 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Basic Emotions in Texts Based on BERT Vector Representation
Jan 31, 2021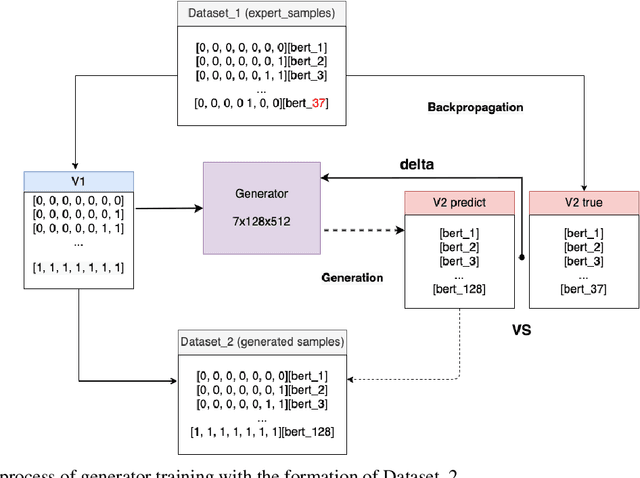
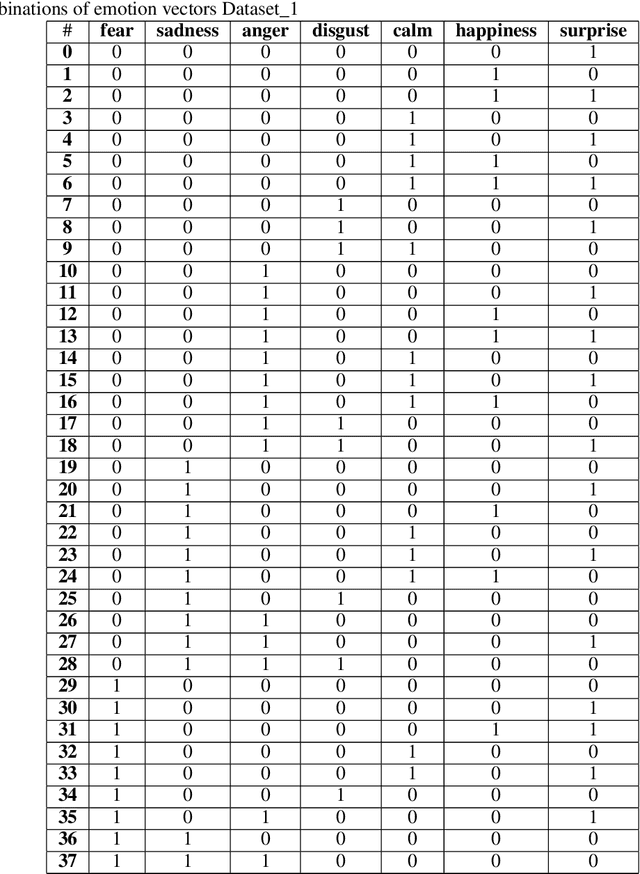
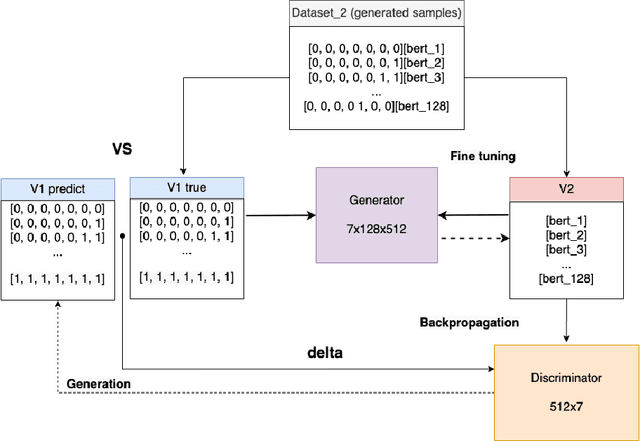
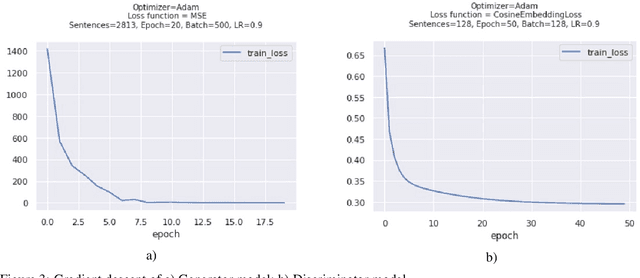
In the following paper the authors present a GAN-type model and the most important stages of its development for the task of emotion recognition in text. In particular, we propose an approach for generating a synthetic dataset of all possible emotions combinations based on manually labelled incomplete data.
Neural Network-based Object Classification by Known and Unknown Features (Based on Text Queries)
Jun 03, 2019

