 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing the Neural Architecture of Reinforcement Learning Agents
Nov 30, 2020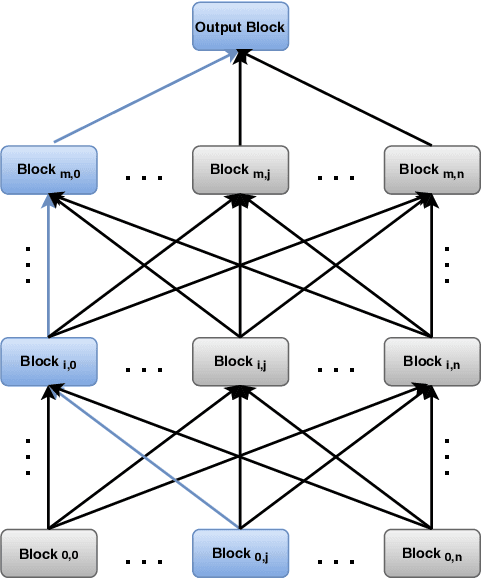
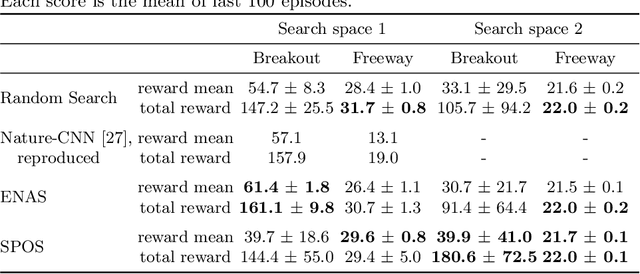
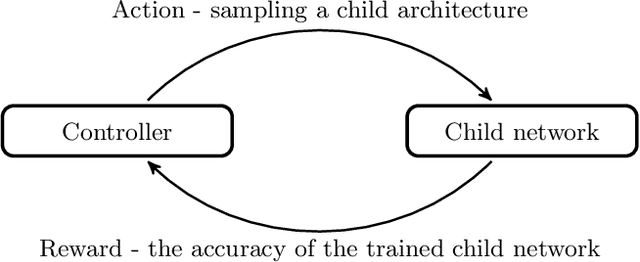
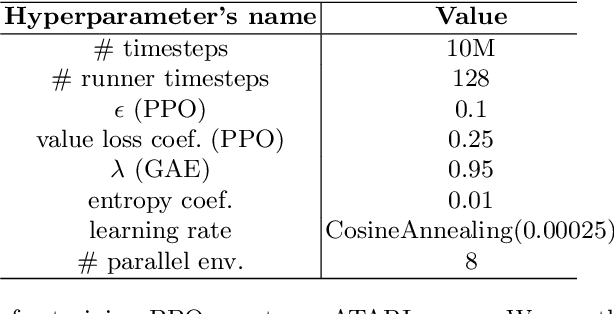
Reinforcement learning (RL) enjoyed significant progress over the last years. One of the most important steps forward was the wide application of neural networks. However, architectures of these neural networks are typically constructed manually. In this work, we study recently proposed neural architecture search (NAS) methods for optimizing the architecture of RL agents. We carry out experiments on the Atari benchmark and conclude that modern NAS methods find architectures of RL agents outperforming a manually selected one.
