 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning by Reconstructing Neighborhoods
Nov 06, 2018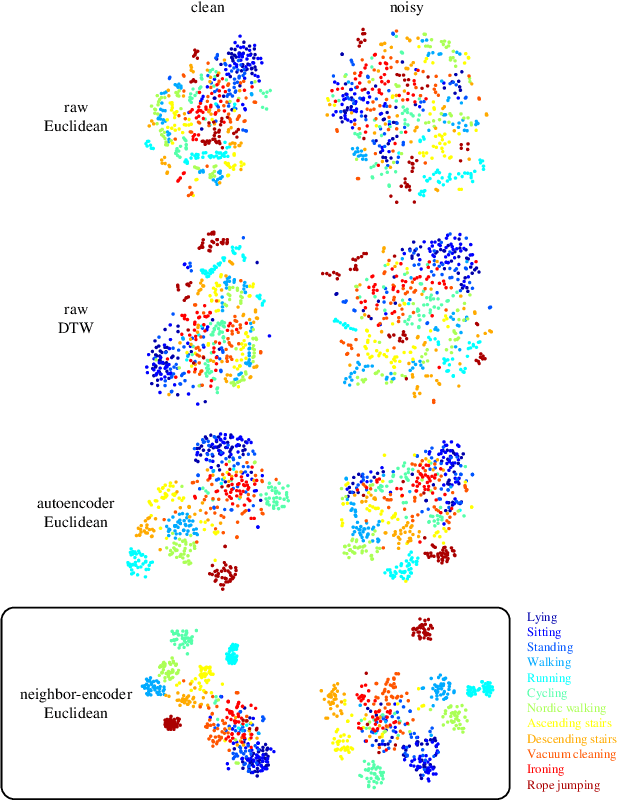
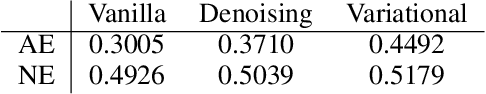
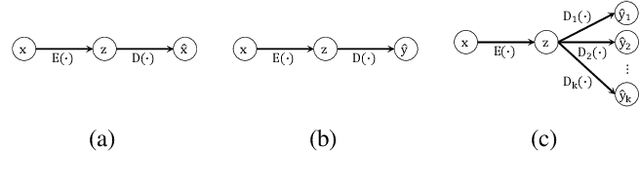
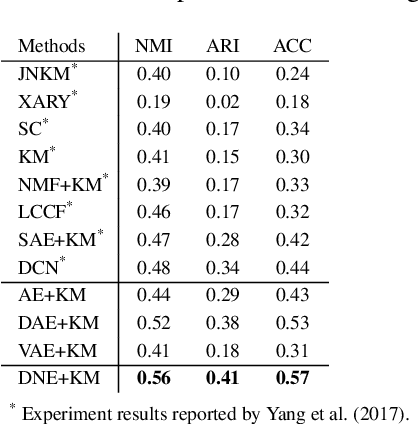
Since its introduction, unsupervised representation learning has attracted a lot of attention from the research community, as it is demonstrated to be highly effective and easy-to-apply in tasks such as dimension reduction, clustering, visualization, information retrieval, and semi-supervised learning. In this work, we propose a novel unsupervised representation learning framework called neighbor-encoder, in which domain knowledge can be easily incorporated into the learning process without modifying the general encoder-decoder architecture of the classic autoencoder.In contrast to autoencoder, which reconstructs the input data itself, neighbor-encoder reconstructs the input data's neighbors. As the proposed representation learning problem is essentially a neighbor reconstruction problem, domain knowledge can be easily incorporated in the form of an appropriate definition of similarity between objects. Based on that observation, our framework can leverage any off-the-shelf similarity search algorithms or side information to find the neighbor of an input object. Applications of other algorithms (e.g., association rule mining) in our framework are also possible, given that the appropriate definition of neighbor can vary in different contexts. We have demonstrated the effectiveness of our framework in many diverse domains, including images, text, and time series, and for various data mining tasks including classification, clustering, and visualization. Experimental results show that neighbor-encoder not only outperforms autoencoder in most of the scenarios we consider, but also achieves the state-of-the-art performance on text document clustering.
