 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrosslingual Generalization through Multitask Finetuning
Nov 03, 2022Multitask prompted finetuning (MTF) has been shown to help large language models generalize to new tasks in a zero-shot setting, but so far explorations of MTF have focused on English data and models. We apply MTF to the pretrained multilingual BLOOM and mT5 model families to produce finetuned variants called BLOOMZ and mT0. We find finetuning large multilingual language models on English tasks with English prompts allows for task generalization to non-English languages that appear only in the pretraining corpus. Finetuning on multilingual tasks with English prompts further improves performance on English and non-English tasks leading to various state-of-the-art zero-shot results. We also investigate finetuning on multilingual tasks with prompts that have been machine-translated from English to match the language of each dataset. We find training on these machine-translated prompts leads to better performance on human-written prompts in the respective languages. Surprisingly, we find models are capable of zero-shot generalization to tasks in languages they have never intentionally seen. We conjecture that the models are learning higher-level capabilities that are both task- and language-agnostic. In addition, we introduce xP3, a composite of supervised datasets in 46 languages with English and machine-translated prompts. Our code, datasets and models are publicly available at https://github.com/bigscience-workshop/xmtf.
A General Framework for Auditing Differentially Private Machine Learning
Oct 16, 2022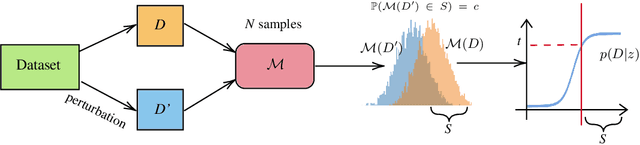

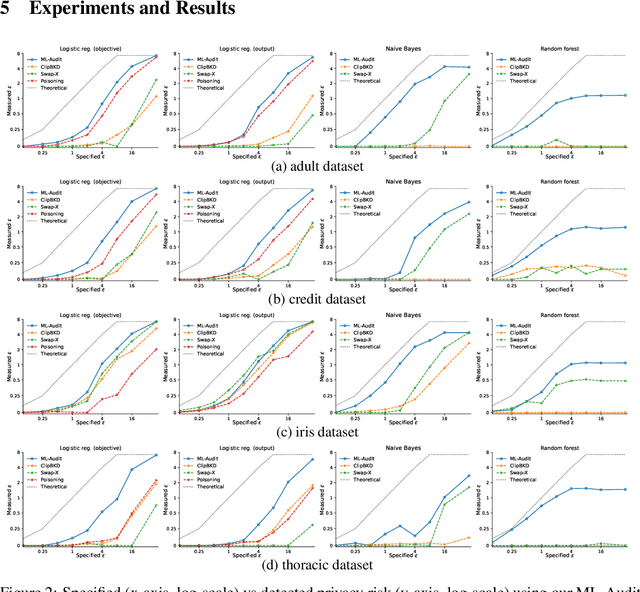
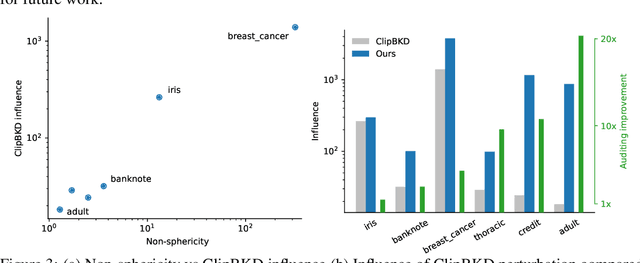
We present a framework to statistically audit the privacy guarantee conferred by a differentially private machine learner in practice. While previous works have taken steps toward evaluating privacy loss through poisoning attacks or membership inference, they have been tailored to specific models or have demonstrated low statistical power. Our work develops a general methodology to empirically evaluate the privacy of differentially private machine learning implementations, combining improved privacy search and verification methods with a toolkit of influence-based poisoning attacks. We demonstrate significantly improved auditing power over previous approaches on a variety of models including logistic regression, Naive Bayes, and random forest. Our method can be used to detect privacy violations due to implementation errors or misuse. When violations are not present, it can aid in understanding the amount of information that can be leaked from a given dataset, algorithm, and privacy specification.