Differentiable Language Model Adversarial Attacks on Categorical Sequence Classifiers
Jun 19, 2020
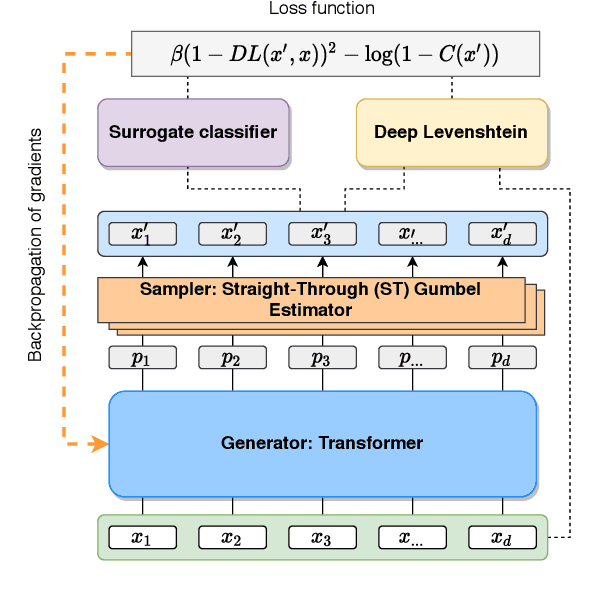
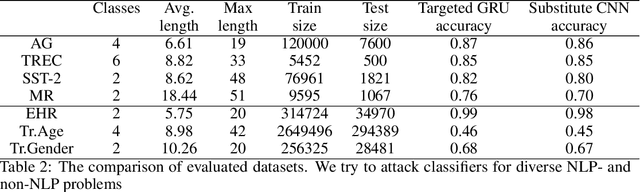
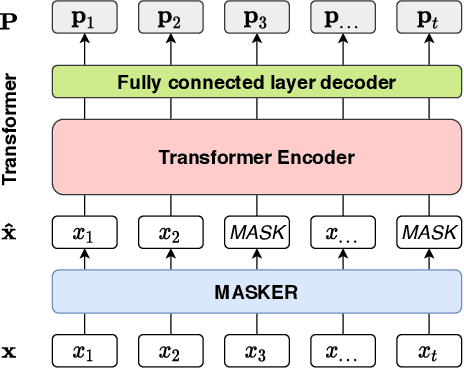
An adversarial attack paradigm explores various scenarios for the vulnerability of deep learning models: minor changes of the input can force a model failure. Most of the state of the art frameworks focus on adversarial attacks for images and other structured model inputs, but not for categorical sequences models. Successful attacks on classifiers of categorical sequences are challenging because the model input is tokens from finite sets, so a classifier score is non-differentiable with respect to inputs, and gradient-based attacks are not applicable. Common approaches deal with this problem working at a token level, while the discrete optimization problem at hand requires a lot of resources to solve. We instead use a fine-tuning of a language model for adversarial attacks as a generator of adversarial examples. To optimize the model, we define a differentiable loss function that depends on a surrogate classifier score and on a deep learning model that evaluates approximate edit distance. So, we control both the adversability of a generated sequence and its similarity to the initial sequence. As a result, we obtain semantically better samples. Moreover, they are resistant to adversarial training and adversarial detectors. Our model works for diverse datasets on bank transactions, electronic health records, and NLP datasets.
Sequence embeddings help to identify fraudulent cases in healthcare insurance
Oct 07, 2019

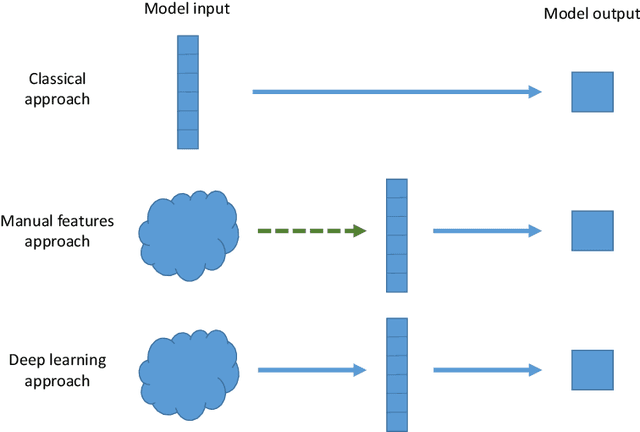
Fraud causes substantial costs and losses for companies and clients in the finance and insurance industries. Examples are fraudulent credit card transactions or fraudulent claims. It has been estimated that roughly $10$ percent of the insurance industry's incurred losses and loss adjustment expenses each year stem from fraudulent claims. The rise and proliferation of digitization in finance and insurance have lead to big data sets, consisting in particular of text data, which can be used for fraud detection. In this paper, we propose architectures for text embeddings via deep learning, which help to improve the detection of fraudulent claims compared to other machine learning methods. We illustrate our methods using a data set from a large international health insurance company. The empirical results show that our approach outperforms other state-of-the-art methods and can help make the claims management process more efficient. As (unstructured) text data become increasingly available to economists and econometricians, our proposed methods will be valuable for many similar applications, particularly when variables have a large number of categories as is typical for example of the International Classification of Disease (ICD) codes in health economics and health services.
