 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Do Machine Learning Researchers Mean by "Reproducible"?
Dec 05, 2024The concern that Artificial Intelligence (AI) and Machine Learning (ML) are entering a "reproducibility crisis" has spurred significant research in the past few years. Yet with each paper, it is often unclear what someone means by "reproducibility". Our work attempts to clarify the scope of "reproducibility" as displayed by the community at large. In doing so, we propose to refine the research to eight general topic areas. In this light, we see that each of these areas contains many works that do not advertise themselves as being about "reproducibility", in part because they go back decades before the matter came to broader attention.
Living off the Analyst: Harvesting Features from Yara Rules for Malware Detection
Nov 27, 2024



A strategy used by malicious actors is to "live off the land," where benign systems and tools already available on a victim's systems are used and repurposed for the malicious actor's intent. In this work, we ask if there is a way for anti-virus developers to similarly re-purpose existing work to improve their malware detection capability. We show that this is plausible via YARA rules, which use human-written signatures to detect specific malware families, functionalities, or other markers of interest. By extracting sub-signatures from publicly available YARA rules, we assembled a set of features that can more effectively discriminate malicious samples from benign ones. Our experiments demonstrate that these features add value beyond traditional features on the EMBER 2018 dataset. Manual analysis of the added sub-signatures shows a power-law behavior in a combination of features that are specific and unique, as well as features that occur often. A prior expectation may be that the features would be limited in being overly specific to unique malware families. This behavior is observed, and is apparently useful in practice. In addition, we also find sub-signatures that are dual-purpose (e.g., detecting virtual machine environments) or broadly generic (e.g., DLL imports).
Stabilizing Linear Passive-Aggressive Online Learning with Weighted Reservoir Sampling
Oct 31, 2024



Online learning methods, like the seminal Passive-Aggressive (PA) classifier, are still highly effective for high-dimensional streaming data, out-of-core processing, and other throughput-sensitive applications. Many such algorithms rely on fast adaptation to individual errors as a key to their convergence. While such algorithms enjoy low theoretical regret, in real-world deployment they can be sensitive to individual outliers that cause the algorithm to over-correct. When such outliers occur at the end of the data stream, this can cause the final solution to have unexpectedly low accuracy. We design a weighted reservoir sampling (WRS) approach to obtain a stable ensemble model from the sequence of solutions without requiring additional passes over the data, hold-out sets, or a growing amount of memory. Our key insight is that good solutions tend to be error-free for more iterations than bad solutions, and thus, the number of passive rounds provides an estimate of a solution's relative quality. Our reservoir thus contains $K$ previous intermediate weight vectors with high survival times. We demonstrate our WRS approach on the Passive-Aggressive Classifier (PAC) and First-Order Sparse Online Learning (FSOL), where our method consistently and significantly outperforms the unmodified approach. We show that the risk of the ensemble classifier is bounded with respect to the regret of the underlying online learning method.
A Walsh Hadamard Derived Linear Vector Symbolic Architecture
Oct 30, 2024



Vector Symbolic Architectures (VSAs) are one approach to developing Neuro-symbolic AI, where two vectors in $\mathbb{R}^d$ are `bound' together to produce a new vector in the same space. VSAs support the commutativity and associativity of this binding operation, along with an inverse operation, allowing one to construct symbolic-style manipulations over real-valued vectors. Most VSAs were developed before deep learning and automatic differentiation became popular and instead focused on efficacy in hand-designed systems. In this work, we introduce the Hadamard-derived linear Binding (HLB), which is designed to have favorable computational efficiency, and efficacy in classic VSA tasks, and perform well in differentiable systems. Code is available at https://github.com/FutureComputing4AI/Hadamard-derived-Linear-Binding
Is Function Similarity Over-Engineered? Building a Benchmark
Oct 30, 2024Binary analysis is a core component of many critical security tasks, including reverse engineering, malware analysis, and vulnerability detection. Manual analysis is often time-consuming, but identifying commonly-used or previously-seen functions can reduce the time it takes to understand a new file. However, given the complexity of assembly, and the NP-hard nature of determining function equivalence, this task is extremely difficult. Common approaches often use sophisticated disassembly and decompilation tools, graph analysis, and other expensive pre-processing steps to perform function similarity searches over some corpus. In this work, we identify a number of discrepancies between the current research environment and the underlying application need. To remedy this, we build a new benchmark, REFuSE-Bench, for binary function similarity detection consisting of high-quality datasets and tests that better reflect real-world use cases. In doing so, we address issues like data duplication and accurate labeling, experiment with real malware, and perform the first serious evaluation of ML binary function similarity models on Windows data. Our benchmark reveals that a new, simple basline, one which looks at only the raw bytes of a function, and requires no disassembly or other pre-processing, is able to achieve state-of-the-art performance in multiple settings. Our findings challenge conventional assumptions that complex models with highly-engineered features are being used to their full potential, and demonstrate that simpler approaches can provide significant value.