Improving Out-of-Distribution Detection via Epistemic Uncertainty Adversarial Training
Sep 09, 2022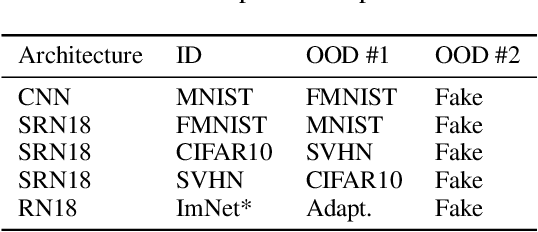
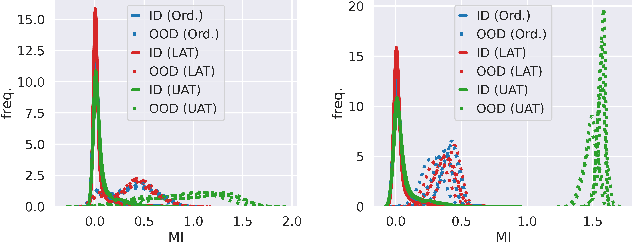
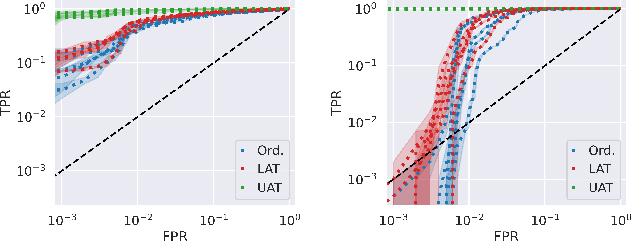
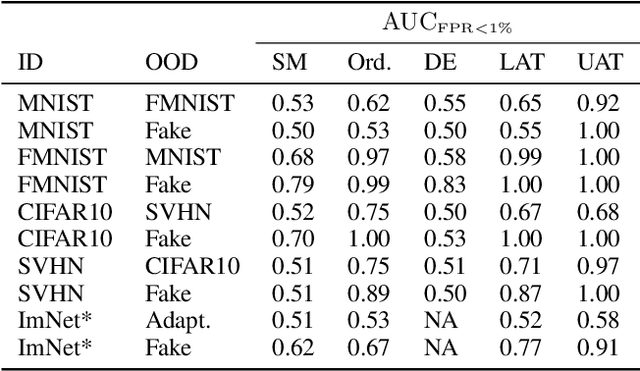
The quantification of uncertainty is important for the adoption of machine learning, especially to reject out-of-distribution (OOD) data back to human experts for review. Yet progress has been slow, as a balance must be struck between computational efficiency and the quality of uncertainty estimates. For this reason many use deep ensembles of neural networks or Monte Carlo dropout for reasonable uncertainty estimates at relatively minimal compute and memory. Surprisingly, when we focus on the real-world applicable constraint of $\leq 1\%$ false positive rate (FPR), prior methods fail to reliably detect OOD samples as such. Notably, even Gaussian random noise fails to trigger these popular OOD techniques. We help to alleviate this problem by devising a simple adversarial training scheme that incorporates an attack of the epistemic uncertainty predicted by the dropout ensemble. We demonstrate this method improves OOD detection performance on standard data (i.e., not adversarially crafted), and improves the standardized partial AUC from near-random guessing performance to $\geq 0.75$.