Usage of multiple RTL features for Earthquake prediction
May 26, 2019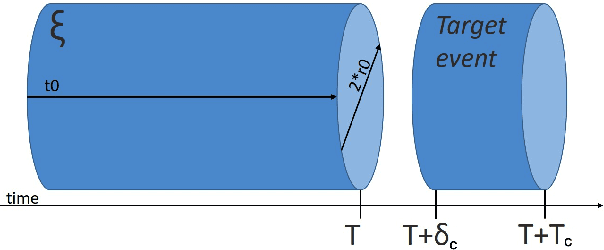
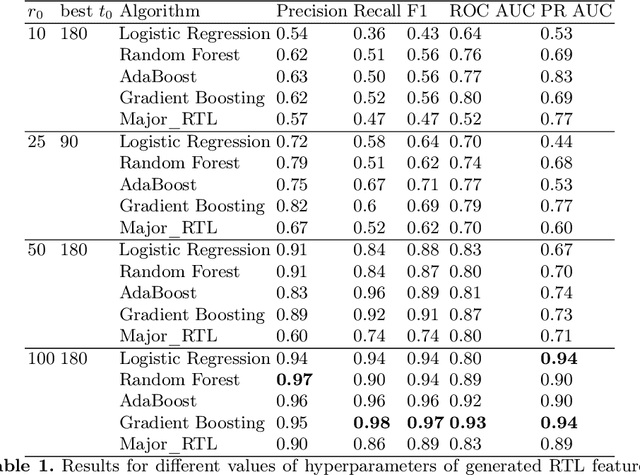
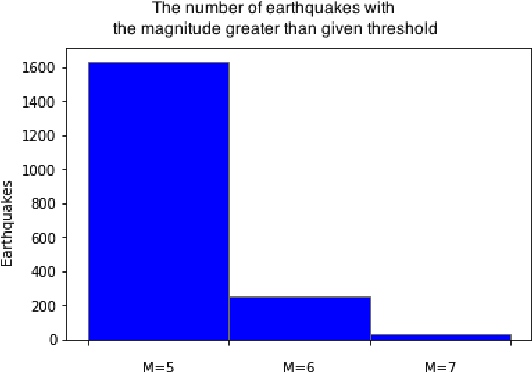
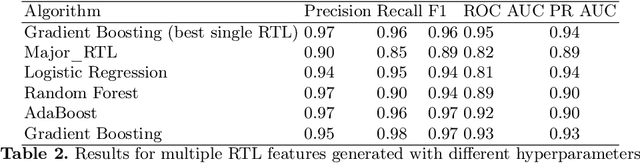
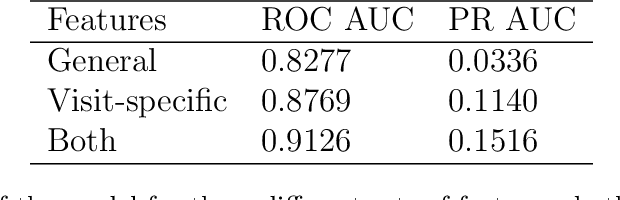
We construct a classification model that predicts if an earthquake with the magnitude above a threshold will take place at a given location in a time range 30-180 days from a given moment of time. A common approach is to use expert forecasts based on features like Region-Time-Length (RTL) characteristics. The proposed approach uses machine learning on top of multiple RTL features to take into account effects at various scales and to improve prediction accuracy. For historical data about Japan earthquakes 1992-2005 and predictions at locations given in this database the best model has precision up to ~ 0.95 and recall up to ~ 0.98.