The UEA multivariate time series classification archive, 2018
Oct 31, 2018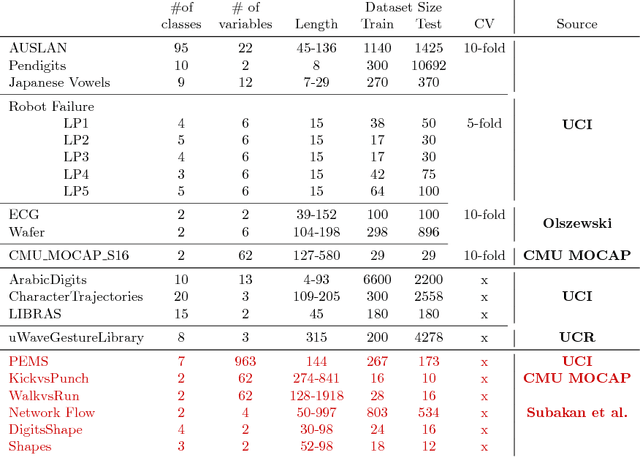
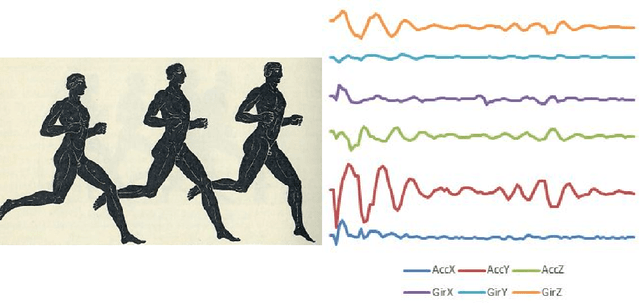
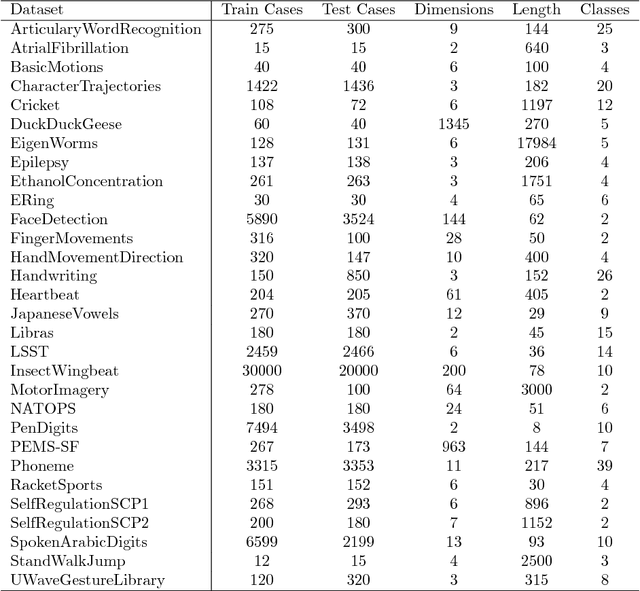
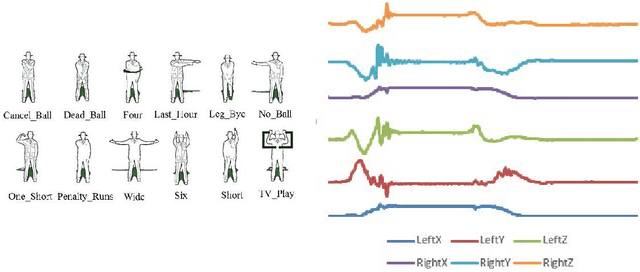
In 2002, the UCR time series classification archive was first released with sixteen datasets. It gradually expanded, until 2015 when it increased in size from 45 datasets to 85 datasets. In October 2018 more datasets were added, bringing the total to 128. The new archive contains a wide range of problems, including variable length series, but it still only contains univariate time series classification problems. One of the motivations for introducing the archive was to encourage researchers to perform a more rigorous evaluation of newly proposed time series classification (TSC) algorithms. It has worked: most recent research into TSC uses all 85 datasets to evaluate algorithmic advances. Research into multivariate time series classification, where more than one series are associated with each class label, is in a position where univariate TSC research was a decade ago. Algorithms are evaluated using very few datasets and claims of improvement are not based on statistical comparisons. We aim to address this problem by forming the first iteration of the MTSC archive, to be hosted at the website www.timeseriesclassification.com. Like the univariate archive, this formulation was a collaborative effort between researchers at the University of East Anglia (UEA) and the University of California, Riverside (UCR). The 2018 vintage consists of 30 datasets with a wide range of cases, dimensions and series lengths. For this first iteration of the archive we format all data to be of equal length, include no series with missing data and provide train/test splits.
