 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-DEEP: 3-Dimensional Deep-learning based on elevation patterns forroad scene interpretation
Sep 01, 2020

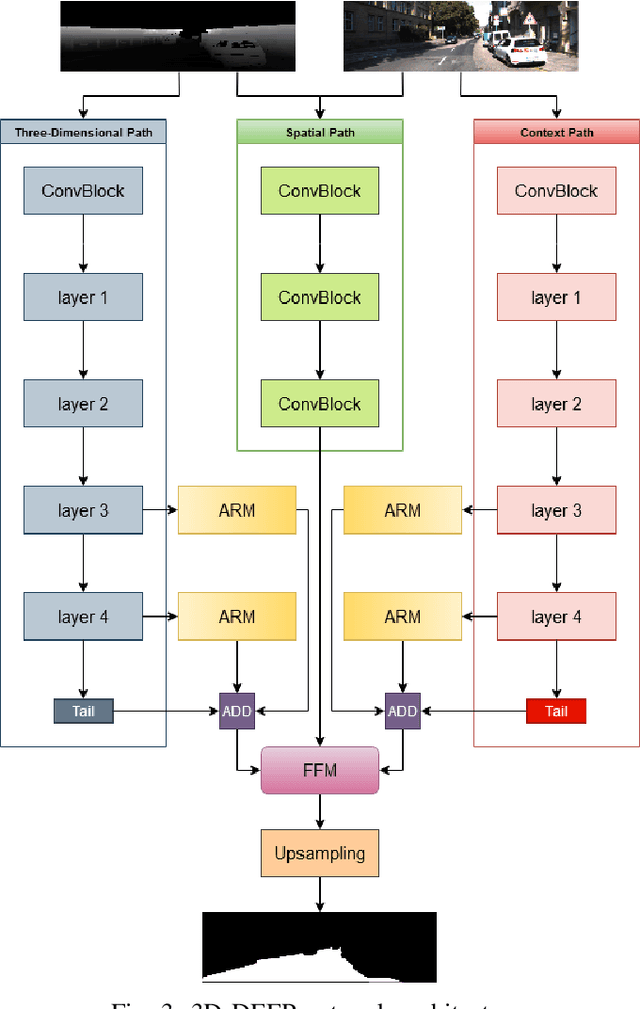
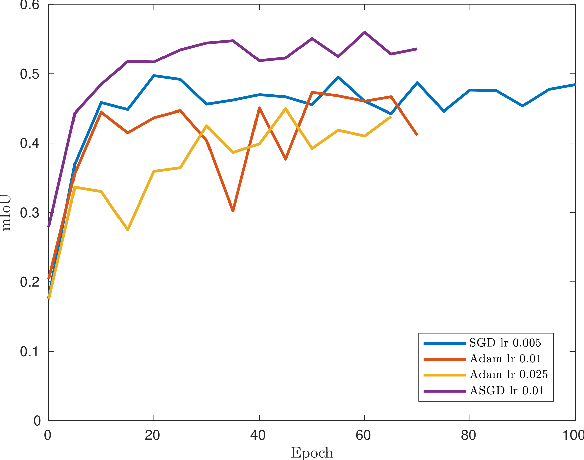
Road detection and segmentation is a crucial task in computer vision for safe autonomous driving. With this in mind, a new net architecture (3D-DEEP) and its end-to-end training methodology for CNN-based semantic segmentation are described along this paper for. The method relies on disparity filtered and LiDAR projected images for three-dimensional information and image feature extraction through fully convolutional networks architectures. The developed models were trained and validated over Cityscapes dataset using just fine annotation examples with 19 different training classes, and over KITTI road dataset. 72.32% mean intersection over union(mIoU) has been obtained for the 19 Cityscapes training classes using the validation images. On the other hand, over KITTIdataset the model has achieved an F1 error value of 97.85% invalidation and 96.02% using the test images.
Compositional Hierarchical Tensor Factorization: Representing Hierarchical Intrinsic and Extrinsic Causal Factors
Nov 11, 2019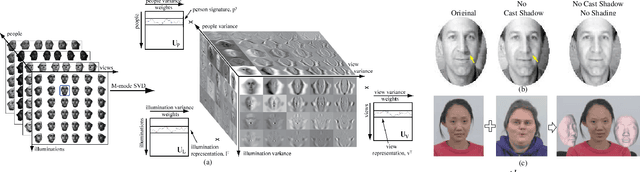


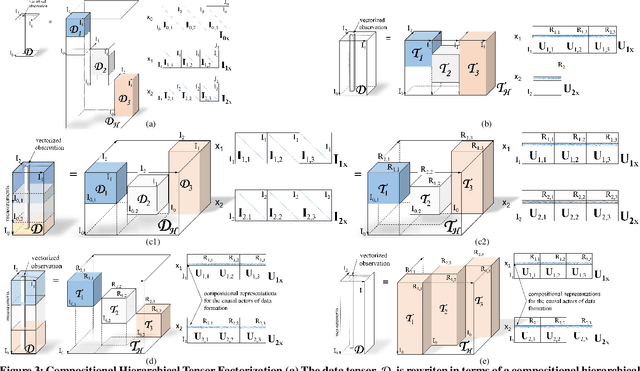
Visual objects are composed of a recursive hierarchy of perceptual wholes and parts, whose properties, such as shape, reflectance, and color, constitute a hierarchy of intrinsic causal factors of object appearance. However, object appearance is the compositional consequence of both an object's intrinsic and extrinsic causal factors, where the extrinsic causal factors are related to illumination, and imaging conditions. Therefore, this paper proposes a unified tensor model of wholes and parts, and introduces a compositional hierarchical tensor factorization that disentangles the hierarchical causal structure of object image formation, and subsumes multilinear block tensor decomposition as a special case. The resulting object representation is an interpretable combinatorial choice of wholes' and parts' representations that renders object recognition robust to occlusion and reduces training data requirements. We demonstrate ourapproach in the context of face recognition by training on an extremely reduced dataset of synthetic images, and report encouragingface verification results on two datasets - the Freiburg dataset, andthe Labeled Face in the Wild (LFW) dataset consisting of real world images, thus, substantiating the suitability of our approach for data starved domains.