 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarine Snow Removal Using Internally Generated Pseudo Ground Truth
Apr 27, 2025



Underwater videos often suffer from degraded quality due to light absorption, scattering, and various noise sources. Among these, marine snow, which is suspended organic particles appearing as bright spots or noise, significantly impacts machine vision tasks, particularly those involving feature matching. Existing methods for removing marine snow are ineffective due to the lack of paired training data. To address this challenge, this paper proposes a novel enhancement framework that introduces a new approach for generating paired datasets from raw underwater videos. The resulting dataset consists of paired images of generated snowy and snow, free underwater videos, enabling supervised training for video enhancement. We describe the dataset creation process, highlight its key characteristics, and demonstrate its effectiveness in enhancing underwater image restoration in the absence of ground truth.
Egocentric affordance detection with the one-shot geometry-driven Interaction Tensor
Jun 13, 2019
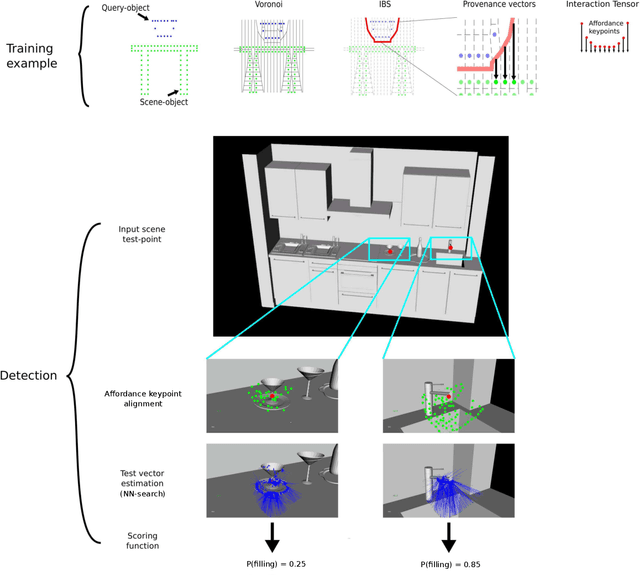


In this abstract we describe recent [4,7] and latest work on the determination of affordances in visually perceived 3D scenes. Our method builds on the hypothesis that geometry on its own provides enough information to enable the detection of significant interaction possibilities in the environment. The motivation behind this is that geometric information is intimately related to the physical interactions afforded by objects in the world. The approach uses a generic representation for the interaction between everyday objects such as a mug or an umbrella with the environment, and also for more complex affordances such as humans Sitting or Riding a motorcycle. Experiments with synthetic and real RGB-D scenes show that the representation enables the prediction of affordance candidate locations in novel environments at fast rates and from a single (one-shot) training example. The determination of affordances is a crucial step towards systems that need to perceive and interact with their surroundings. We here illustrate output on two cases for a simulated robot and for an Augmented Reality setting, both perceiving in an egocentric manner.
What can I do here? Leveraging Deep 3D saliency and geometry for fast and scalable multiple affordance detection
Dec 03, 2018
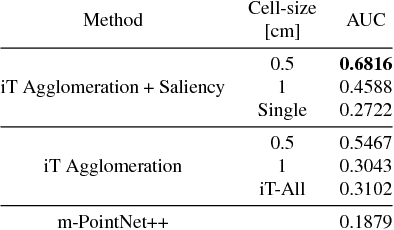
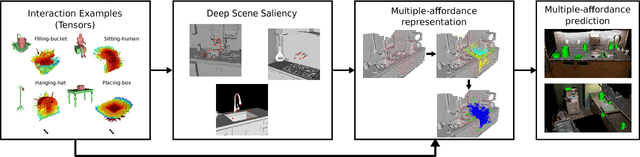
This paper develops and evaluates a novel method that allows for the detection of affordances in a scalable and multiple-instance manner on visually recovered pointclouds. Our approach has many advantages over alternative methods, as it is based on highly parallelizable, one-shot learning that is fast in commodity hardware. The approach is hybrid in that it uses a geometric representation together with a state-of-the-art deep learning method capable of identifying 3D scene saliency. The geometric component allows for a compact and efficient representation, boosting the performance of the deep network architecture which proved insufficient on its own. Moreover, our approach allows not only to predict whether an input scene affords or not the interactions, but also the pose of the objects that allow these interactions to take place. Our predictions align well with crowd-sourced human judgment as they are preferred with 87% probability, show high rates of improvement with almost four times (4x) better performance over a deep learning-only baseline and are seven times (7x) faster than previous art.
Geometric Affordances from a Single Example via the Interaction Tensor
Mar 30, 2017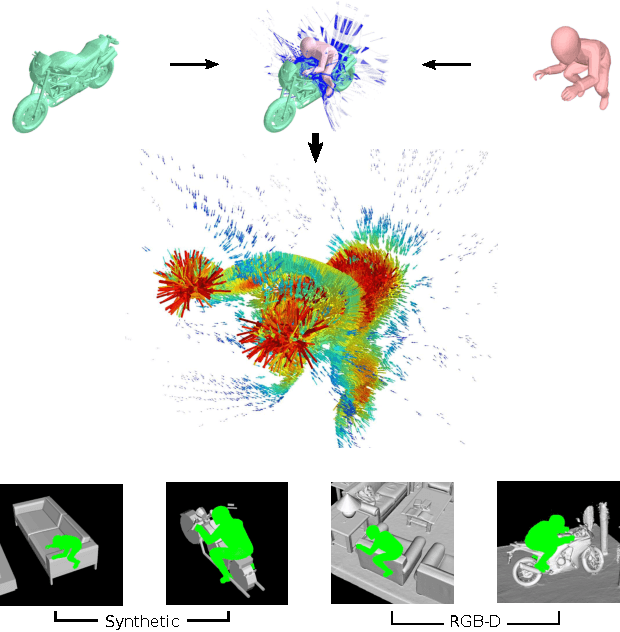
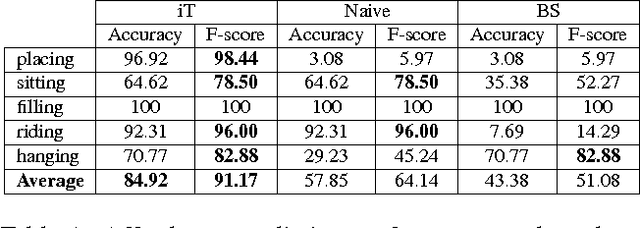
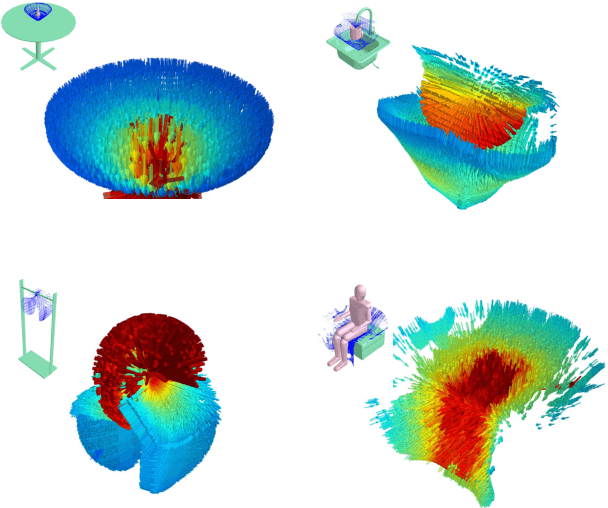