Deploying Convolutional Networks on Untrusted Platforms Using 2D Holographic Reduced Representations
Jun 13, 2022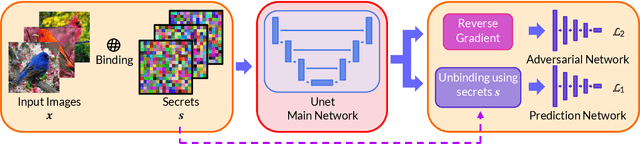
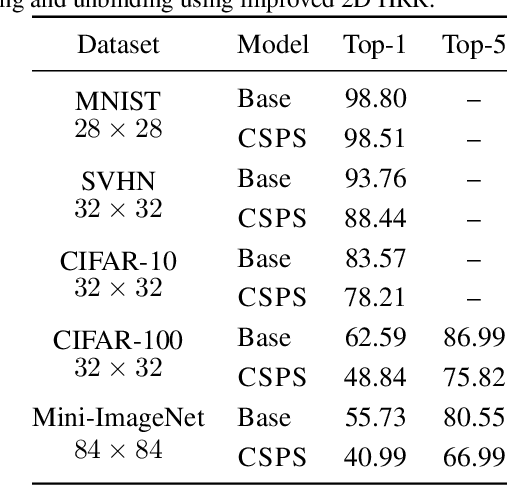
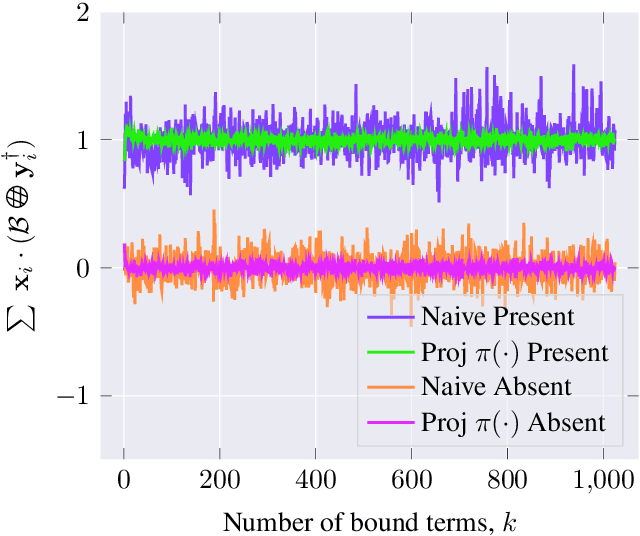

Due to the computational cost of running inference for a neural network, the need to deploy the inferential steps on a third party's compute environment or hardware is common. If the third party is not fully trusted, it is desirable to obfuscate the nature of the inputs and outputs, so that the third party can not easily determine what specific task is being performed. Provably secure protocols for leveraging an untrusted party exist but are too computational demanding to run in practice. We instead explore a different strategy of fast, heuristic security that we call Connectionist Symbolic Pseudo Secrets. By leveraging Holographic Reduced Representations (HRR), we create a neural network with a pseudo-encryption style defense that empirically shows robustness to attack, even under threat models that unrealistically favor the adversary.
Neural Bregman Divergences for Distance Learning
Jun 09, 2022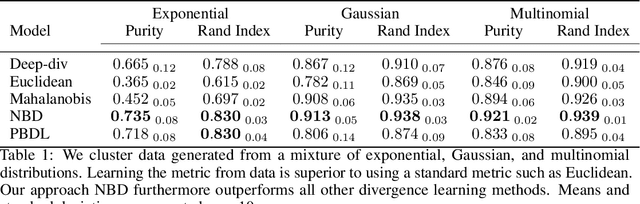
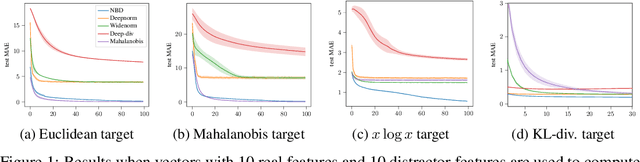
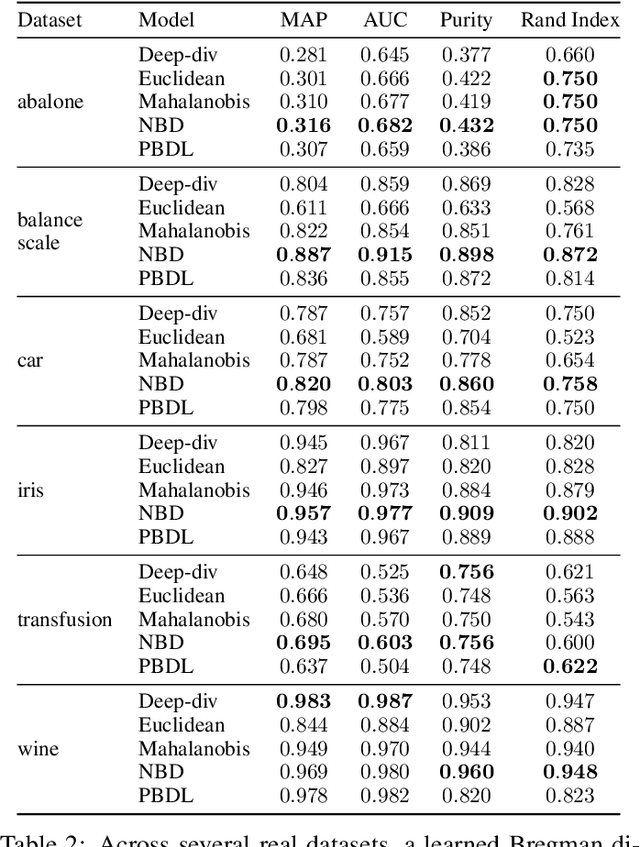
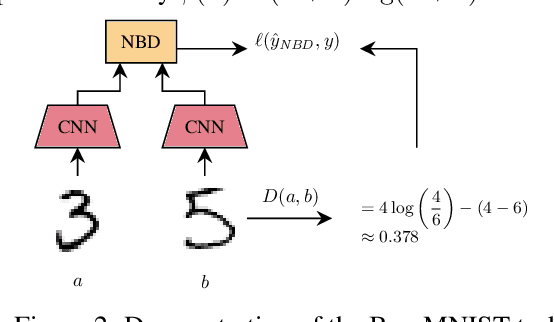
Many metric learning tasks, such as triplet learning, nearest neighbor retrieval, and visualization, are treated primarily as embedding tasks where the ultimate metric is some variant of the Euclidean distance (e.g., cosine or Mahalanobis), and the algorithm must learn to embed points into the pre-chosen space. The study of non-Euclidean geometries or appropriateness is often not explored, which we believe is due to a lack of tools for learning non-Euclidean measures of distance. Under the belief that the use of asymmetric methods in particular have lacked sufficient study, we propose a new approach to learning arbitrary Bergman divergences in a differentiable manner via input convex neural networks. Over a set of both new