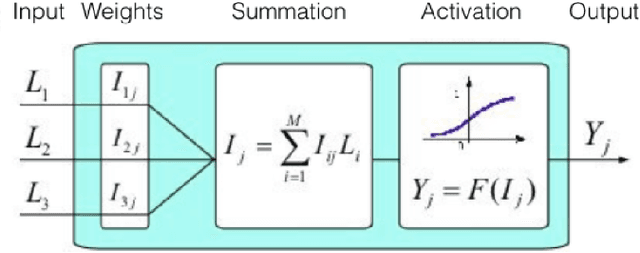

The article presents a method that improves the quality of classification of objects described by a combination of known and unknown features. The method is based on modernized Informational Neurobayesian Approach with consideration of unknown features. The proposed method was developed and trained on 1500 text queries of Promobot users in Russian to classify them into 20 categories (classes). As a result, the use of the method allowed to completely solve the problem of misclassification for queries with combining known and unknown features of the model. The theoretical substantiation of the method is presented by the formulated and proved theorem On the Model with Limited Knowledge. It states, that in conditions of limited data, an equal number of equally unknown features of an object cannot have different significance for the classification problem.
Perceptually-based single-image depth super-resolution
Dec 24, 2018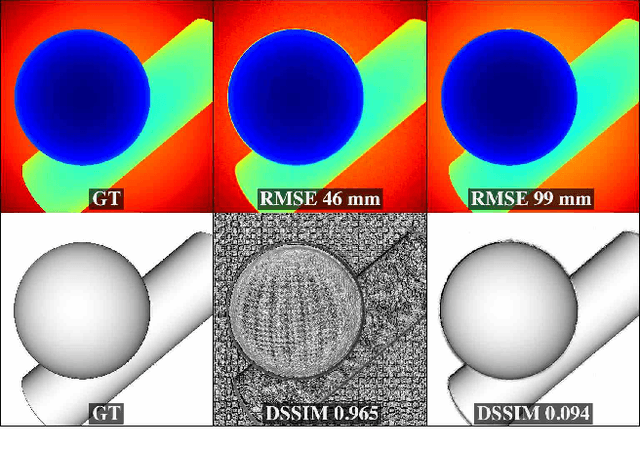
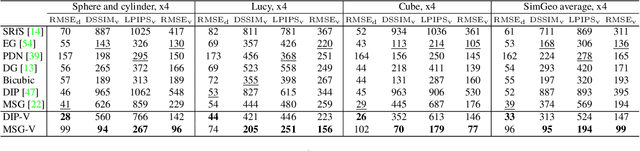

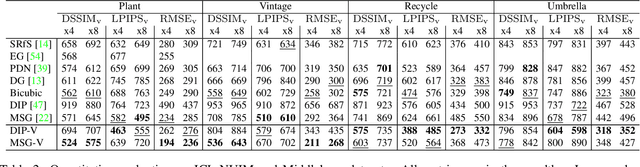
RGBD images, combining high-resolution color and lower-resolution depth from various types of depth sensors, are increasingly common. One can significantly improve the resolution of depth images by taking advantage of color information; deep learning methods make combining color and depth information particularly easy. However, fusing these two sources of data may lead to a variety of artifacts. If depth maps are used to reconstruct 3D shapes, e.g., for virtual reality applications, the visual quality of upsampled images is particularly important. To achieve high-quality results, visual metric need to be taken into account. The main idea of our approach is to measure the quality of depth map upsampling using renderings of resulting 3D surfaces. We demonstrate that a simple visual appearance-based loss, when used with either a trained CNN or simply a deep prior, yields significantly improved 3D shapes, as measured by a number of existing perceptual metrics. We compare this approach with a number of existing optimization and learning-based techniques.
The Training of Neuromodels for Machine Comprehension of Text. Brain2Text Algorithm
Mar 30, 2018


Nowadays, the Internet represents a vast informational space, growing exponentially and the problem of search for relevant data becomes essential as never before. The algorithm proposed in the article allows to perform natural language queries on content of the document and get comprehensive meaningful answers. The problem is partially solved for English as SQuAD contains enough data to learn on, but there is no such dataset in Russian, so the methods used by scientists now are not applicable to Russian. Brain2 framework allows to cope with the problem - it stands out for its ability to be applied on small datasets and does not require impressive computing power. The algorithm is illustrated on Sberbank of Russia Strategy's text and assumes the use of a neuromodel consisting of 65 mln synapses. The trained model is able to construct word-by-word answers to questions based on a given text. The existing limitations are its current inability to identify synonyms, pronoun relations and allegories. Nevertheless, the results of conducted experiments showed high capacity and generalisation ability of the suggested approach.