 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrection of AI systems by linear discriminants: Probabilistic foundations
Nov 11, 2018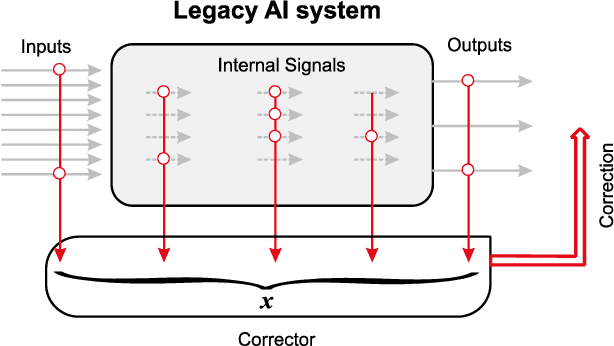



Artificial Intelligence (AI) systems sometimes make errors and will make errors in the future, from time to time. These errors are usually unexpected, and can lead to dramatic consequences. Intensive development of AI and its practical applications makes the problem of errors more important. Total re-engineering of the systems can create new errors and is not always possible due to the resources involved. The important challenge is to develop fast methods to correct errors without damaging existing skills. We formulated the technical requirements to the 'ideal' correctors. Such correctors include binary classifiers, which separate the situations with high risk of errors from the situations where the AI systems work properly. Surprisingly, for essentially high-dimensional data such methods are possible: simple linear Fisher discriminant can separate the situations with errors from correctly solved tasks even for exponentially large samples. The paper presents the probabilistic basis for fast non-destructive correction of AI systems. A series of new stochastic separation theorems is proven. These theorems provide new instruments for fast non-iterative correction of errors of legacy AI systems. The new approaches become efficient in high-dimensions, for correction of high-dimensional systems in high-dimensional world (i.e. for processing of essentially high-dimensional data by large systems).
* arXiv admin note: text overlap with arXiv:1809.07656 and arXiv:1802.02172
How deep should be the depth of convolutional neural networks: a backyard dog case study
May 03, 2018


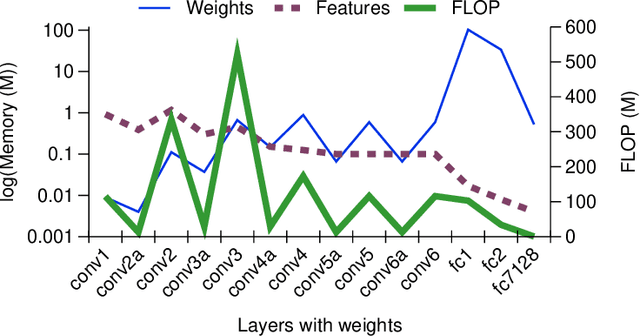
We present a straightforward non-iterative method for shallowing of deep Convolutional Neural Network (CNN) by combination of several layers of CNNs with Advanced Supervised Principal Component Analysis (ASPCA) of their outputs. We tested this new method on a practically important case of `friend-or-foe' face recognition. This is the backyard dog problem: the dog should (i) distinguish the members of the family from possible strangers and (ii) identify the members of the family. Our experiments revealed that the method is capable of drastically reducing the depth of deep learning CNNs, albeit at the cost of mild performance deterioration.
Piece-wise quadratic approximations of arbitrary error functions for fast and robust machine learning
Aug 21, 2016



