 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Reasonable Parrots: Why Large Language Models Should Argue with Us by Design
May 08, 2025

In this position paper, we advocate for the development of conversational technology that is inherently designed to support and facilitate argumentative processes. We argue that, at present, large language models (LLMs) are inadequate for this purpose, and we propose an ideal technology design aimed at enhancing argumentative skills. This involves re-framing LLMs as tools to exercise our critical thinking rather than replacing them. We introduce the concept of 'reasonable parrots' that embody the fundamental principles of relevance, responsibility, and freedom, and that interact through argumentative dialogical moves. These principles and moves arise out of millennia of work in argumentation theory and should serve as the starting point for LLM-based technology that incorporates basic principles of argumentation.
Multitask Instruction-based Prompting for Fallacy Recognition
Jan 24, 2023Fallacies are used as seemingly valid arguments to support a position and persuade the audience about its validity. Recognizing fallacies is an intrinsically difficult task both for humans and machines. Moreover, a big challenge for computational models lies in the fact that fallacies are formulated differently across the datasets with differences in the input format (e.g., question-answer pair, sentence with fallacy fragment), genre (e.g., social media, dialogue, news), as well as types and number of fallacies (from 5 to 18 types per dataset). To move towards solving the fallacy recognition task, we approach these differences across datasets as multiple tasks and show how instruction-based prompting in a multitask setup based on the T5 model improves the results against approaches built for a specific dataset such as T5, BERT or GPT-3. We show the ability of this multitask prompting approach to recognize 28 unique fallacies across domains and genres and study the effect of model size and prompt choice by analyzing the per-class (i.e., fallacy type) results. Finally, we analyze the effect of annotation quality on model performance, and the feasibility of complementing this approach with external knowledge.
* In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 8172 - 8187
Interpreting Verbal Irony: Linguistic Strategies and the Connection to the Type of Semantic Incongruity
Nov 05, 2019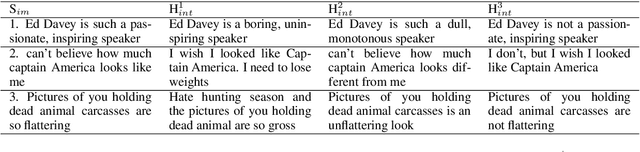
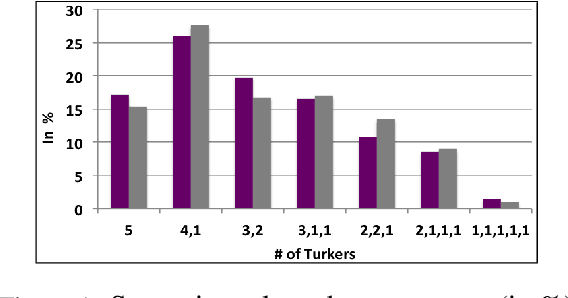
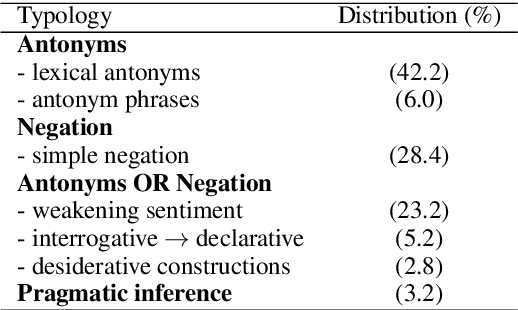
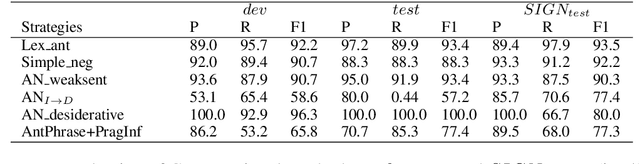
Human communication often involves the use of verbal irony or sarcasm, where the speakers usually mean the opposite of what they say. To better understand how verbal irony is expressed by the speaker and interpreted by the hearer we conduct a crowdsourcing task: given an utterance expressing verbal irony, users are asked to verbalize their interpretation of the speaker's ironic message. We propose a typology of linguistic strategies for verbal irony interpretation and link it to various theoretical linguistic frameworks. We design computational models to capture these strategies and present empirical studies aimed to answer three questions: (1) what is the distribution of linguistic strategies used by hearers to interpret ironic messages?; (2) do hearers adopt similar strategies for interpreting the speaker's ironic intent?; and (3) does the type of semantic incongruity in the ironic message (explicit vs. implicit) influence the choice of interpretation strategies by the hearers?
