 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn analytic theory of convolutional neural network inverse problems solvers
Jan 15, 2026Supervised convolutional neural networks (CNNs) are widely used to solve imaging inverse problems, achieving state-of-the-art performance in numerous applications. However, despite their empirical success, these methods are poorly understood from a theoretical perspective and often treated as black boxes. To bridge this gap, we analyze trained neural networks through the lens of the Minimum Mean Square Error (MMSE) estimator, incorporating functional constraints that capture two fundamental inductive biases of CNNs: translation equivariance and locality via finite receptive fields. Under the empirical training distribution, we derive an analytic, interpretable, and tractable formula for this constrained variant, termed Local-Equivariant MMSE (LE-MMSE). Through extensive numerical experiments across various inverse problems (denoising, inpainting, deconvolution), datasets (FFHQ, CIFAR-10, FashionMNIST), and architectures (U-Net, ResNet, PatchMLP), we demonstrate that our theory matches the neural networks outputs (PSNR $\gtrsim25$dB). Furthermore, we provide insights into the differences between \emph{physics-aware} and \emph{physics-agnostic} estimators, the impact of high-density regions in the training (patch) distribution, and the influence of other factors (dataset size, patch size, etc).
Learning Theory for Kernel Bilevel Optimization
Feb 12, 2025
Bilevel optimization has emerged as a technique for addressing a wide range of machine learning problems that involve an outer objective implicitly determined by the minimizer of an inner problem. In this paper, we investigate the generalization properties for kernel bilevel optimization problems where the inner objective is optimized over a Reproducing Kernel Hilbert Space. This setting enables rich function approximation while providing a foundation for rigorous theoretical analysis. In this context, we establish novel generalization error bounds for the bilevel problem under finite-sample approximation. Our approach adopts a functional perspective, inspired by (Petrulionyte et al., 2024), and leverages tools from empirical process theory and maximal inequalities for degenerate $U$-processes to derive uniform error bounds. These generalization error estimates allow to characterize the statistical accuracy of gradient-based methods applied to the empirical discretization of the bilevel problem.
A second-order-like optimizer with adaptive gradient scaling for deep learning
Oct 08, 2024



In this empirical article, we introduce INNAprop, an optimization algorithm that combines the INNA method with the RMSprop adaptive gradient scaling. It leverages second-order information and rescaling while keeping the memory requirements of standard DL methods as AdamW or SGD with momentum.After having recalled our geometrical motivations, we provide quite extensive experiments. On image classification (CIFAR-10, ImageNet) and language modeling (GPT-2), INNAprop consistently matches or outperforms AdamW both in training speed and accuracy, with minimal hyperparameter tuning in large-scale settings. Our code is publicly available at \url{https://github.com/innaprop/innaprop}.
Derivatives of Stochastic Gradient Descent
May 24, 2024

We consider stochastic optimization problems where the objective depends on some parameter, as commonly found in hyperparameter optimization for instance. We investigate the behavior of the derivatives of the iterates of Stochastic Gradient Descent (SGD) with respect to that parameter and show that they are driven by an inexact SGD recursion on a different objective function, perturbed by the convergence of the original SGD. This enables us to establish that the derivatives of SGD converge to the derivative of the solution mapping in terms of mean squared error whenever the objective is strongly convex. Specifically, we demonstrate that with constant step-sizes, these derivatives stabilize within a noise ball centered at the solution derivative, and that with vanishing step-sizes they exhibit $O(\log(k)^2 / k)$ convergence rates. Additionally, we prove exponential convergence in the interpolation regime. Our theoretical findings are illustrated by numerical experiments on synthetic tasks.
Inexact subgradient methods for semialgebraic functions
Apr 30, 2024Motivated by the widespread use of approximate derivatives in machine learning and optimization, we study inexact subgradient methods with non-vanishing additive errors and step sizes. In the nonconvex semialgebraic setting, under boundedness assumptions, we prove that the method provides points that eventually fluctuate close to the critical set at a distance proportional to $\epsilon^\rho$ where $\epsilon$ is the error in subgradient evaluation and $\rho$ relates to the geometry of the problem. In the convex setting, we provide complexity results for the averaged values. We also obtain byproducts of independent interest, such as descent-like lemmas for nonsmooth nonconvex problems and some results on the limit of affine interpolants of differential inclusions.
One-step differentiation of iterative algorithms
May 23, 2023