* 13 pages, 3 figures, 3 tables
Learning Ensembles of Anomaly Detectors on Synthetic Data
May 20, 2019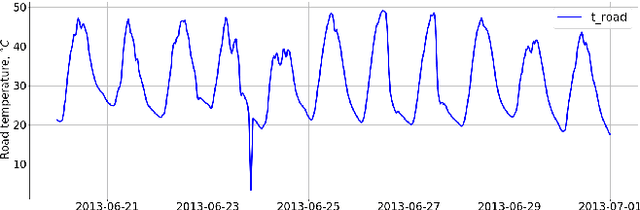
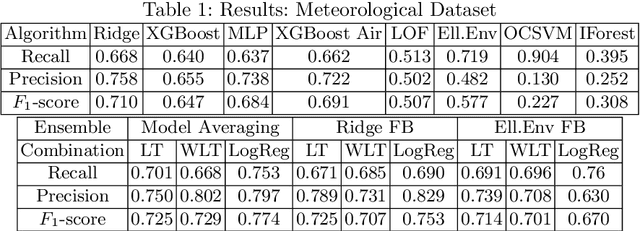
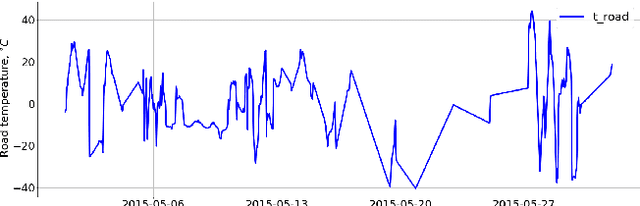
The main aim of this work is to develop and implement an automatic anomaly detection algorithm for meteorological time-series. To achieve this goal we develop an approach to constructing an ensemble of anomaly detectors in combination with adaptive threshold selection based on artificially generated anomalies. We demonstrate the efficiency of the proposed method by integrating the corresponding implementation into ``Minimax-94'' road weather information system.
* 15 pages, 6 figures
Perceptually-based single-image depth super-resolution
Dec 24, 2018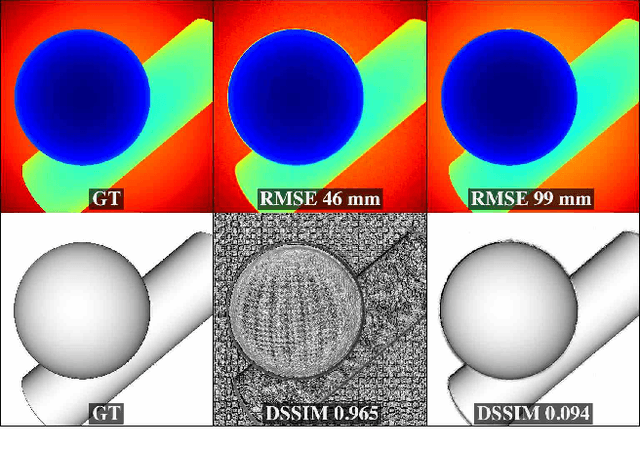

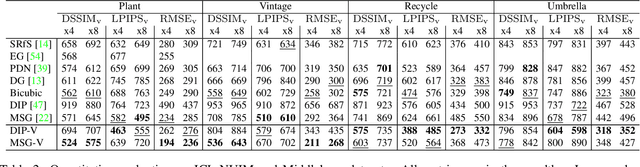
RGBD images, combining high-resolution color and lower-resolution depth from various types of depth sensors, are increasingly common. One can significantly improve the resolution of depth images by taking advantage of color information; deep learning methods make combining color and depth information particularly easy. However, fusing these two sources of data may lead to a variety of artifacts. If depth maps are used to reconstruct 3D shapes, e.g., for virtual reality applications, the visual quality of upsampled images is particularly important. To achieve high-quality results, visual metric need to be taken into account. The main idea of our approach is to measure the quality of depth map upsampling using renderings of resulting 3D surfaces. We demonstrate that a simple visual appearance-based loss, when used with either a trained CNN or simply a deep prior, yields significantly improved 3D shapes, as measured by a number of existing perceptual metrics. We compare this approach with a number of existing optimization and learning-based techniques.