and previously studied tasks, including asymmetric regression, ranking, and clustering, we demonstrate that our method more faithfully learns divergences than prior Bregman learning approaches. In doing so we obtain the first method for learning neural Bregman divergences and with it inherit the many nice mathematical properties of Bregman divergences, providing the foundation and tooling for better developing and studying asymmetric distance learning.
Marvolo: Programmatic Data Augmentation for Practical ML-Driven Malware Detection
Jun 07, 2022


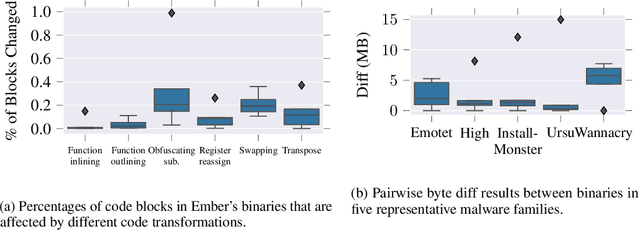
Data augmentation has been rare in the cyber security domain due to technical difficulties in altering data in a manner that is semantically consistent with the original data. This shortfall is particularly onerous given the unique difficulty of acquiring benign and malicious training data that runs into copyright restrictions, and that institutions like banks and governments receive targeted malware that will never exist in large quantities. We present MARVOLO, a binary mutator that programmatically grows malware (and benign) datasets in a manner that boosts the accuracy of ML-driven malware detectors. MARVOLO employs semantics-preserving code transformations that mimic the alterations that malware authors and defensive benign developers routinely make in practice , allowing us to generate meaningful augmented data. Crucially, semantics-preserving transformations also enable MARVOLO to safely propagate labels from original to newly-generated data samples without mandating expensive reverse engineering of binaries. Further, MARVOLO embeds several key optimizations that keep costs low for practitioners by maximizing the density of diverse data samples generated within a given time (or resource) budget. Experiments using wide-ranging commercial malware datasets and a recent ML-driven malware detector show that MARVOLO boosts accuracies by up to 5%, while operating on only a small fraction (15%) of the potential input binaries.