ChangeMyView Through Concessions: Do Concessions Increase Persuasion?
Jun 08, 2018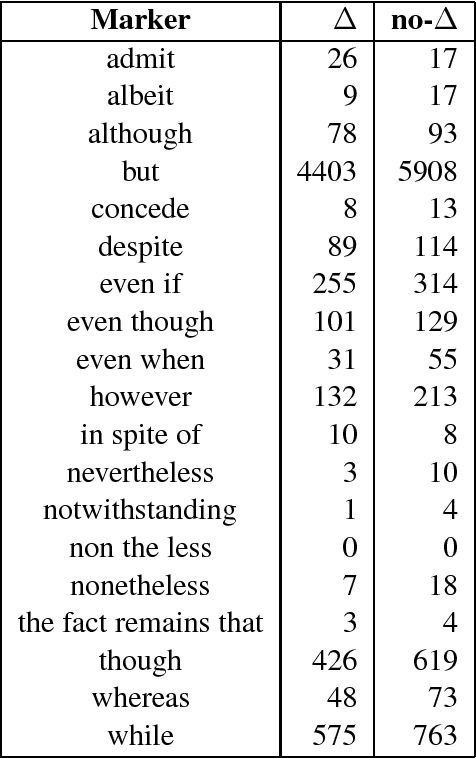

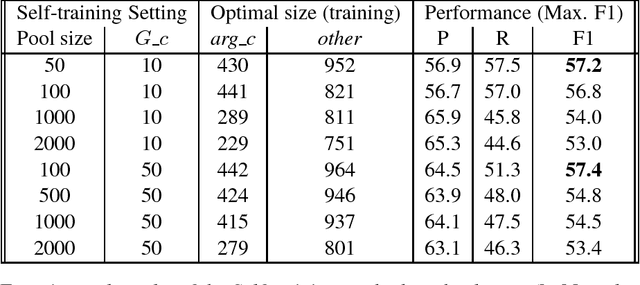
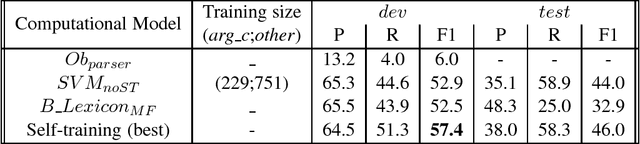
In discourse studies concessions are considered among those argumentative strategies that increase persuasion. We aim to empirically test this hypothesis by calculating the distribution of argumentative concessions in persuasive vs. non-persuasive comments from the ChangeMyView subreddit. This constitutes a challenging task since concessions are not always part of an argument. Drawing from a theoretically-informed typology of concessions, we conduct an annotation task to label a set of polysemous lexical markers as introducing an argumentative concession or not and we observe their distribution in threads that achieved and did not achieve persuasion. For the annotation, we used both expert and novice annotators. With the ultimate goal of conducting the study on large datasets, we present a self-training method to automatically identify argumentative concessions using linguistically motivated features. We achieve a moderate F1 of 57.4% on the development set and 46.0% on the test set via the self-training method. These results are comparable to state of the art results on similar tasks of identifying explicit discourse connective types from the Penn Discourse Treebank. Our findings from the manual labeling and the classification experiments indicate that the type of argumentative concessions we investigated is almost equally likely to be used in winning and losing arguments from the ChangeMyView dataset. While this result seems to contradict theoretical assumptions, we provide some reasons for this discrepancy related to the ChangeMyView subreddit.