In appropriate frameworks, automatic differentiation is transparent to the user at the cost of being a significant computational burden when the number of operations is large. For iterative algorithms, implicit differentiation alleviates this issue but requires custom implementation of Jacobian evaluation. In this paper, we study one-step differentiation, also known as Jacobian-free backpropagation, a method as easy as automatic differentiation and as performant as implicit differentiation for fast algorithms (e.g., superlinear optimization methods). We provide a complete theoretical approximation analysis with specific examples (Newton's method, gradient descent) along with its consequences in bilevel optimization. Several numerical examples illustrate the well-foundness of the one-step estimator.
Differentiating Nonsmooth Solutions to Parametric Monotone Inclusion Problems
Dec 15, 2022We leverage path differentiability and a recent result on nonsmooth implicit differentiation calculus to give sufficient conditions ensuring that the solution to a monotone inclusion problem will be path differentiable, with formulas for computing its generalized gradient. A direct consequence of our result is that these solutions happen to be differentiable almost everywhere. Our approach is fully compatible with automatic differentiation and comes with assumptions which are easy to check, roughly speaking: semialgebraicity and strong monotonicity. We illustrate the scope of our results by considering three fundamental composite problem settings: strongly convex problems, dual solutions to convex minimization problems and primal-dual solutions to min-max problems.
The derivatives of Sinkhorn-Knopp converge
Aug 03, 2022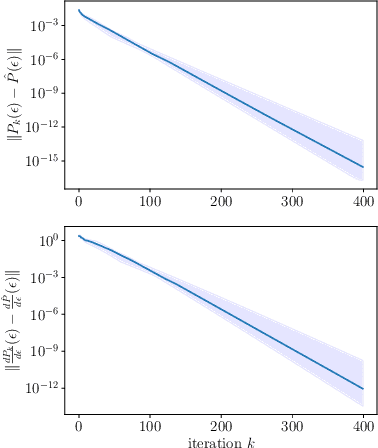
We show that the derivatives of the Sinkhorn-Knopp algorithm, or iterative proportional fitting procedure, converge towards the derivatives of the entropic regularization of the optimal transport problem with a locally uniform linear convergence rate.
Nonsmooth automatic differentiation: a cheap gradient principle and other complexity results
Jun 01, 2022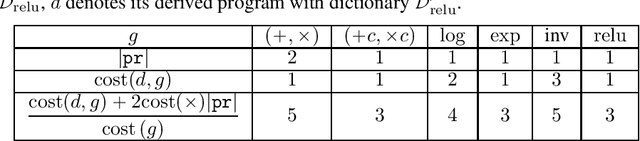
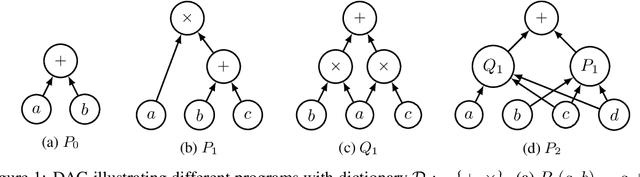
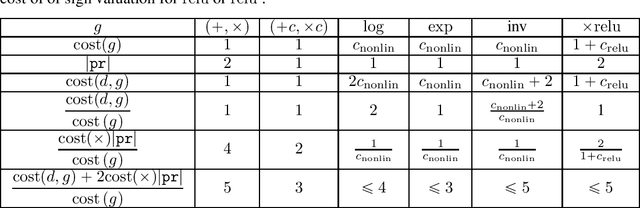
We provide a simple model to estimate the computational costs of the backward and forward modes of algorithmic differentiation for a wide class of nonsmooth programs. Prominent examples are the famous relu and convolutional neural networks together with their standard loss functions. Using the recent notion of conservative gradients, we then establish a "nonsmooth cheap gradient principle" for backpropagation encompassing most concrete applications. Nonsmooth backpropagation's cheapness contrasts with concurrent forward approaches which have, at this day, dimensional-dependent worst case estimates. In order to understand this class of methods, we relate the complexity of computing a large number of directional derivatives to that of matrix multiplication. This shows a fundamental limitation for improving forward AD for that task. Finally, while the fastest algorithms for computing a Clarke subgradient are linear in the dimension, it appears that computing two distinct Clarke (resp. lexicographic) subgradients for simple neural networks is NP-Hard.
Automatic differentiation of nonsmooth iterative algorithms
May 31, 2022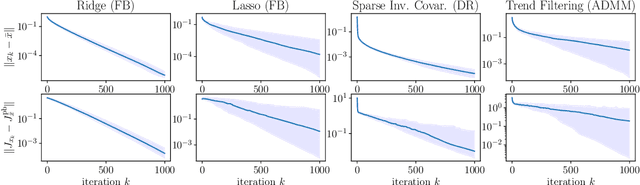

Differentiation along algorithms, i.e., piggyback propagation of derivatives, is now routinely used to differentiate iterative solvers in differentiable programming. Asymptotics is well understood for many smooth problems but the nondifferentiable case is hardly considered. Is there a limiting object for nonsmooth piggyback automatic differentiation (AD)? Does it have any variational meaning and can it be used effectively in machine learning? Is there a connection with classical derivative? All these questions are addressed under appropriate nonexpansivity conditions in the framework of conservative derivatives which has proved useful in understanding nonsmooth AD. For nonsmooth piggyback iterations, we characterize the attractor set of nonsmooth piggyback iterations as a set-valued fixed point which remains in the conservative framework. This has various consequences and in particular almost everywhere convergence of classical derivatives. Our results are illustrated on parametric convex optimization problems with forward-backward, Douglas-Rachford and Alternating Direction of Multiplier algorithms as well as the Heavy-Ball method.