 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Frontier: Stochastic Backtracking for Efficient Test-Time Scaling
May 24, 2026Test-time scaling improves language model reasoning by spending additional compute to explore multiple solution trajectories. The key challenge is to maximize accuracy while minimizing the total number of generated tokens during reasoning. Recent PRM-guided methods score intermediate prefixes to steer this search, but most are frontier-only: they keep only the current active prefixes and irreversibly prune or resample away the rest using noisy PRM scores. This can cause premature commitment, diversity collapse, and the loss of prefixes that still admit correct continuations. We introduce stochastic backtracking over a persistent pool of historical prefixes, allowing test-time compute to revisit previously generated states instead of only expanding the current frontier. To make this efficient, we propose two complementary mechanisms. Subpool Selection strengthens greedy PRM-guided search by applying Top-N selection within random subpools, giving historical prefixes a chance to bypass over-scored frontier candidates. Power Backtrack Sequential Monte Carlo extends SMC-style resampling to the persistent pool using powered PRM scores and mixture-corrected weights. Across mathematical reasoning benchmarks and model scales, our methods consistently achieve higher accuracy per token count, and the same level of accuracy using only a fraction of the token count in comparison to strong PRM-guided baselines, demonstrating that persistent-pool stochastic backtracking provides a simple and effective way to improve the accuracy-token trade-off in test-time scaling.
Selective Off-Policy Reference Tuning with Plan Guidance
May 13, 2026Reinforcement learning with verifiable rewards helps reasoning, but GRPO-style methods stall on hard prompts where all sampled rollouts fail. SORT adds a repair update for those failures without changing rollout generation: it derives a plan from the reference solution, compares token probabilities with and without that plan, and gives higher weight to tokens that become more predictable under plan conditioning. This turns all-wrong prompts into selective, structure-aware learning signals instead of uniform imitation. Across three backbones and eight reasoning benchmarks, SORT improves over GRPO and guidance baselines, with largest gains on weaker models.
SAFL: A Self-Attention Scene Text Recognizer with Focal Loss
Jan 01, 2022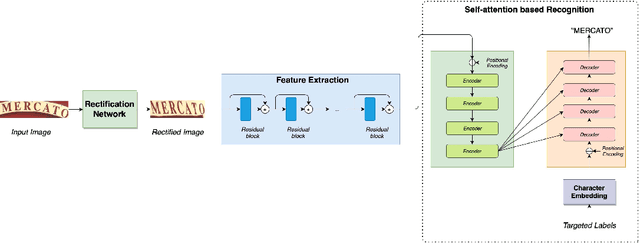
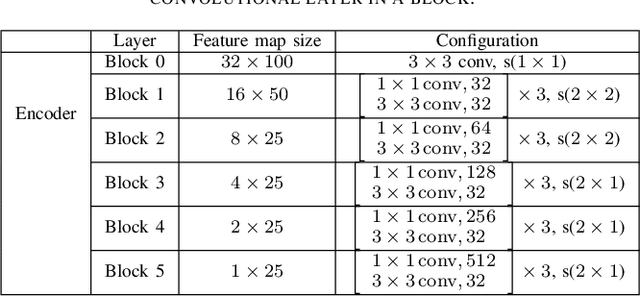

In the last decades, scene text recognition has gained worldwide attention from both the academic community and actual users due to its importance in a wide range of applications. Despite achievements in optical character recognition, scene text recognition remains challenging due to inherent problems such as distortions or irregular layout. Most of the existing approaches mainly leverage recurrence or convolution-based neural networks. However, while recurrent neural networks (RNNs) usually suffer from slow training speed due to sequential computation and encounter problems as vanishing gradient or bottleneck, CNN endures a trade-off between complexity and performance. In this paper, we introduce SAFL, a self-attention-based neural network model with the focal loss for scene text recognition, to overcome the limitation of the existing approaches. The use of focal loss instead of negative log-likelihood helps the model focus more on low-frequency samples training. Moreover, to deal with the distortions and irregular texts, we exploit Spatial TransformerNetwork (STN) to rectify text before passing to the recognition network. We perform experiments to compare the performance of the proposed model with seven benchmarks. The numerical results show that our model achieves the best performance.
* Accepted to ICMLA 2020