 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScisummNet: A Large Annotated Corpus and Content-Impact Models for Scientific Paper Summarization with Citation Networks
Sep 16, 2019
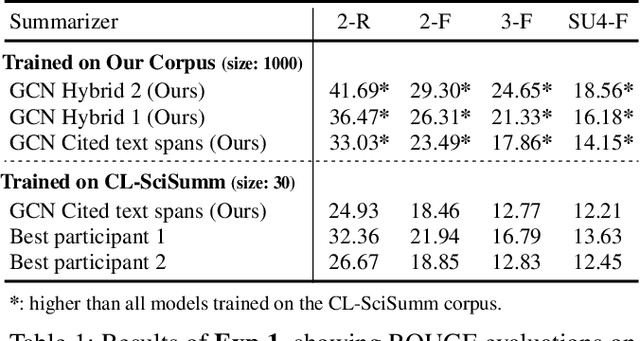
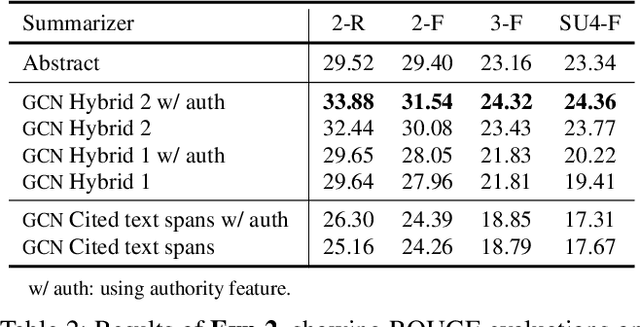
Scientific article summarization is challenging: large, annotated corpora are not available, and the summary should ideally include the article's impacts on research community. This paper provides novel solutions to these two challenges. We 1) develop and release the first large-scale manually-annotated corpus for scientific papers (on computational linguistics) by enabling faster annotation, and 2) propose summarization methods that integrate the authors' original highlights (abstract) and the article's actual impacts on the community (citations), to create comprehensive, hybrid summaries. We conduct experiments to demonstrate the efficacy of our corpus in training data-driven models for scientific paper summarization and the advantage of our hybrid summaries over abstracts and traditional citation-based summaries. Our large annotated corpus and hybrid methods provide a new framework for scientific paper summarization research.
Multi-News: a Large-Scale Multi-Document Summarization Dataset and Abstractive Hierarchical Model
Jun 19, 2019
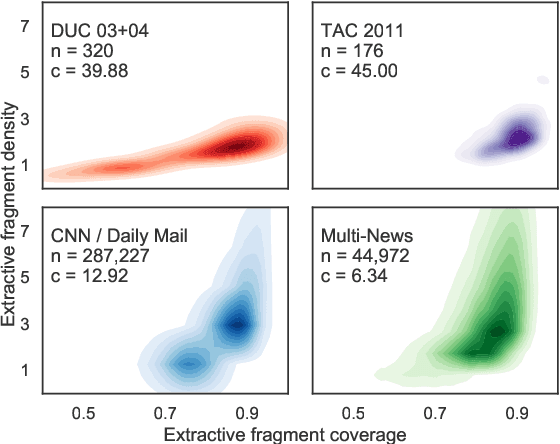
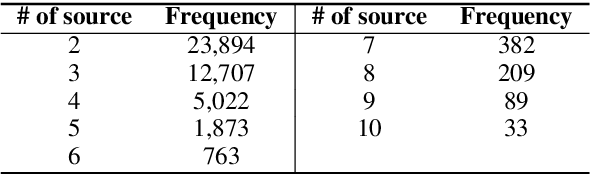
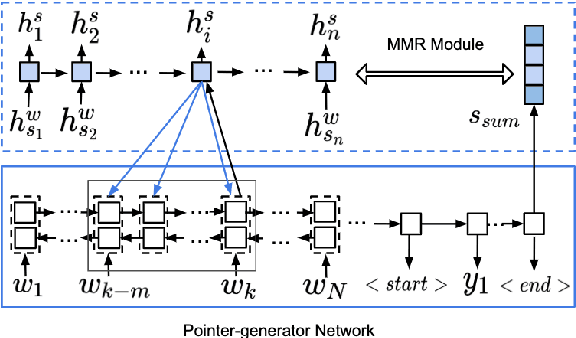
Automatic generation of summaries from multiple news articles is a valuable tool as the number of online publications grows rapidly. Single document summarization (SDS) systems have benefited from advances in neural encoder-decoder model thanks to the availability of large datasets. However, multi-document summarization (MDS) of news articles has been limited to datasets of a couple of hundred examples. In this paper, we introduce Multi-News, the first large-scale MDS news dataset. Additionally, we propose an end-to-end model which incorporates a traditional extractive summarization model with a standard SDS model and achieves competitive results on MDS datasets. We benchmark several methods on Multi-News and release our data and code in hope that this work will promote advances in summarization in the multi-document setting.
