. We prove that the VC-dimension is a function of the maximum number of Boolean operations in the selection predicate and of the maximum number of select and join operations in any individual query in the collection, but it is neither a function of the number of queries in the collection nor of the size (number of tuples) of the database. We leverage on this result and develop a method that, given a class of queries, builds a concise random sample of a database, such that with high probability the execution of any query in the class on the sample provides an accurate estimate for the selectivity of the query on the original large database. The error probability holds simultaneously for the selectivity estimates of all queries in the collection, thus the same sample can be used to evaluate the selectivity of multiple queries, and the sample needs to be refreshed only following major changes in the database. The sample representation computed by our method is typically sufficiently small to be stored in main memory. We present extensive experimental results, validating our theoretical analysis and demonstrating the advantage of our technique when compared to complex selectivity estimation techniques used in PostgreSQL and the Microsoft SQL Server.
Multi-Armed Bandits in Metric Spaces
Sep 29, 2008In a multi-armed bandit problem, an online algorithm chooses from a set of strategies in a sequence of trials so as to maximize the total payoff of the chosen strategies. While the performance of bandit algorithms with a small finite strategy set is quite well understood, bandit problems with large strategy sets are still a topic of very active investigation, motivated by practical applications such as online auctions and web advertisement. The goal of such research is to identify broad and natural classes of strategy sets and payoff functions which enable the design of efficient solutions. In this work we study a very general setting for the multi-armed bandit problem in which the strategies form a metric space, and the payoff function satisfies a Lipschitz condition with respect to the metric. We refer to this problem as the "Lipschitz MAB problem". We present a complete solution for the multi-armed problem in this setting. That is, for every metric space (L,X) we define an isometry invariant which bounds from below the performance of Lipschitz MAB algorithms for X, and we present an algorithm which comes arbitrarily close to meeting this bound. Furthermore, our technique gives even better results for benign payoff functions.