The UCR Time Series Archive
Oct 17, 2018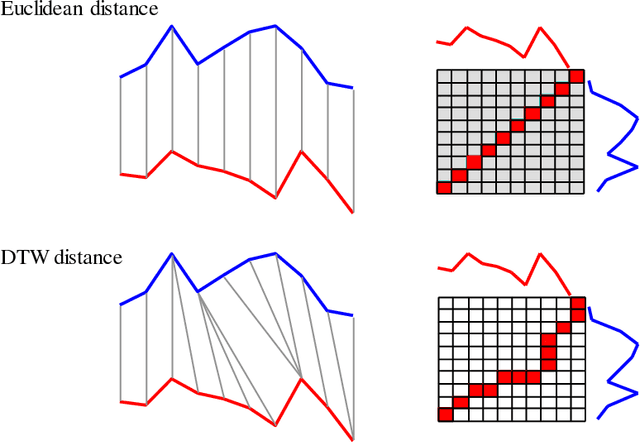
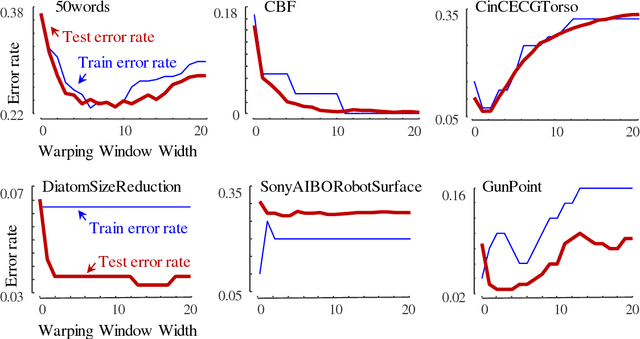
The UCR Time Series Archive - introduced in 2002, has become an important resource in the time series data mining community, with at least one thousand published papers making use of at least one dataset from the archive. The original incarnation of the archive had sixteen datasets but since that time, it has gone through periodic expansions. The last expansion took place in the summer of 2015 when the archive grew from 45 datasets to 85 datasets. This paper introduces and will focus on the new data expansion from 85 to 128 datasets. Beyond expanding this valuable resource, this paper offers pragmatic advice to anyone who may wish to evaluate a new algorithm on the archive. Finally, this paper makes a novel and yet actionable claim: of the hundreds of papers that show an improvement over the standard baseline (1-Nearest Neighbor classification), a large fraction may be misattributing the reasons for their improvement. Moreover, they may have been able to achieve the same improvement with a much simpler modification, requiring just a single line of code.
Admissible Time Series Motif Discovery with Missing Data
Feb 15, 2018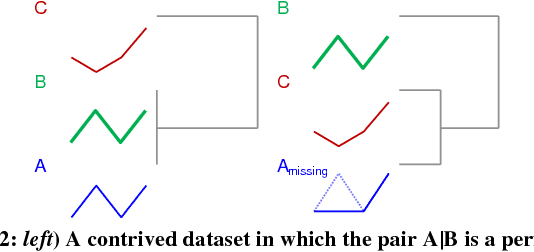
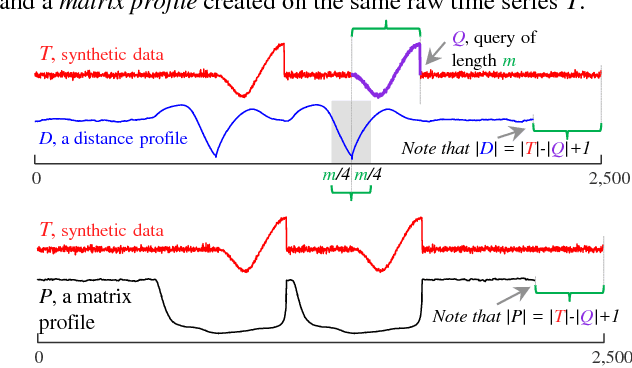
The discovery of time series motifs has emerged as one of the most useful primitives in time series data mining. Researchers have shown its utility for exploratory data mining, summarization, visualization, segmentation, classification, clustering, and rule discovery. Although there has been more than a decade of extensive research, there is still no technique to allow the discovery of time series motifs in the presence of missing data, despite the well-documented ubiquity of missing data in scientific, industrial, and medical datasets. In this work, we introduce a technique for motif discovery in the presence of missing data. We formally prove that our method is admissible, producing no false negatives. We also show that our method can piggy-back off the fastest known motif discovery method with a small constant factor time/space overhead. We will demonstrate our approach on diverse datasets with varying amounts of missing data
