 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiece-wise quadratic approximations of arbitrary error functions for fast and robust machine learning
Aug 21, 2016



Most of machine learning approaches have stemmed from the application of minimizing the mean squared distance principle, based on the computationally efficient quadratic optimization methods. However, when faced with high-dimensional and noisy data, the quadratic error functionals demonstrated many weaknesses including high sensitivity to contaminating factors and dimensionality curse. Therefore, a lot of recent applications in machine learning exploited properties of non-quadratic error functionals based on $L_1$ norm or even sub-linear potentials corresponding to quasinorms $L_p$ ($0<p<1$). The back side of these approaches is increase in computational cost for optimization. Till so far, no approaches have been suggested to deal with {\it arbitrary} error functionals, in a flexible and computationally efficient framework. In this paper, we develop a theory and basic universal data approximation algorithms ($k$-means, principal components, principal manifolds and graphs, regularized and sparse regression), based on piece-wise quadratic error potentials of subquadratic growth (PQSQ potentials). We develop a new and universal framework to minimize {\it arbitrary sub-quadratic error potentials} using an algorithm with guaranteed fast convergence to the local or global error minimum. The theory of PQSQ potentials is based on the notion of the cone of minorant functions, and represents a natural approximation formalism based on the application of min-plus algebra. The approach can be applied in most of existing machine learning methods, including methods of data approximation and regularized and sparse regression, leading to the improvement in the computational cost/accuracy trade-off. We demonstrate that on synthetic and real-life datasets PQSQ-based machine learning methods achieve orders of magnitude faster computational performance than the corresponding state-of-the-art methods.
* Edited and extended version with algortihms of regularized regression
Nonlinear Quality of Life Index
Jul 24, 2014

We present details of the analysis of the nonlinear quality of life index for 171 countries. This index is based on four indicators: GDP per capita by Purchasing Power Parities, Life expectancy at birth, Infant mortality rate, and Tuberculosis incidence. We analyze the structure of the data in order to find the optimal and independent on expert's opinion way to map several numerical indicators from a multidimensional space onto the one-dimensional space of the quality of life. In the 4D space we found a principal curve that goes "through the middle" of the dataset and project the data points on this curve. The order along this principal curve gives us the ranking of countries. Projection onto the principal curve provides a solution to the classical problem of unsupervised ranking of objects. It allows us to find the independent on expert's opinion way to project several numerical indicators from a multidimensional space onto the one-dimensional space of the index values. This projection is, in some sense, optimal and preserves as much information as possible. For computation we used ViDaExpert, a tool for visualization and analysis of multidimensional vectorial data (arXiv:1406.5550).
Geometrical complexity of data approximators
May 04, 2013



There are many methods developed to approximate a cloud of vectors embedded in high-dimensional space by simpler objects: starting from principal points and linear manifolds to self-organizing maps, neural gas, elastic maps, various types of principal curves and principal trees, and so on. For each type of approximators the measure of the approximator complexity was developed too. These measures are necessary to find the balance between accuracy and complexity and to define the optimal approximations of a given type. We propose a measure of complexity (geometrical complexity) which is applicable to approximators of several types and which allows comparing data approximations of different types.
* 10 pages, 3 figures, minor correction and extension
Principal manifolds and graphs in practice: from molecular biology to dynamical systems
Jul 25, 2010
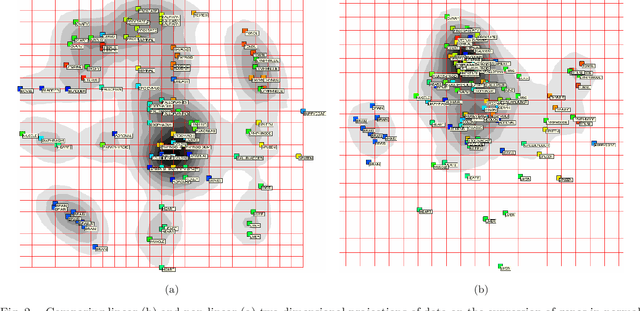
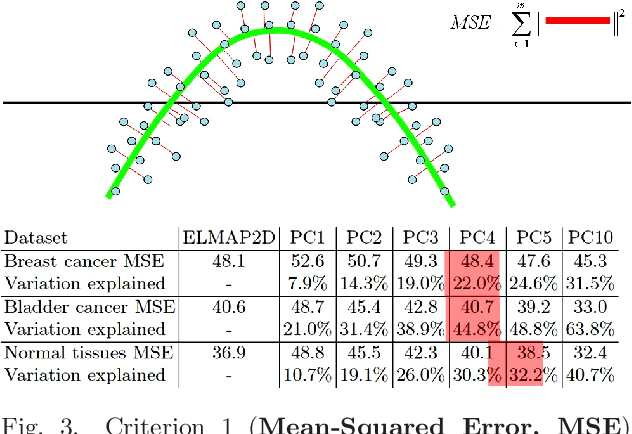
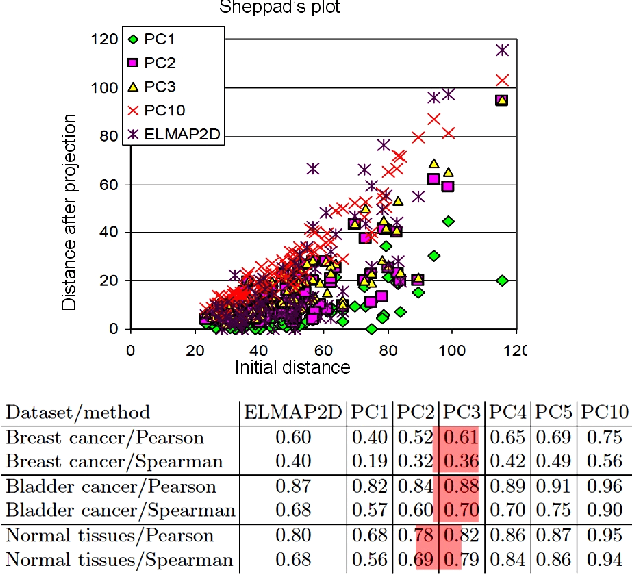
We present several applications of non-linear data modeling, using principal manifolds and principal graphs constructed using the metaphor of elasticity (elastic principal graph approach). These approaches are generalizations of the Kohonen's self-organizing maps, a class of artificial neural networks. On several examples we show advantages of using non-linear objects for data approximation in comparison to the linear ones. We propose four numerical criteria for comparing linear and non-linear mappings of datasets into the spaces of lower dimension. The examples are taken from comparative political science, from analysis of high-throughput data in molecular biology, from analysis of dynamical systems.
* 12 pages, 9 figures