 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency Guided Adversarial Training for Learning Generalizable Features with Applications to Medical Imaging Classification System
Sep 09, 2022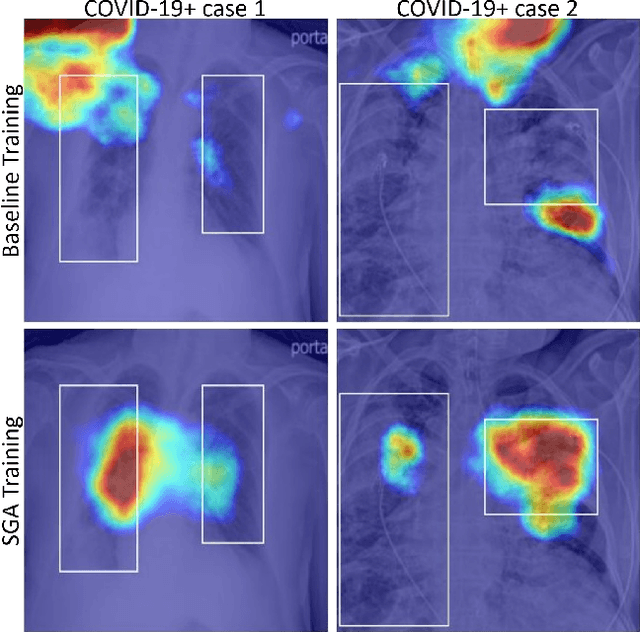
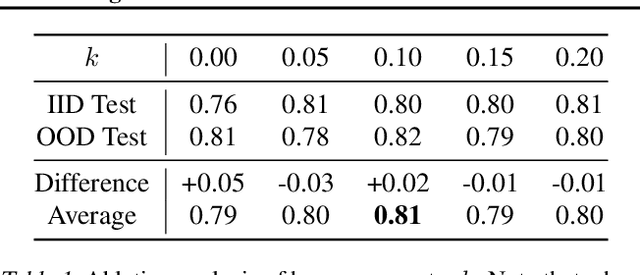
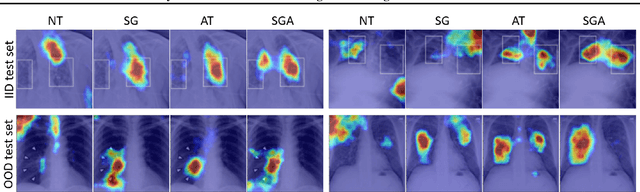
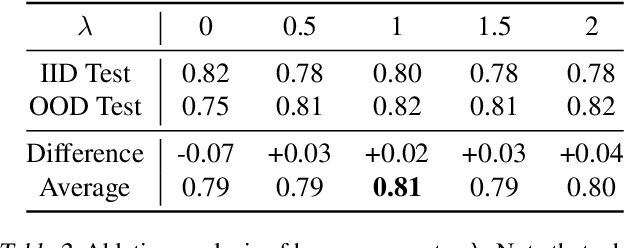
This work tackles a central machine learning problem of performance degradation on out-of-distribution (OOD) test sets. The problem is particularly salient in medical imaging based diagnosis system that appears to be accurate but fails when tested in new hospitals/datasets. Recent studies indicate the system might learn shortcut and non-relevant features instead of generalizable features, so-called good features. We hypothesize that adversarial training can eliminate shortcut features whereas saliency guided training can filter out non-relevant features; both are nuisance features accounting for the performance degradation on OOD test sets. With that, we formulate a novel model training scheme for the deep neural network to learn good features for classification and/or detection tasks ensuring a consistent generalization performance on OOD test sets. The experimental results qualitatively and quantitatively demonstrate the superior performance of our method using the benchmark CXR image data sets on classification tasks.