A General Framework for Density Based Time Series Clustering Exploiting a Novel Admissible Pruning Strategy
Dec 02, 2016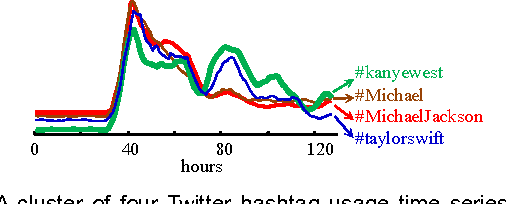
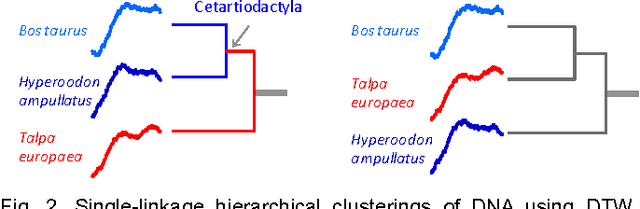
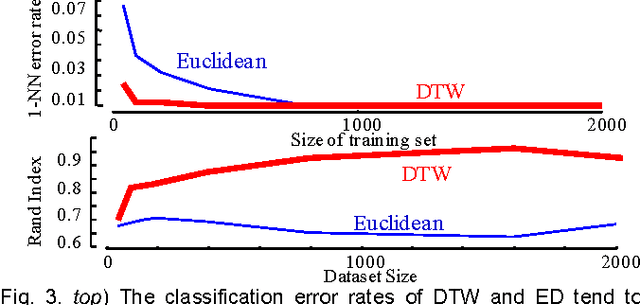

Time Series Clustering is an important subroutine in many higher-level data mining analyses, including data editing for classifiers, summarization, and outlier detection. It is well known that for similarity search the superiority of Dynamic Time Warping (DTW) over Euclidean distance gradually diminishes as we consider ever larger datasets. However, as we shall show, the same is not true for clustering. Clustering time series under DTW remains a computationally expensive operation. In this work, we address this issue in two ways. We propose a novel pruning strategy that exploits both the upper and lower bounds to prune off a very large fraction of the expensive distance calculations. This pruning strategy is admissible and gives us provably identical results to the brute force algorithm, but is at least an order of magnitude faster. For datasets where even this level of speedup is inadequate, we show that we can use a simple heuristic to order the unavoidable calculations in a most-useful-first ordering, thus casting the clustering into an anytime framework. We demonstrate the utility of our ideas with both single and multidimensional case studies in the domains of astronomy, speech physiology, medicine and entomology. In addition, we show the generality of our clustering framework to other domains by efficiently obtaining semantically significant clusters in protein sequences using the Edit Distance, the discrete data analogue of DTW.