What Should I Learn First: Introducing LectureBank for NLP Education and Prerequisite Chain Learning
Nov 26, 2018
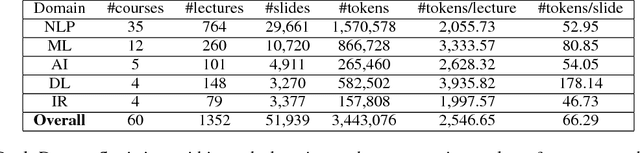
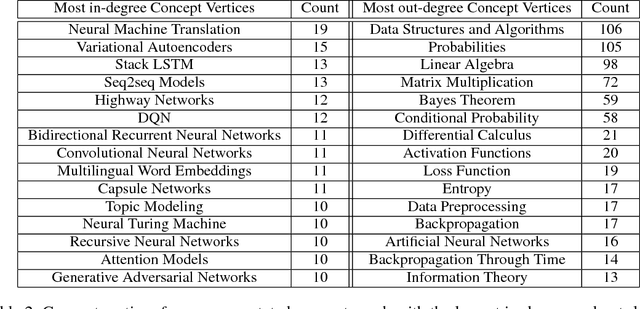

Recent years have witnessed the rising popularity of Natural Language Processing (NLP) and related fields such as Artificial Intelligence (AI) and Machine Learning (ML). Many online courses and resources are available even for those without a strong background in the field. Often the student is curious about a specific topic but does not quite know where to begin studying. To answer the question of "what should one learn first," we apply an embedding-based method to learn prerequisite relations for course concepts in the domain of NLP. We introduce LectureBank, a dataset containing 1,352 English lecture files collected from university courses which are each classified according to an existing taxonomy as well as 208 manually-labeled prerequisite relation topics, which is publicly available. The dataset will be useful for educational purposes such as lecture preparation and organization as well as applications such as reading list generation. Additionally, we experiment with neural graph-based networks and non-neural classifiers to learn these prerequisite relations from our dataset.
Zero-shot Transfer Learning for Semantic Parsing
Aug 27, 2018
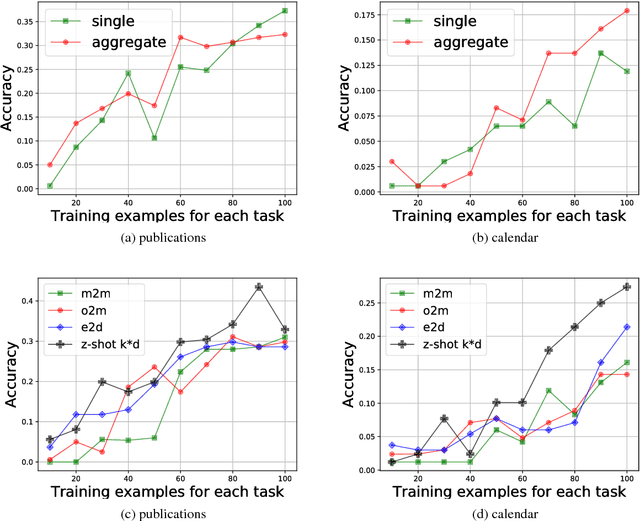
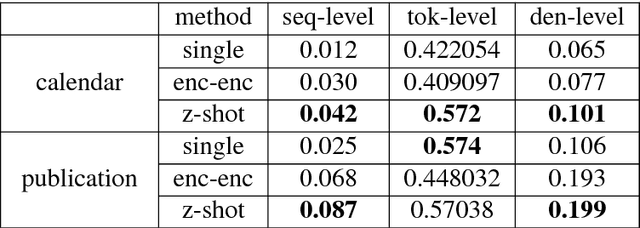
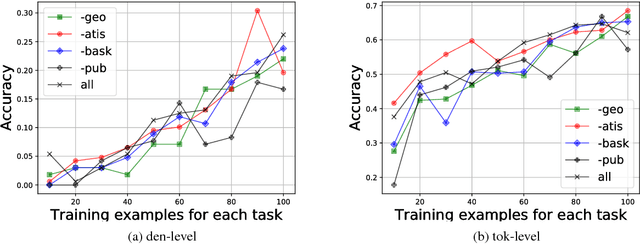
While neural networks have shown impressive performance on large datasets, applying these models to tasks where little data is available remains a challenging problem. In this paper we propose to use feature transfer in a zero-shot experimental setting on the task of semantic parsing. We first introduce a new method for learning the shared space between multiple domains based on the prediction of the domain label for each example. Our experiments support the superiority of this method in a zero-shot experimental setting in terms of accuracy metrics compared to state-of-the-art techniques. In the second part of this paper we study the impact of individual domains and examples on semantic parsing performance. We use influence functions to this aim and investigate the sensitivity of domain-label classification loss on each example. Our findings reveal that cross-domain adversarial attacks identify useful examples for training even from the domains the least similar to the target domain. Augmenting our training data with these influential examples further boosts our accuracy at both the token and the sequence level.