* 9 pages, 3 figures
Adversarially Robust and Explainable Model Compression with On-Device Personalization for Text Classification
Jan 20, 2021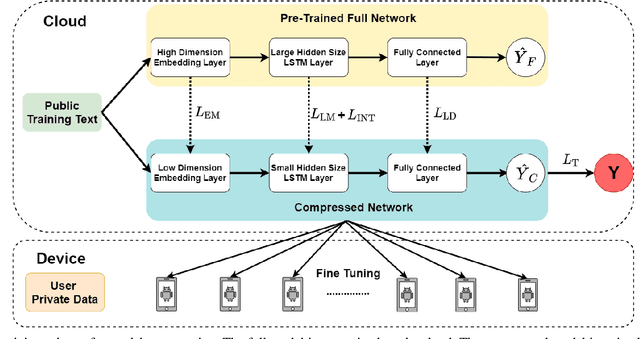
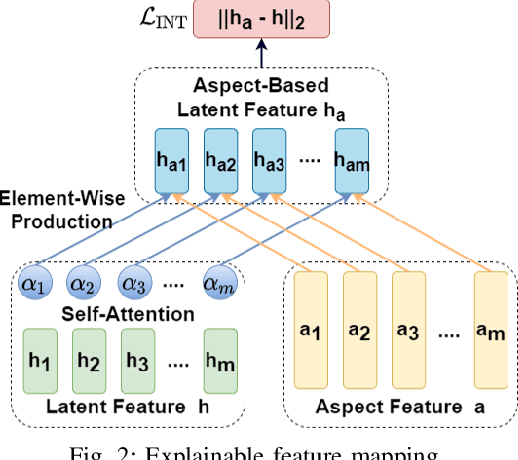
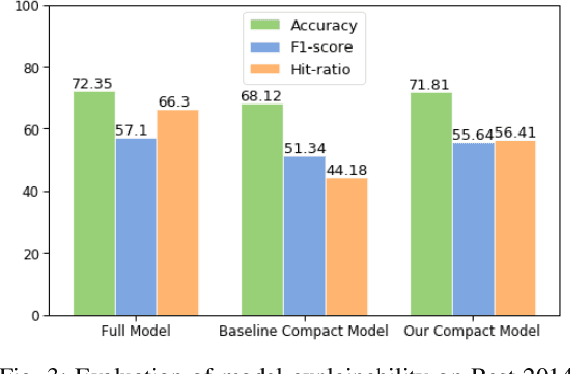
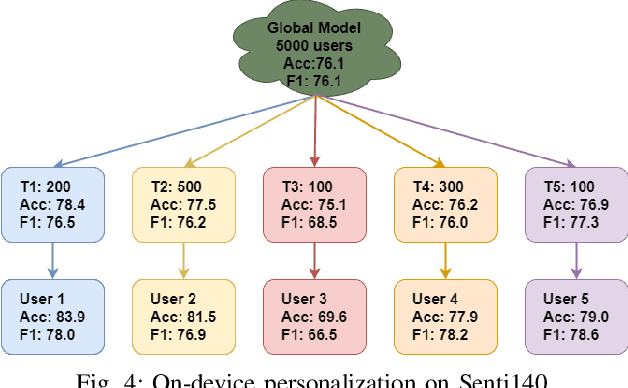
On-device Deep Neural Networks (DNNs) have recently gained more attention due to the increasing computing power of the mobile devices and the number of applications in Computer Vision (CV), Natural Language Processing (NLP), and Internet of Things (IoTs). Unfortunately, the existing efficient convolutional neural network (CNN) architectures designed for CV tasks are not directly applicable to NLP tasks and the tiny Recurrent Neural Network (RNN) architectures have been designed primarily for IoT applications. In NLP applications, although model compression has seen initial success in on-device text classification, there are at least three major challenges yet to be addressed: adversarial robustness, explainability, and personalization. Here we attempt to tackle these challenges by designing a new training scheme for model compression and adversarial robustness, including the optimization of an explainable feature mapping objective, a knowledge distillation objective, and an adversarially robustness objective. The resulting compressed model is personalized using on-device private training data via fine-tuning. We perform extensive experiments to compare our approach with both compact RNN (e.g., FastGRNN) and compressed RNN (e.g., PRADO) architectures in both natural and adversarial NLP test settings.