Position: Challenges and Opportunities for Differential Privacy in the U.S. Federal Government
Oct 21, 2024In this article, we seek to elucidate challenges and opportunities for differential privacy within the federal government setting, as seen by a team of differential privacy researchers, privacy lawyers, and data scientists working closely with the U.S. government. After introducing differential privacy, we highlight three significant challenges which currently restrict the use of differential privacy in the U.S. government. We then provide two examples where differential privacy can enhance the capabilities of government agencies. The first example highlights how the quantitative nature of differential privacy allows policy security officers to release multiple versions of analyses with different levels of privacy. The second example, which we believe is a novel realization, indicates that differential privacy can be used to improve staffing efficiency in classified applications. We hope that this article can serve as a nontechnical resource which can help frame future action from the differential privacy community, privacy regulators, security officers, and lawmakers.
Neural Normalized Compression Distance and the Disconnect Between Compression and Classification
Oct 20, 2024



It is generally well understood that predictive classification and compression are intrinsically related concepts in information theory. Indeed, many deep learning methods are explained as learning a kind of compression, and that better compression leads to better performance. We interrogate this hypothesis via the Normalized Compression Distance (NCD), which explicitly relies on compression as the means of measuring similarity between sequences and thus enables nearest-neighbor classification. By turning popular large language models (LLMs) into lossless compressors, we develop a Neural NCD and compare LLMs to classic general-purpose algorithms like gzip. In doing so, we find that classification accuracy is not predictable by compression rate alone, among other empirical aberrations not predicted by current understanding. Our results imply that our intuition on what it means for a neural network to ``compress'' and what is needed for effective classification are not yet well understood.
Feature Selection from Differentially Private Correlations
Aug 20, 2024



Data scientists often seek to identify the most important features in high-dimensional datasets. This can be done through $L_1$-regularized regression, but this can become inefficient for very high-dimensional datasets. Additionally, high-dimensional regression can leak information about individual datapoints in a dataset. In this paper, we empirically evaluate the established baseline method for feature selection with differential privacy, the two-stage selection technique, and show that it is not stable under sparsity. This makes it perform poorly on real-world datasets, so we consider a different approach to private feature selection. We employ a correlations-based order statistic to choose important features from a dataset and privatize them to ensure that the results do not leak information about individual datapoints. We find that our method significantly outperforms the established baseline for private feature selection on many datasets.