TutorialBank: A Manually-Collected Corpus for Prerequisite Chains, Survey Extraction and Resource Recommendation
May 11, 2018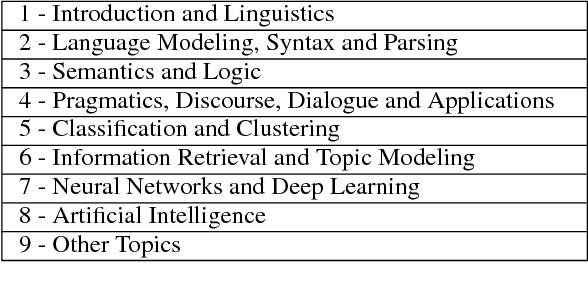

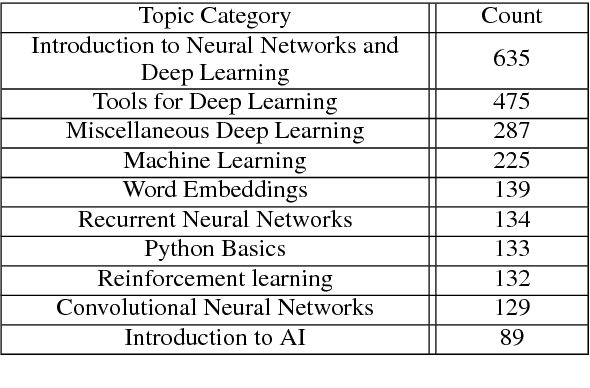

The field of Natural Language Processing (NLP) is growing rapidly, with new research published daily along with an abundance of tutorials, codebases and other online resources. In order to learn this dynamic field or stay up-to-date on the latest research, students as well as educators and researchers must constantly sift through multiple sources to find valuable, relevant information. To address this situation, we introduce TutorialBank, a new, publicly available dataset which aims to facilitate NLP education and research. We have manually collected and categorized over 6,300 resources on NLP as well as the related fields of Artificial Intelligence (AI), Machine Learning (ML) and Information Retrieval (IR). Our dataset is notably the largest manually-picked corpus of resources intended for NLP education which does not include only academic papers. Additionally, we have created both a search engine and a command-line tool for the resources and have annotated the corpus to include lists of research topics, relevant resources for each topic, prerequisite relations among topics, relevant sub-parts of individual resources, among other annotations. We are releasing the dataset and present several avenues for further research.