Improving Adversarial Robustness via Probabilistically Compact Loss with Logit Constraints
Dec 14, 2020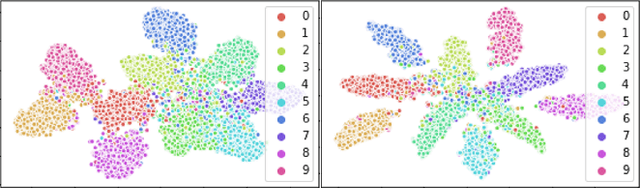
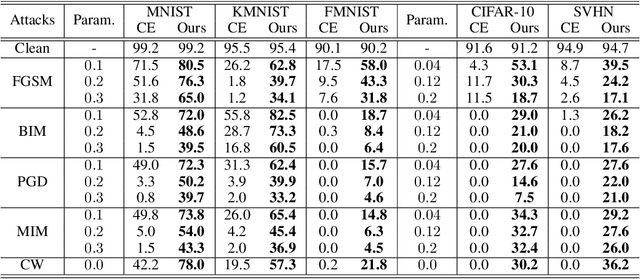
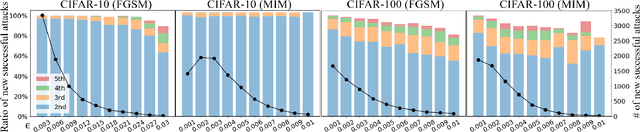
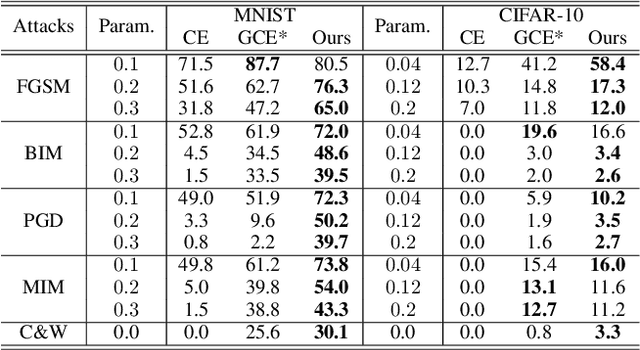
Convolutional neural networks (CNNs) have achieved state-of-the-art performance on various tasks in computer vision. However, recent studies demonstrate that these models are vulnerable to carefully crafted adversarial samples and suffer from a significant performance drop when predicting them. Many methods have been proposed to improve adversarial robustness (e.g., adversarial training and new loss functions to learn adversarially robust feature representations). Here we offer a unique insight into the predictive behavior of CNNs that they tend to misclassify adversarial samples into the most probable false classes. This inspires us to propose a new Probabilistically Compact (PC) loss with logit constraints which can be used as a drop-in replacement for cross-entropy (CE) loss to improve CNN's adversarial robustness. Specifically, PC loss enlarges the probability gaps between true class and false classes meanwhile the logit constraints prevent the gaps from being melted by a small perturbation. We extensively compare our method with the state-of-the-art using large scale datasets under both white-box and black-box attacks to demonstrate its effectiveness. The source codes are available from the following url: https://github.com/xinli0928/PC-LC.
Explainable Recommendation via Interpretable Feature Mapping and Evaluation of Explainability
Jul 12, 2020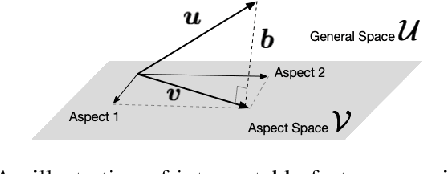
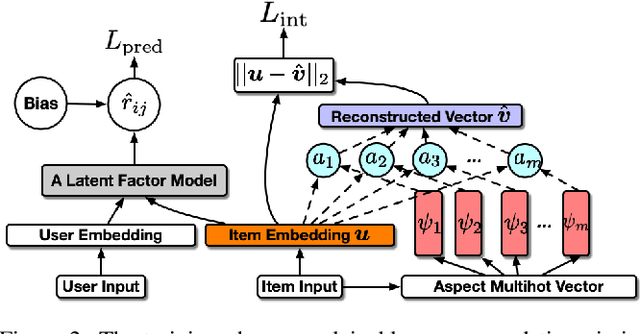

Latent factor collaborative filtering (CF) has been a widely used technique for recommender system by learning the semantic representations of users and items. Recently, explainable recommendation has attracted much attention from research community. However, trade-off exists between explainability and performance of the recommendation where metadata is often needed to alleviate the dilemma. We present a novel feature mapping approach that maps the uninterpretable general features onto the interpretable aspect features, achieving both satisfactory accuracy and explainability in the recommendations by simultaneous minimization of rating prediction loss and interpretation loss. To evaluate the explainability, we propose two new evaluation metrics specifically designed for aspect-level explanation using surrogate ground truth. Experimental results demonstrate a strong performance in both recommendation and explaining explanation, eliminating the need for metadata. Code is available from https://github.com/pd90506/AMCF.
* Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI)
Defending against adversarial attacks on medical imaging AI system, classification or detection?
