 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Inference Optimized Using the Curved Geometry of Coupled Free Energy
Jun 10, 2025


We introduce an optimization framework for variational inference based on the coupled free energy, extending variational inference techniques to account for the curved geometry of the coupled exponential family. This family includes important heavy-tailed distributions such as the generalized Pareto and the Student's t. By leveraging the coupled free energy, which is equal to the coupled evidence lower bound (ELBO) of the inverted probabilities, we improve the accuracy and robustness of the learned model. The coupled generalization of Fisher Information metric and the affine connection. The method is applied to the design of a coupled variational autoencoder (CVAE). By using the coupling for both the distributions and cost functions, the reconstruction metric is derived to still be the mean-square average loss with modified constants. The novelty comes from sampling the heavy-tailed latent distribution with its associated coupled probability, which has faster decaying tails. The result is the ability to train a model with high penalties in the tails, while assuring that the training samples have a reduced number of outliers. The Wasserstein-2 or Fr\'echet Inception Distance of the reconstructed CelebA images shows the CVAE has a 3\% improvement over the VAE after 5 epochs of training.
A Scalable Machine Learning System for Pre-Season Agriculture Yield Forecast
Oct 15, 2018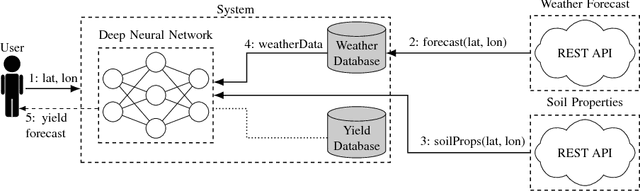


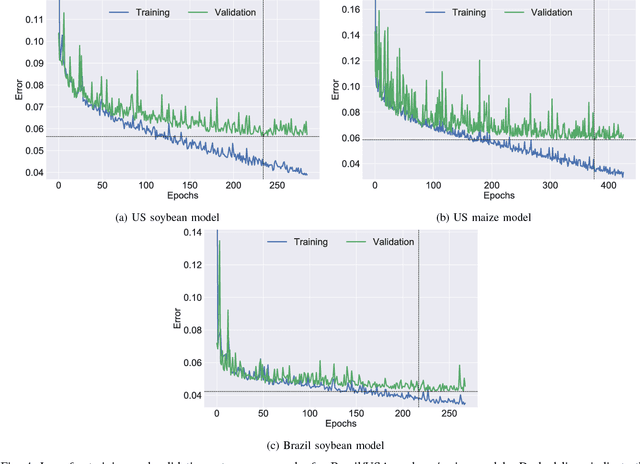
Yield forecast is essential to agriculture stakeholders and can be obtained with the use of machine learning models and data coming from multiple sources. Most solutions for yield forecast rely on NDVI (Normalized Difference Vegetation Index) data, which is time-consuming to be acquired and processed. To bring scalability for yield forecast, in the present paper we describe a system that incorporates satellite-derived precipitation and soil properties datasets, seasonal climate forecasting data from physical models and other sources to produce a pre-season prediction of soybean/maize yield---with no need of NDVI data. This system provides significantly useful results by the exempting the need for high-resolution remote-sensing data and allowing farmers to prepare for adverse climate influence on the crop cycle. In our studies, we forecast the soybean and maize yields for Brazil and USA, which corresponded to 44% of the world's grain production in 2016. Results show the error metrics for soybean and maize yield forecasts are comparable to similar systems that only provide yield forecast information in the first weeks to months of the crop cycle.
DeepDownscale: a Deep Learning Strategy for High-Resolution Weather Forecast
Aug 15, 2018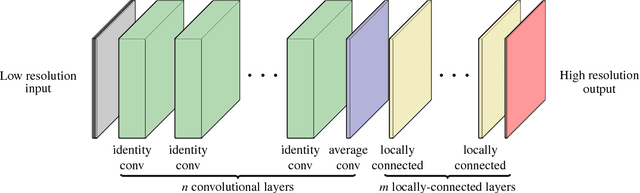
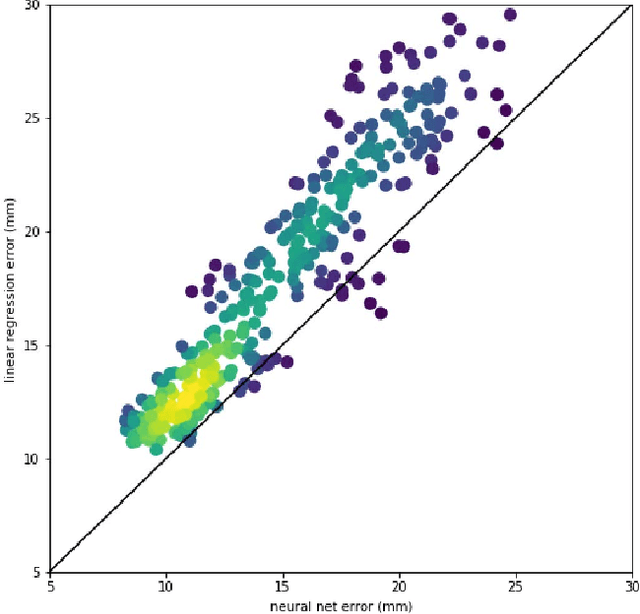
Running high-resolution physical models is computationally expensive and essential for many disciplines. Agriculture, transportation, and energy are sectors that depend on high-resolution weather models, which typically consume many hours of large High Performance Computing (HPC) systems to deliver timely results. Many users cannot afford to run the desired resolution and are forced to use low resolution output. One simple solution is to interpolate results for visualization. It is also possible to combine an ensemble of low resolution models to obtain a better prediction. However, these approaches fail to capture the redundant information and patterns in the low-resolution input that could help improve the quality of prediction. In this paper, we propose and evaluate a strategy based on a deep neural network to learn a high-resolution representation from low-resolution predictions using weather forecast as a practical use case. We take a supervised learning approach, since obtaining labeled data can be done automatically. Our results show significant improvement when compared with standard practices and the strategy is still lightweight enough to run on modest computer systems.