Generating Extractive Summaries of Scientific Paradigms
Feb 04, 2014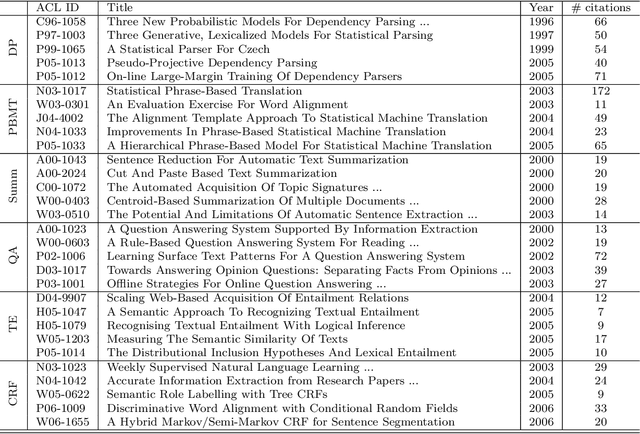
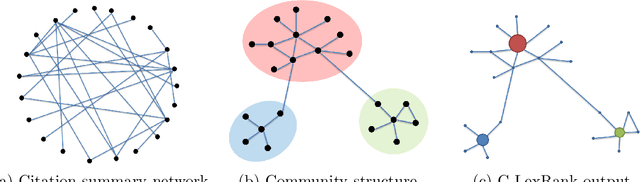

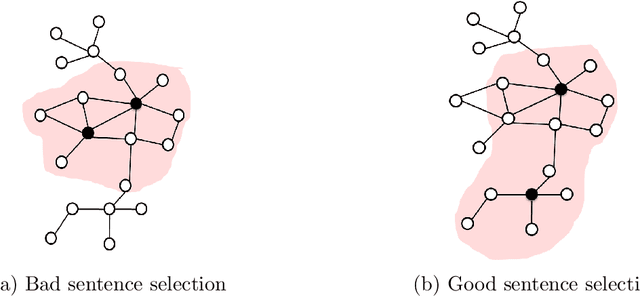
Researchers and scientists increasingly find themselves in the position of having to quickly understand large amounts of technical material. Our goal is to effectively serve this need by using bibliometric text mining and summarization techniques to generate summaries of scientific literature. We show how we can use citations to produce automatically generated, readily consumable, technical extractive summaries. We first propose C-LexRank, a model for summarizing single scientific articles based on citations, which employs community detection and extracts salient information-rich sentences. Next, we further extend our experiments to summarize a set of papers, which cover the same scientific topic. We generate extractive summaries of a set of Question Answering (QA) and Dependency Parsing (DP) papers, their abstracts, and their citation sentences and show that citations have unique information amenable to creating a summary.
A Computational Analysis of Collective Discourse
Apr 17, 2012
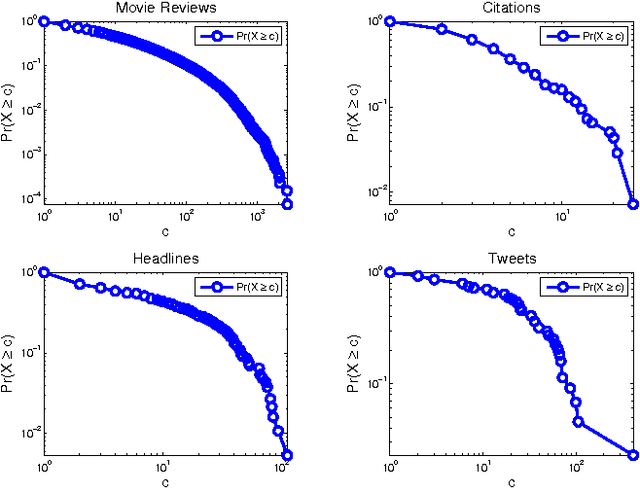
This paper is focused on the computational analysis of collective discourse, a collective behavior seen in non-expert content contributions in online social media. We collect and analyze a wide range of real-world collective discourse datasets from movie user reviews to microblogs and news headlines to scientific citations. We show that all these datasets exhibit diversity of perspective, a property seen in other collective systems and a criterion in wise crowds. Our experiments also confirm that the network of different perspective co-occurrences exhibits the small-world property with high clustering of different perspectives. Finally, we show that non-expert contributions in collective discourse can be used to answer simple questions that are otherwise hard to answer.