VQGAN-CLIP: Open Domain Image Generation and Editing with Natural Language Guidance
Apr 18, 2022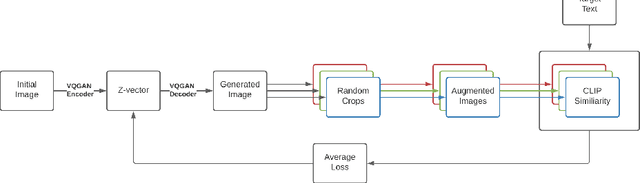
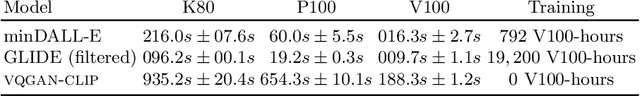


Generating and editing images from open domain text prompts is a challenging task that heretofore has required expensive and specially trained models. We demonstrate a novel methodology for both tasks which is capable of producing images of high visual quality from text prompts of significant semantic complexity without any training by using a multimodal encoder to guide image generations. We demonstrate on a variety of tasks how using CLIP [37] to guide VQGAN [11] produces higher visual quality outputs than prior, less flexible approaches like DALL-E [38], GLIDE [33] and Open-Edit [24], despite not being trained for the tasks presented. Our code is available in a public repository.
A Siren Song of Open Source Reproducibility
Apr 09, 2022As reproducibility becomes a greater concern, conferences have largely converged to a strategy of asking reviewers to indicate whether code was attached to a submission. This is part of a larger trend of taking action based on assumed ideals, without studying if those actions will yield the desired outcome. Our argument is that this focus on code for replication is misguided if we want to improve the state of reproducible research. This focus can be harmful -- we should not force code to be submitted. There is a lack of evidence for effective actions taken by conferences to encourage and reward reproducibility. We argue that venues must take more action to advance reproducible machine learning research today.
Does the Market of Citations Reward Reproducible Work?
Apr 08, 2022
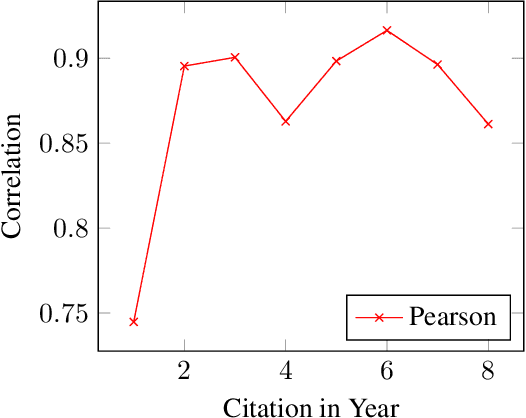
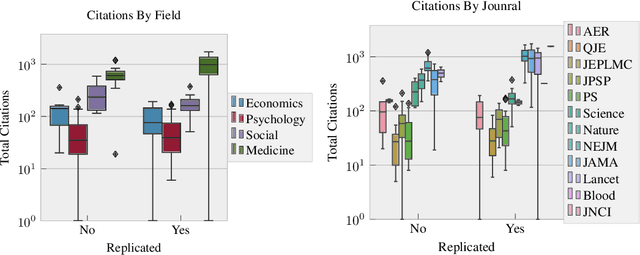
The field of bibliometrics, studying citations and behavior, is critical to the discussion of reproducibility. Citations are one of the primary incentive and reward systems for academic work, and so we desire to know if this incentive rewards reproducible work. Yet to the best of our knowledge, only one work has attempted to look at this combined space, concluding that non-reproducible work is more highly cited. We show that answering this question is more challenging than first proposed, and subtle issues can inhibit a robust conclusion. To make inferences with more robust behavior, we propose a hierarchical Bayesian model that incorporates the citation rate over time, rather than the total number of citations after a fixed amount of time. In doing so we show that, under current evidence the answer is more likely that certain fields of study such as Medicine and Machine Learning (ML) do correlate reproducible works with more citations, but other fields appear to have no relationship. Further, we find that making code available and thoroughly referencing prior works appear to also positively correlate with increased citations. Our code and data can be found at https://github.com/EdwardRaff/ReproducibleCitations .
