 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn argument in favor of strong scaling for deep neural networks with small datasets
Sep 25, 2018
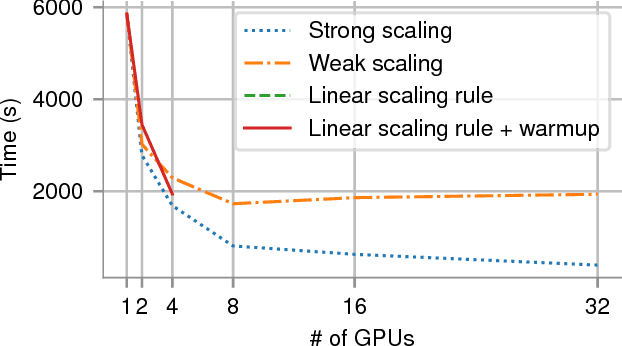
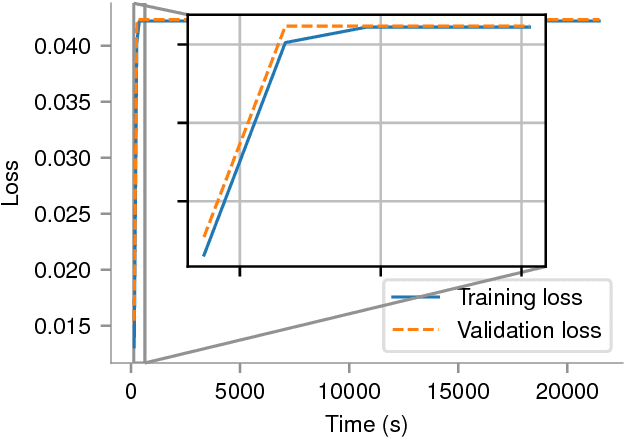
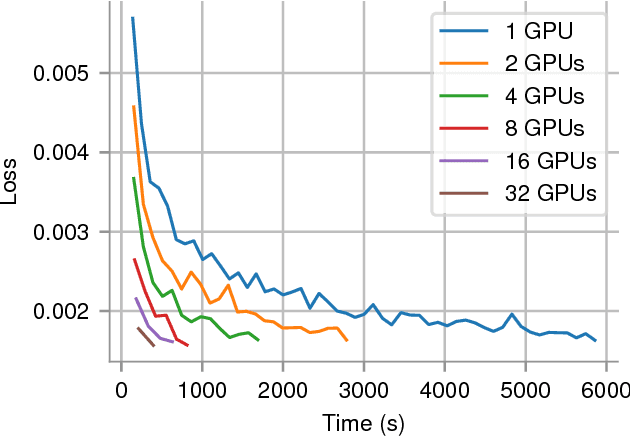
In recent years, with the popularization of deep learning frameworks and large datasets, researchers have started parallelizing their models in order to train faster. This is crucially important, because they typically explore many hyperparameters in order to find the best ones for their applications. This process is time consuming and, consequently, speeding up training improves productivity. One approach to parallelize deep learning models followed by many researchers is based on weak scaling. The minibatches increase in size as new GPUs are added to the system. In addition, new learning rates schedules have been proposed to fix optimization issues that occur with large minibatch sizes. In this paper, however, we show that the recommendations provided by recent work do not apply to models that lack large datasets. In fact, we argument in favor of using strong scaling for achieving reliable performance in such cases. We evaluated our approach with up to 32 GPUs and show that weak scaling not only does not have the same accuracy as the sequential model, it also fails to converge most of time. Meanwhile, strong scaling has good scalability while having exactly the same accuracy of a sequential implementation.
DeepDownscale: a Deep Learning Strategy for High-Resolution Weather Forecast
Aug 15, 2018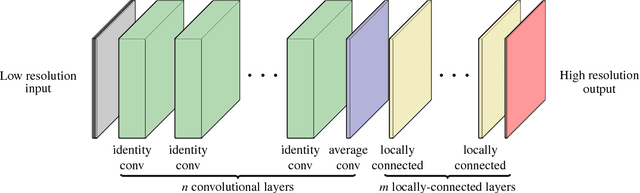
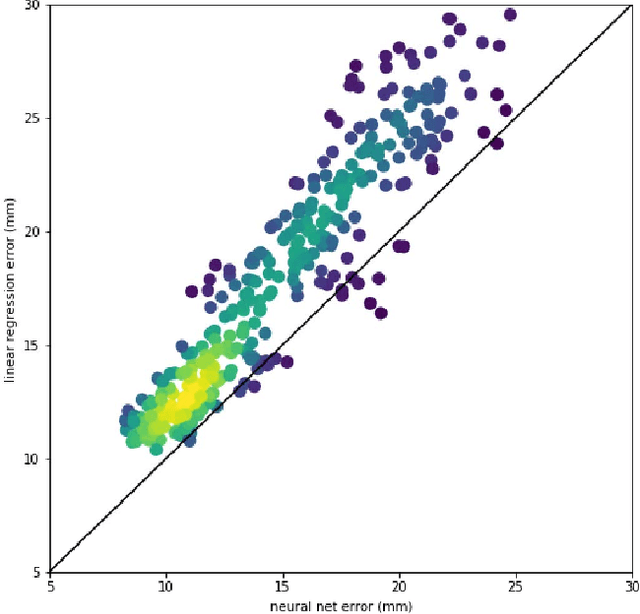
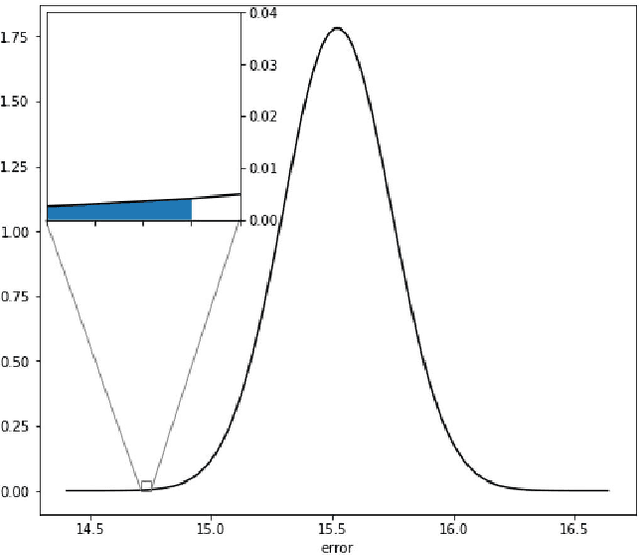
Running high-resolution physical models is computationally expensive and essential for many disciplines. Agriculture, transportation, and energy are sectors that depend on high-resolution weather models, which typically consume many hours of large High Performance Computing (HPC) systems to deliver timely results. Many users cannot afford to run the desired resolution and are forced to use low resolution output. One simple solution is to interpolate results for visualization. It is also possible to combine an ensemble of low resolution models to obtain a better prediction. However, these approaches fail to capture the redundant information and patterns in the low-resolution input that could help improve the quality of prediction. In this paper, we propose and evaluate a strategy based on a deep neural network to learn a high-resolution representation from low-resolution predictions using weather forecast as a practical use case. We take a supervised learning approach, since obtaining labeled data can be done automatically. Our results show significant improvement when compared with standard practices and the strategy is still lightweight enough to run on modest computer systems.