LexRank: Graph-based Lexical Centrality as Salience in Text Summarization
Sep 26, 2011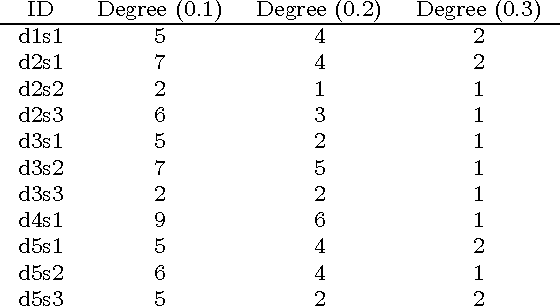

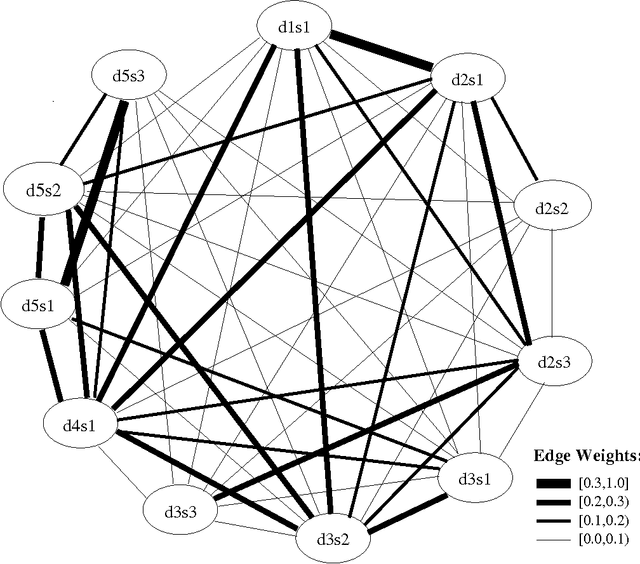
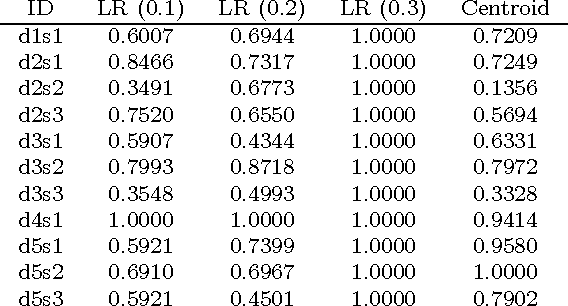
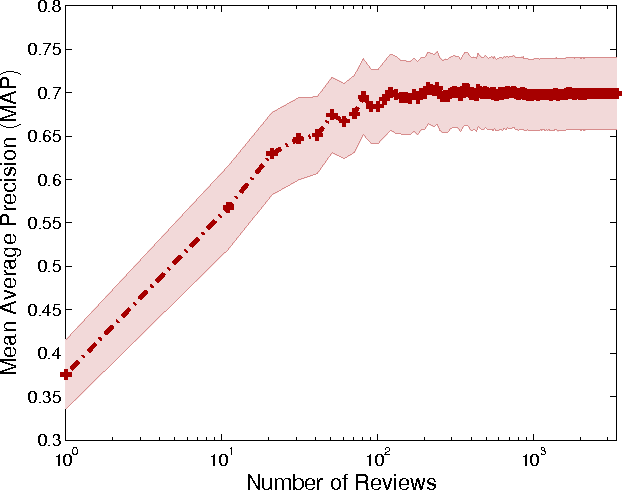
We introduce a stochastic graph-based method for computing relative importance of textual units for Natural Language Processing. We test the technique on the problem of Text Summarization (TS). Extractive TS relies on the concept of sentence salience to identify the most important sentences in a document or set of documents. Salience is typically defined in terms of the presence of particular important words or in terms of similarity to a centroid pseudo-sentence. We consider a new approach, LexRank, for computing sentence importance based on the concept of eigenvector centrality in a graph representation of sentences. In this model, a connectivity matrix based on intra-sentence cosine similarity is used as the adjacency matrix of the graph representation of sentences. Our system, based on LexRank ranked in first place in more than one task in the recent DUC 2004 evaluation. In this paper we present a detailed analysis of our approach and apply it to a larger data set including data from earlier DUC evaluations. We discuss several methods to compute centrality using the similarity graph. The results show that degree-based methods (including LexRank) outperform both centroid-based methods and other systems participating in DUC in most of the cases. Furthermore, the LexRank with threshold method outperforms the other degree-based techniques including continuous LexRank. We also show that our approach is quite insensitive to the noise in the data that may result from an imperfect topical clustering of documents.