Jun 24, 2020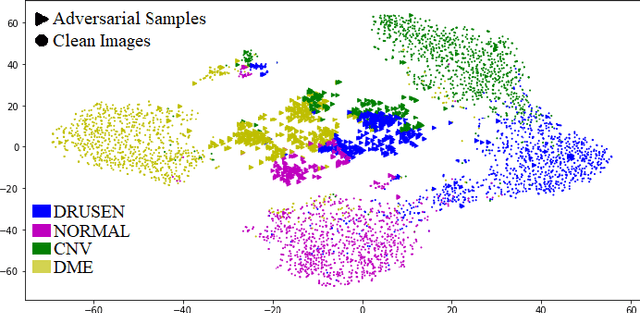
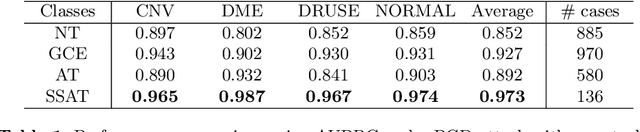
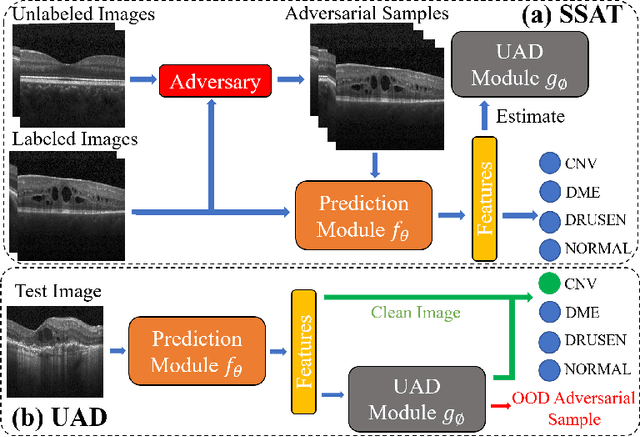

Medical imaging AI systems such as disease classification and segmentation are increasingly inspired and transformed from computer vision based AI systems. Although an array of adversarial training and/or loss function based defense techniques have been developed and proved to be effective in computer vision, defending against adversarial attacks on medical images remains largely an uncharted territory due to the following unique challenges: 1) label scarcity in medical images significantly limits adversarial generalizability of the AI system; 2) vastly similar and dominant fore- and background in medical images make it hard samples for learning the discriminating features between different disease classes; and 3) crafted adversarial noises added to the entire medical image as opposed to the focused organ target can make clean and adversarial examples more discriminate than that between different disease classes. In this paper, we propose a novel robust medical imaging AI framework based on Semi-Supervised Adversarial Training (SSAT) and Unsupervised Adversarial Detection (UAD), followed by designing a new measure for assessing systems adversarial risk. We systematically demonstrate the advantages of our robust medical imaging AI system over the existing adversarial defense techniques under diverse real-world settings of adversarial attacks using a benchmark OCT imaging data set.
COVID-MobileXpert: On-Device COVID-19 Screening using Snapshots of Chest X-Ray
Apr 13, 2020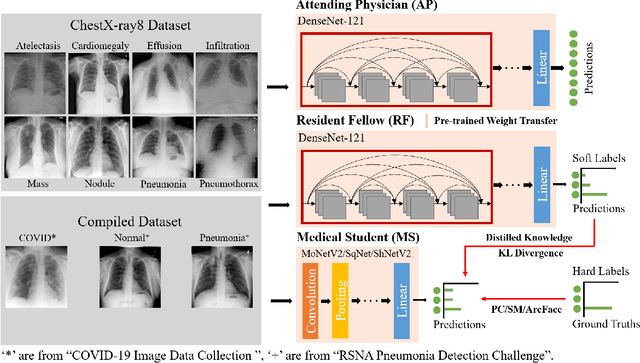
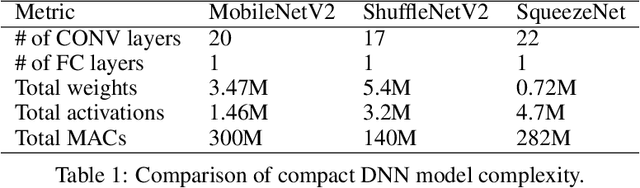
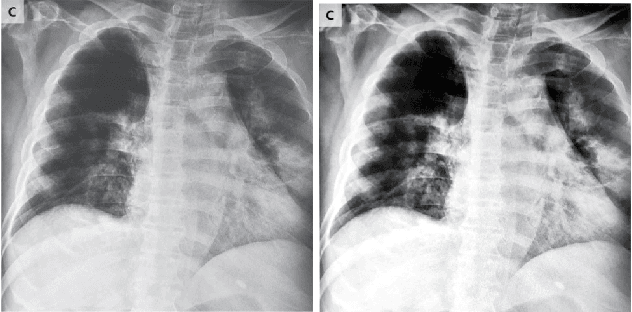

With the increasing demand for millions of COVID-19 screenings, Computed Tomography (CT) based test has emerged as a promising alternative to the gold standard RT-PCR test. However, it is primarily provided in hospital setting due to the need for expensive equipment and experienced radiologists. An accurate, rapid yet inexpensive test that is suitable for COVID-19 population screenings at mobile, urgent and primary care clinics is urgently needed. We present COVID-MobileXpert: a lightweight deep neural network (DNN) based mobile app that can use noisy snapshots of chest X-ray (CXR) for point-of-care COVID-19 screening. We design and implement a novel three-player knowledge transfer and distillation (KTD) framework including a pre-trained attending physician (AP) network that extracts CXR imaging features from large scale of lung disease CXR images, a fine-tuned resident fellow (RF) network that learns the essential CXR imaging features to discriminate COVID-19 from pneumonia and/or normal cases using a small amount of COVID-19 cases, and a trained lightweight medical student (MS) network that performs on-device COVID-19 screening. To accommodate the need for screening using noisy snapshots of CXR images, we employ novel loss functions and training schemes for the MS network to learn the robust imaging features for accurate on-device COVID-19 screening. We demonstrate the strong potential of COVID-MobileXpert for rapid deployment via extensive experiments with diverse MS network architecture, CXR imaging quality, and tuning parameter settings. The source code of cloud and mobile based models are available from https://github.com/xinli0928/COVID-Xray.