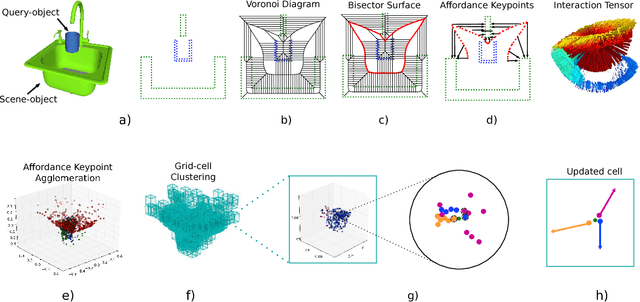
This paper develops and evaluates a new tensor field representation to express the geometric affordance of one object over another. We expand the well known bisector surface representation to one that is weight-driven and that retains the provenance of surface points with directional vectors. We also incorporate the notion of affordance keypoints which allow for faster decisions at a point of query and with a compact and straightforward descriptor. Using a single interaction example, we are able to generalize to previously-unseen scenarios; both synthetic and also real scenes captured with RGBD sensors. We show how our interaction tensor allows for significantly better performance over alternative formulations. Evaluations also include crowdsourcing comparisons that confirm the validity of our affordance proposals, which agree on average 84% of the time with human judgments, and which is 20-40% better than the baseline methods.
Towards an objective evaluation of underactuated gripper designs
Jan 18, 2016
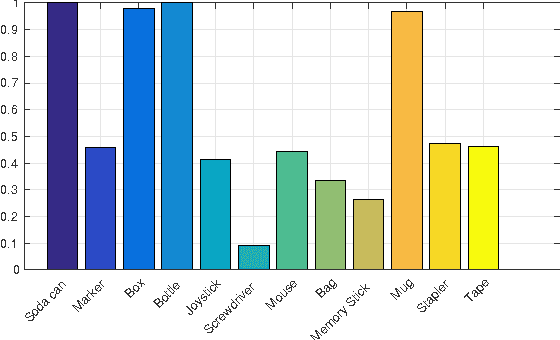
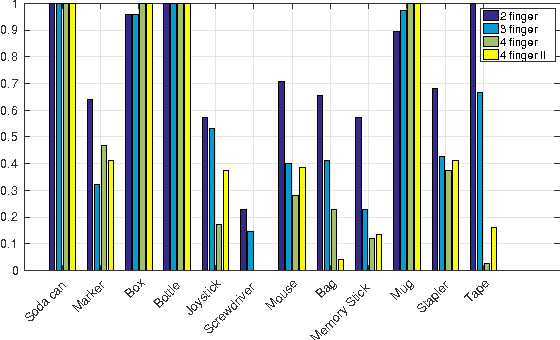

In this paper we explore state-of-the-art underactuated, compliant robot gripper designs through looking at their performance on a generic grasping task. Starting from a state of the art open gripper design, we propose design modifications,and importantly, evaluate all designs on a grasping experiment involving a selection of objects resulting in 3600 object-gripper interactions. Interested in non-planned grasping but rather on a design's generic performance, we explore the influence of object shape, pose and orientation relative to the gripper and its finger number and configuration. Using open-loop grasps we achieved up to 75% success rate over our trials. The results indicate and support that under motion constraints and uncertainties and without involving grasp planning, a 2-fingered underactuated compliant hand outperforms higher multi-fingered configurations. To our knowledge this is the first extended objective comparison of various multi-fingered underactuated hand designs under generic grasping conditions.