Intelligent Sight and Sound: A Chronic Cancer Pain Dataset
Apr 07, 2022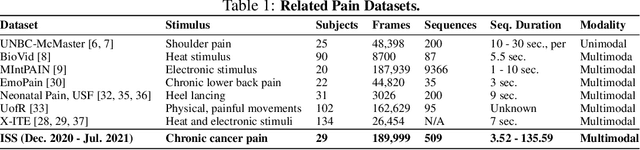
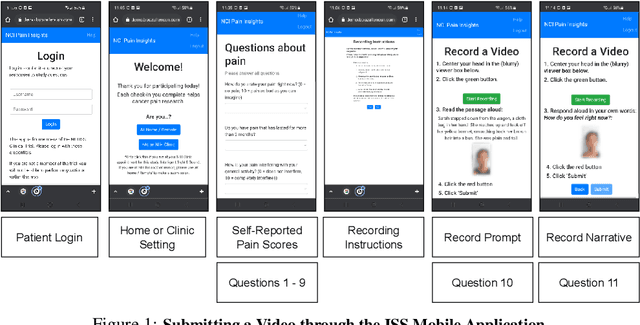
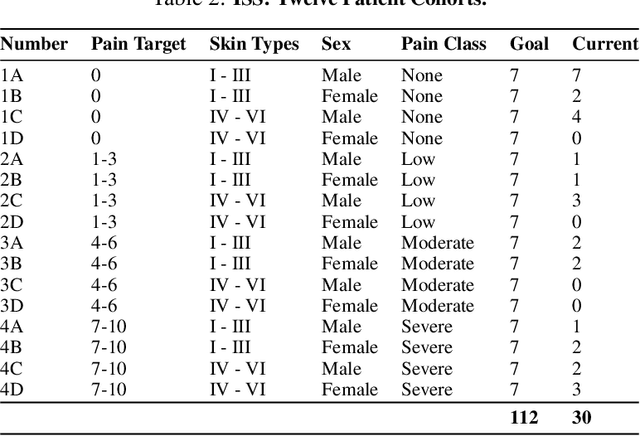

Cancer patients experience high rates of chronic pain throughout the treatment process. Assessing pain for this patient population is a vital component of psychological and functional well-being, as it can cause a rapid deterioration of quality of life. Existing work in facial pain detection often have deficiencies in labeling or methodology that prevent them from being clinically relevant. This paper introduces the first chronic cancer pain dataset, collected as part of the Intelligent Sight and Sound (ISS) clinical trial, guided by clinicians to help ensure that model findings yield clinically relevant results. The data collected to date consists of 29 patients, 509 smartphone videos, 189,999 frames, and self-reported affective and activity pain scores adopted from the Brief Pain Inventory (BPI). Using static images and multi-modal data to predict self-reported pain levels, early models show significant gaps between current methods available to predict pain today, with room for improvement. Due to the especially sensitive nature of the inherent Personally Identifiable Information (PII) of facial images, the dataset will be released under the guidance and control of the National Institutes of Health (NIH).