Most of machine learning approaches have stemmed from the application of minimizing the mean squared distance principle, based on the computationally efficient quadratic optimization methods. However, when faced with high-dimensional and noisy data, the quadratic error functionals demonstrated many weaknesses including high sensitivity to contaminating factors and dimensionality curse. Therefore, a lot of recent applications in machine learning exploited properties of non-quadratic error functionals based on $L_1$ norm or even sub-linear potentials corresponding to quasinorms $L_p$ ($0<p<1$). The back side of these approaches is increase in computational cost for optimization. Till so far, no approaches have been suggested to deal with {\it arbitrary} error functionals, in a flexible and computationally efficient framework. In this paper, we develop a theory and basic universal data approximation algorithms ($k$-means, principal components, principal manifolds and graphs, regularized and sparse regression), based on piece-wise quadratic error potentials of subquadratic growth (PQSQ potentials). We develop a new and universal framework to minimize {\it arbitrary sub-quadratic error potentials} using an algorithm with guaranteed fast convergence to the local or global error minimum. The theory of PQSQ potentials is based on the notion of the cone of minorant functions, and represents a natural approximation formalism based on the application of min-plus algebra. The approach can be applied in most of existing machine learning methods, including methods of data approximation and regularized and sparse regression, leading to the improvement in the computational cost/accuracy trade-off. We demonstrate that on synthetic and real-life datasets PQSQ-based machine learning methods achieve orders of magnitude faster computational performance than the corresponding state-of-the-art methods.
* Edited and extended version with algortihms of regularized regression
Geometrical complexity of data approximators
May 04, 2013



There are many methods developed to approximate a cloud of vectors embedded in high-dimensional space by simpler objects: starting from principal points and linear manifolds to self-organizing maps, neural gas, elastic maps, various types of principal curves and principal trees, and so on. For each type of approximators the measure of the approximator complexity was developed too. These measures are necessary to find the balance between accuracy and complexity and to define the optimal approximations of a given type. We propose a measure of complexity (geometrical complexity) which is applicable to approximators of several types and which allows comparing data approximations of different types.
* 10 pages, 3 figures, minor correction and extension
Initialization of Self-Organizing Maps: Principal Components Versus Random Initialization. A Case Study
Oct 22, 2012
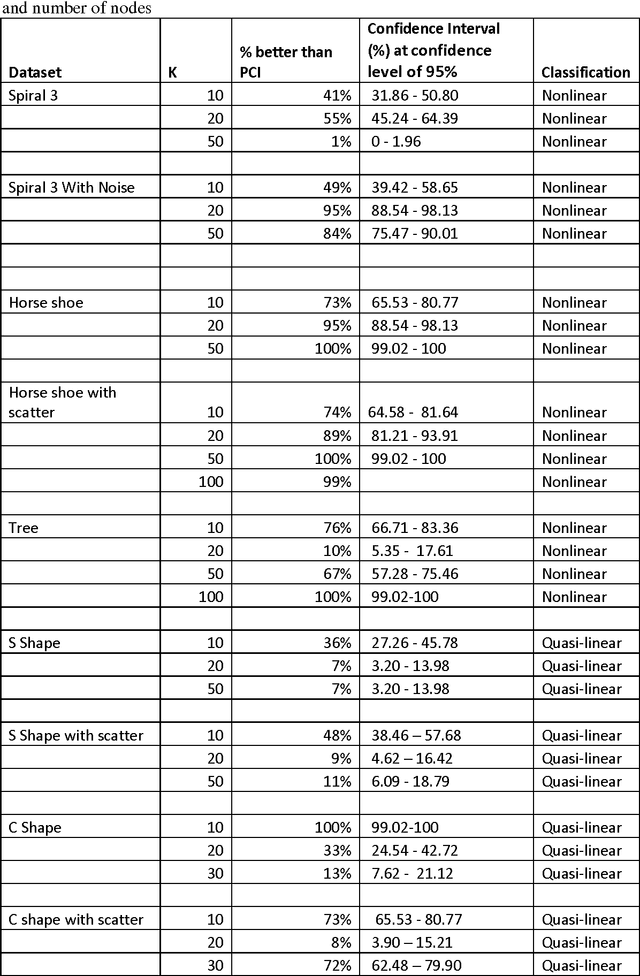


The performance of the Self-Organizing Map (SOM) algorithm is dependent on the initial weights of the map. The different initialization methods can broadly be classified into random and data analysis based initialization approach. In this paper, the performance of random initialization (RI) approach is compared to that of principal component initialization (PCI) in which the initial map weights are chosen from the space of the principal component. Performance is evaluated by the fraction of variance unexplained (FVU). Datasets were classified into quasi-linear and non-linear and it was observed that RI performed better for non-linear datasets; however the performance of PCI approach remains inconclusive for quasi-linear datasets.