More Options for Prelabor Rupture of Membranes, A Bayesian Analysis
Aug 20, 2024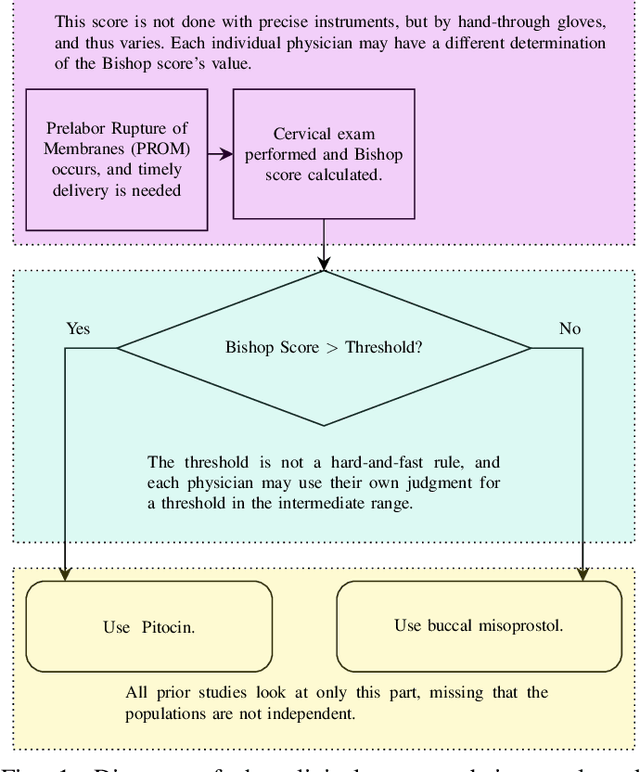
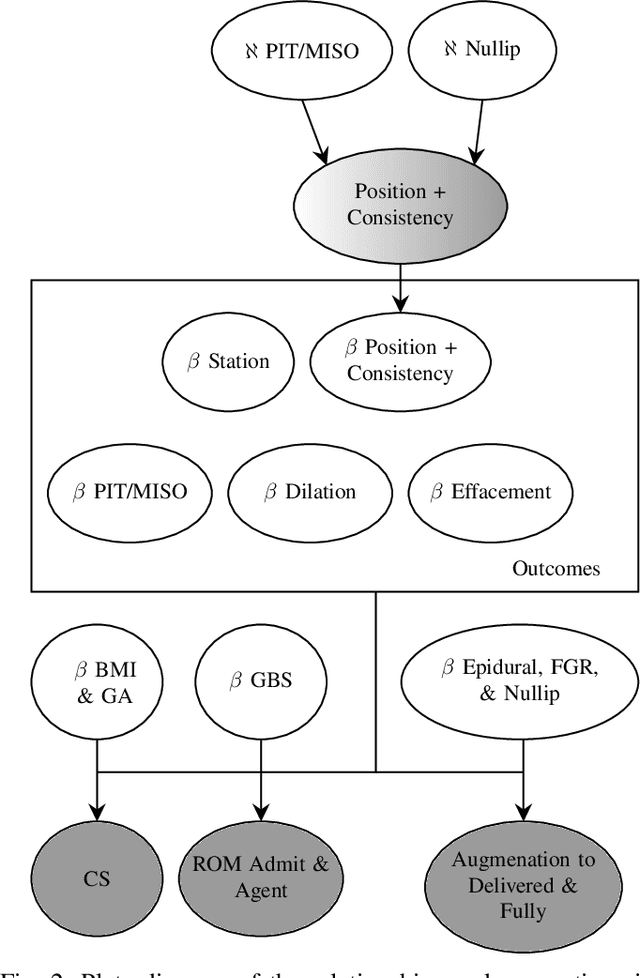
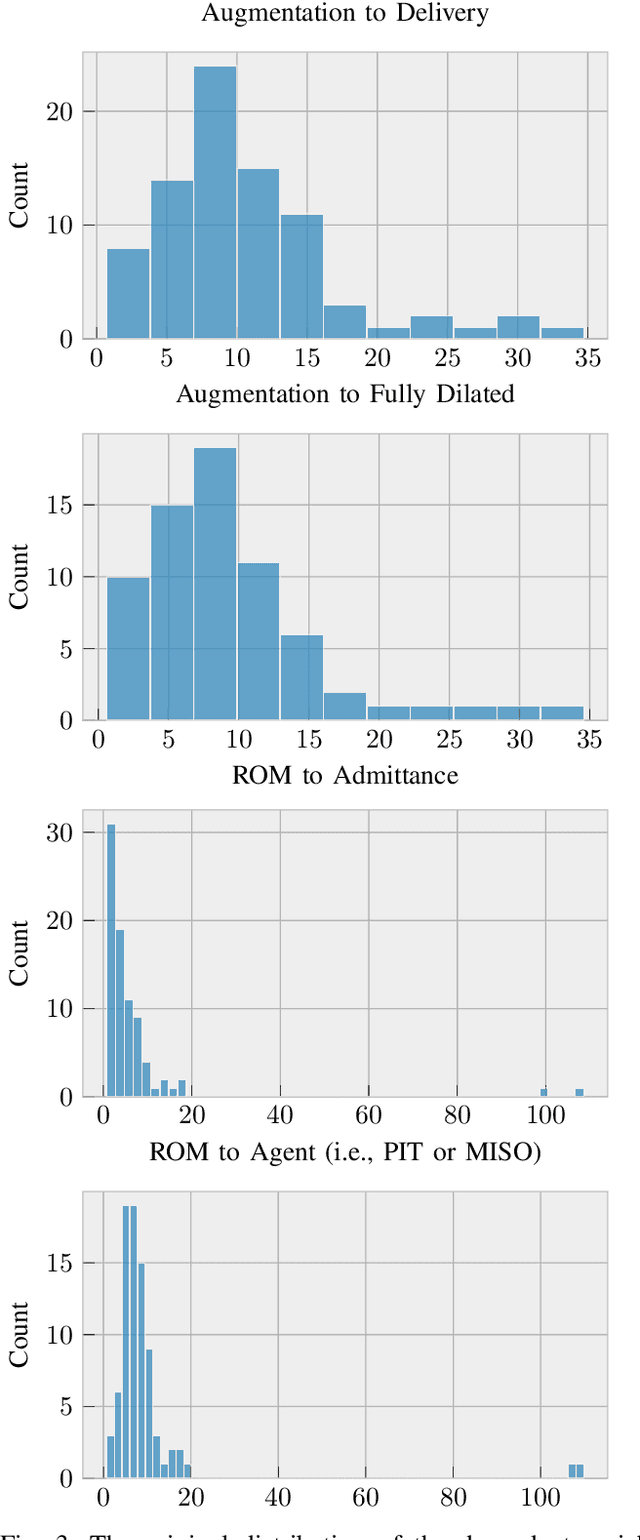
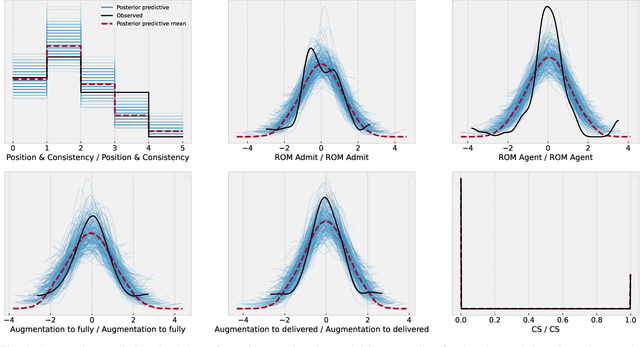
An obstetric goal for a laboring mother is to achieve a vaginal delivery as it reduces the risks inherent in major abdominal surgery (i.e., a Cesarean section). Various medical interventions may be used by a physician to increase the likelihood of this occurring while minimizing maternal and fetal morbidity. However, patients with prelabor rupture of membranes (PROM) have only two commonly used options for cervical ripening, Pitocin and misoprostol. Little research exists on the benefits/risks for these two key drugs for PROM patients. A major limitation with most induction-of-labor related research is the inability to account for differences in \textit{Bishop scores} that are commonly used in obstetrical practice to determine the next induction agent offered to the patient. This creates a confounding factor, which biases the results, but has not been realized in the literature. In this work, we use a Bayesian model of the relationships between the relevant factors, informed by expert physicians, to separate the confounding variable from its actual impact. In doing so, we provide strong evidence that pitocin and buccal misoprostol are equally effective and safe; thus, physicians have more choice in clinical care than previously realized. This is particularly important for developing countries where neither medication may be readily available, and prior guidelines may create an artificial barrier to needed medication.
Human-Interpretable Adversarial Prompt Attack on Large Language Models with Situational Context
Jul 25, 2024



Previous research on testing the vulnerabilities in Large Language Models (LLMs) using adversarial attacks has primarily focused on nonsensical prompt injections, which are easily detected upon manual or automated review (e.g., via byte entropy). However, the exploration of innocuous human-understandable malicious prompts augmented with adversarial injections remains limited. In this research, we explore converting a nonsensical suffix attack into a sensible prompt via a situation-driven contextual re-writing. This allows us to show suffix conversion without any gradients, using only LLMs to perform the attacks, and thus better understand the scope of possible risks. We combine an independent, meaningful adversarial insertion and situations derived from movies to check if this can trick an LLM. The situations are extracted from the IMDB dataset, and prompts are defined following a few-shot chain-of-thought prompting. Our approach demonstrates that a successful situation-driven attack can be executed on both open-source and proprietary LLMs. We find that across many LLMs, as few as 1 attempt produces an attack and that these attacks transfer between LLMs.