Scientific Paper Summarization Using Citation Summary Networks
Jul 10, 2008
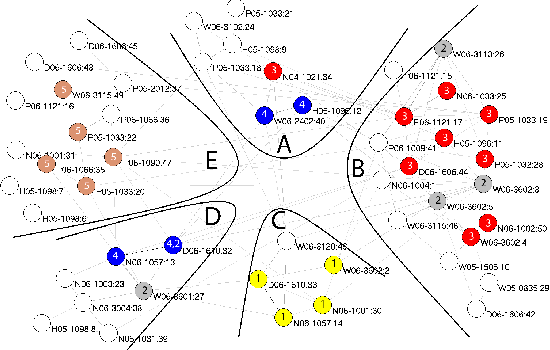
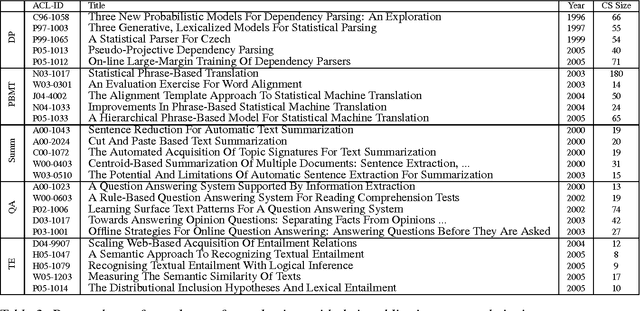
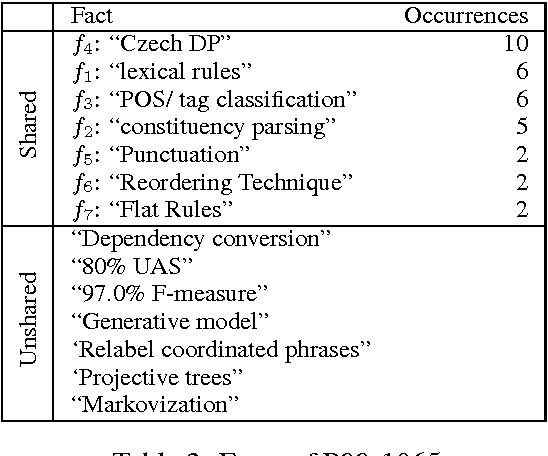
Quickly moving to a new area of research is painful for researchers due to the vast amount of scientific literature in each field of study. One possible way to overcome this problem is to summarize a scientific topic. In this paper, we propose a model of summarizing a single article, which can be further used to summarize an entire topic. Our model is based on analyzing others' viewpoint of the target article's contributions and the study of its citation summary network using a clustering approach.
Ranking suspected answers to natural language questions using predictive annotation
May 30, 2000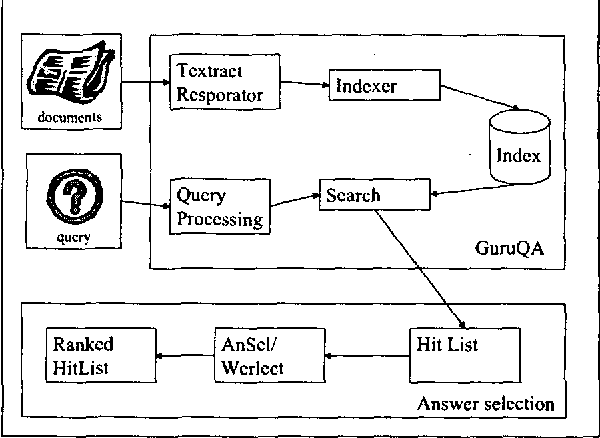
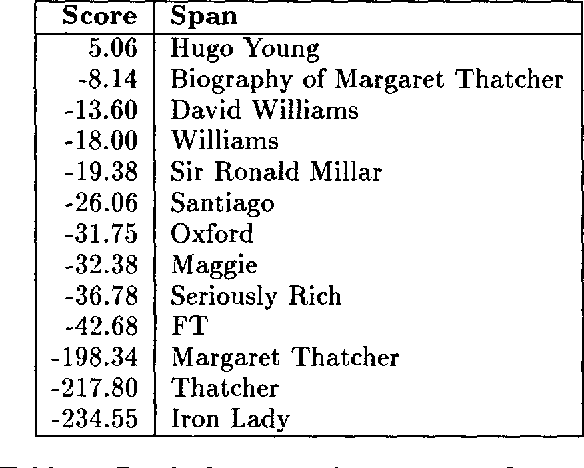

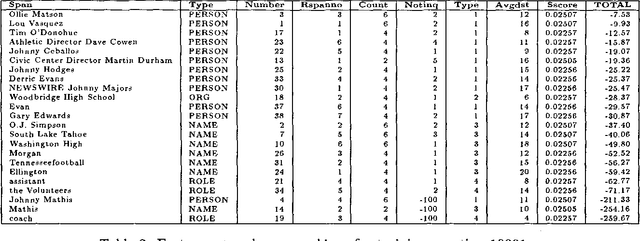
In this paper, we describe a system to rank suspected answers to natural language questions. We process both corpus and query using a new technique, predictive annotation, which augments phrases in texts with labels anticipating their being targets of certain kinds of questions. Given a natural language question, an IR system returns a set of matching passages, which are then analyzed and ranked according to various criteria described in this paper. We provide an evaluation of the techniques based on results from the TREC Q&A evaluation in which our system participated.
* 8 pages