 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrection of AI systems by linear discriminants: Probabilistic foundations
Nov 11, 2018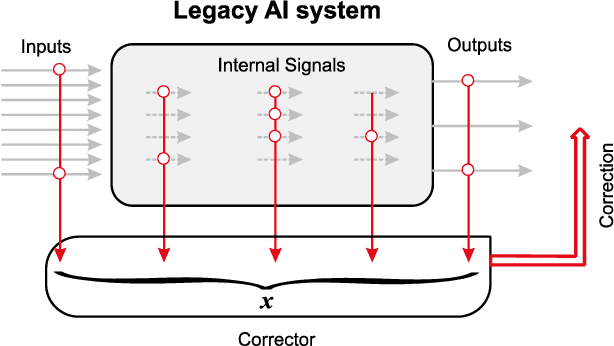



Artificial Intelligence (AI) systems sometimes make errors and will make errors in the future, from time to time. These errors are usually unexpected, and can lead to dramatic consequences. Intensive development of AI and its practical applications makes the problem of errors more important. Total re-engineering of the systems can create new errors and is not always possible due to the resources involved. The important challenge is to develop fast methods to correct errors without damaging existing skills. We formulated the technical requirements to the 'ideal' correctors. Such correctors include binary classifiers, which separate the situations with high risk of errors from the situations where the AI systems work properly. Surprisingly, for essentially high-dimensional data such methods are possible: simple linear Fisher discriminant can separate the situations with errors from correctly solved tasks even for exponentially large samples. The paper presents the probabilistic basis for fast non-destructive correction of AI systems. A series of new stochastic separation theorems is proven. These theorems provide new instruments for fast non-iterative correction of errors of legacy AI systems. The new approaches become efficient in high-dimensions, for correction of high-dimensional systems in high-dimensional world (i.e. for processing of essentially high-dimensional data by large systems).
* arXiv admin note: text overlap with arXiv:1809.07656 and arXiv:1802.02172
The unreasonable effectiveness of small neural ensembles in high-dimensional brain
Sep 20, 2018


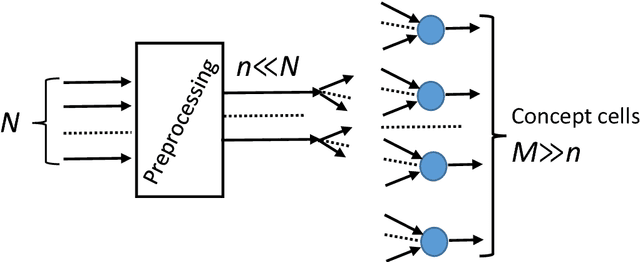
Despite the widely-spread consensus on the brain complexity, sprouts of the single neuron revolution emerged in neuroscience in the 1970s. They brought many unexpected discoveries, including grandmother or concept cells and sparse coding of information in the brain. In machine learning for a long time, the famous curse of dimensionality seemed to be an unsolvable problem. Nevertheless, the idea of the blessing of dimensionality becomes gradually more and more popular. Ensembles of non-interacting or weakly interacting simple units prove to be an effective tool for solving essentially multidimensional problems. This approach is especially useful for one-shot (non-iterative) correction of errors in large legacy artificial intelligence systems. These simplicity revolutions in the era of complexity have deep fundamental reasons grounded in geometry of multidimensional data spaces. To explore and understand these reasons we revisit the background ideas of statistical physics. In the course of the 20th century they were developed into the concentration of measure theory. New stochastic separation theorems reveal the fine structure of the data clouds. We review and analyse biological, physical, and mathematical problems at the core of the fundamental question: how can high-dimensional brain organise reliable and fast learning in high-dimensional world of data by simple tools? Two critical applications are reviewed to exemplify the approach: one-shot correction of errors in intellectual systems and emergence of static and associative memories in ensembles of single neurons.
Blessing of dimensionality: mathematical foundations of the statistical physics of data
Jan 10, 2018
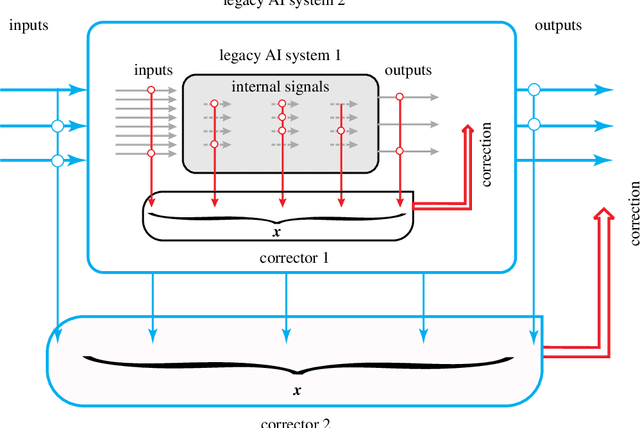

The concentration of measure phenomena were discovered as the mathematical background of statistical mechanics at the end of the XIX - beginning of the XX century and were then explored in mathematics of the XX-XXI centuries. At the beginning of the XXI century, it became clear that the proper utilisation of these phenomena in machine learning might transform the curse of dimensionality into the blessing of dimensionality. This paper summarises recently discovered phenomena of measure concentration which drastically simplify some machine learning problems in high dimension, and allow us to correct legacy artificial intelligence systems. The classical concentration of measure theorems state that i.i.d. random points are concentrated in a thin layer near a surface (a sphere or equators of a sphere, an average or median level set of energy or another Lipschitz function, etc.). The new stochastic separation theorems describe the thin structure of these thin layers: the random points are not only concentrated in a thin layer but are all linearly separable from the rest of the set, even for exponentially large random sets. The linear functionals for separation of points can be selected in the form of the linear Fisher's discriminant. All artificial intelligence systems make errors. Non-destructive correction requires separation of the situations (samples) with errors from the samples corresponding to correct behaviour by a simple and robust classifier. The stochastic separation theorems provide us by such classifiers and a non-iterative (one-shot) procedure for learning.
* Accepted for publication in Philosophical Transactions of the Royal Society A, 2018. Comprises of 17 pages and 4 figures
Stochastic Separation Theorems
Aug 03, 2017

The problem of non-iterative one-shot and non-destructive correction of unavoidable mistakes arises in all Artificial Intelligence applications in the real world. Its solution requires robust separation of samples with errors from samples where the system works properly. We demonstrate that in (moderately) high dimension this separation could be achieved with probability close to one by linear discriminants. Surprisingly, separation of a new image from a very large set of known images is almost always possible even in moderately high dimensions by linear functionals, and coefficients of these functionals can be found explicitly. Based on fundamental properties of measure concentration, we show that for $M<a\exp(b{n})$ random $M$-element sets in $\mathbb{R}^n$ are linearly separable with probability $p$, $p>1-\vartheta$, where $1>\vartheta>0$ is a given small constant. Exact values of $a,b>0$ depend on the probability distribution that determines how the random $M$-element sets are drawn, and on the constant $\vartheta$. These {\em stochastic separation theorems} provide a new instrument for the development, analysis, and assessment of machine learning methods and algorithms in high dimension. Theoretical statements are illustrated with numerical examples.
* 6 pages, accepted for publication in Neural Networks (Letter section)