Flying Insect Classification with Inexpensive Sensors
Mar 11, 2014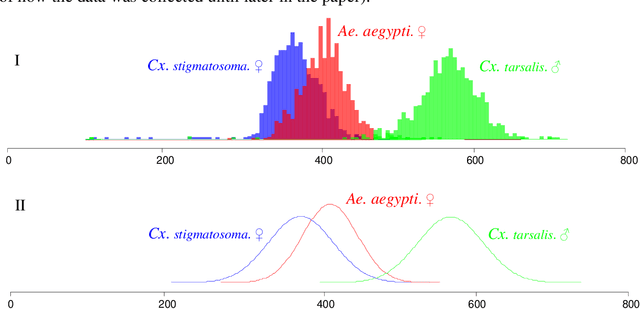
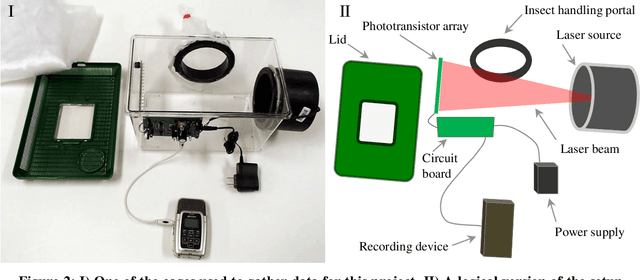
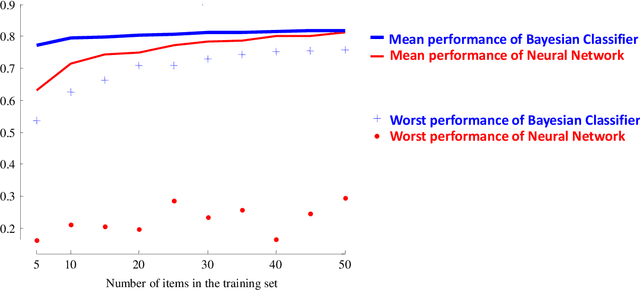
The ability to use inexpensive, noninvasive sensors to accurately classify flying insects would have significant implications for entomological research, and allow for the development of many useful applications in vector control for both medical and agricultural entomology. Given this, the last sixty years have seen many research efforts on this task. To date, however, none of this research has had a lasting impact. In this work, we explain this lack of progress. We attribute the stagnation on this problem to several factors, including the use of acoustic sensing devices, the over-reliance on the single feature of wingbeat frequency, and the attempts to learn complex models with relatively little data. In contrast, we show that pseudo-acoustic optical sensors can produce vastly superior data, that we can exploit additional features, both intrinsic and extrinsic to the insect's flight behavior, and that a Bayesian classification approach allows us to efficiently learn classification models that are very robust to over-fitting. We demonstrate our findings with large scale experiments that dwarf all previous works combined, as measured by the number of insects and the number of species considered.
Experimental Comparison of Representation Methods and Distance Measures for Time Series Data
Dec 09, 2010
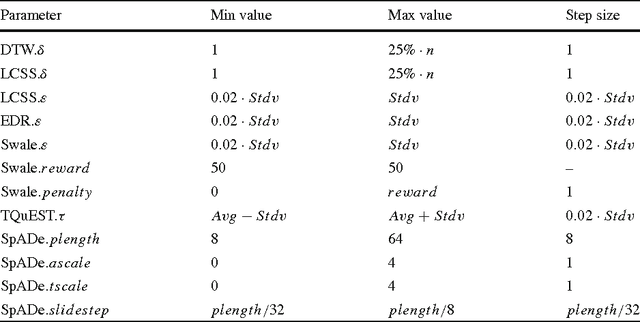

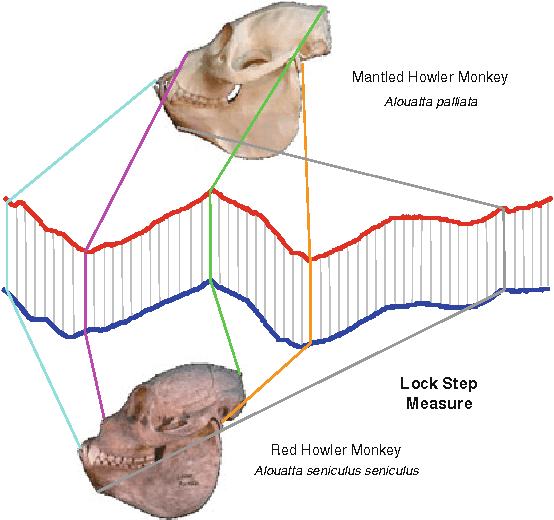
The previous decade has brought a remarkable increase of the interest in applications that deal with querying and mining of time series data. Many of the research efforts in this context have focused on introducing new representation methods for dimensionality reduction or novel similarity measures for the underlying data. In the vast majority of cases, each individual work introducing a particular method has made specific claims and, aside from the occasional theoretical justifications, provided quantitative experimental observations. However, for the most part, the comparative aspects of these experiments were too narrowly focused on demonstrating the benefits of the proposed methods over some of the previously introduced ones. In order to provide a comprehensive validation, we conducted an extensive experimental study re-implementing eight different time series representations and nine similarity measures and their variants, and testing their effectiveness on thirty-eight time series data sets from a wide variety of application domains. In this paper, we give an overview of these different techniques and present our comparative experimental findings regarding their effectiveness. In addition to providing a unified validation of some of the existing achievements, our experiments also indicate that, in some cases, certain claims in the literature may be unduly optimistic.