Toward Tag-free Aspect Based Sentiment Analysis: A Multiple Attention Network Approach
Mar 22, 2020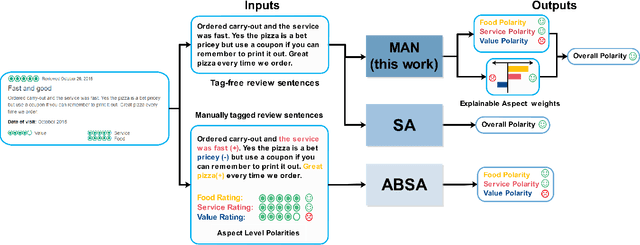
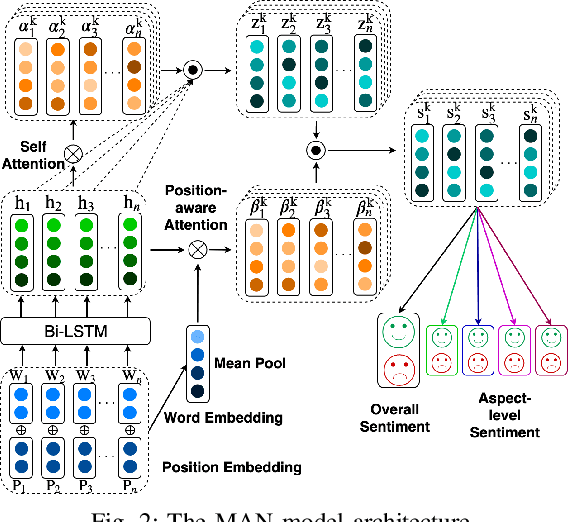
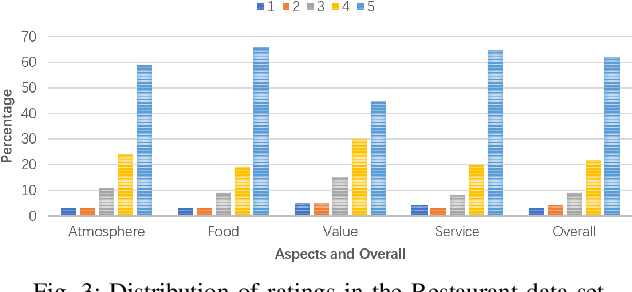
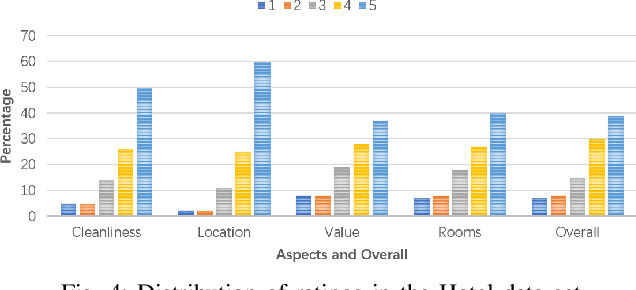
Existing aspect based sentiment analysis (ABSA) approaches leverage various neural network models to extract the aspect sentiments via learning aspect-specific feature representations. However, these approaches heavily rely on manual tagging of user reviews according to the predefined aspects as the input, a laborious and time-consuming process. Moreover, the underlying methods do not explain how and why the opposing aspect level polarities in a user review lead to the overall polarity. In this paper, we tackle these two problems by designing and implementing a new Multiple-Attention Network (MAN) approach for more powerful ABSA without the need for aspect tags using two new tag-free data sets crawled directly from TripAdvisor ({https://www.tripadvisor.com}). With the Self- and Position-Aware attention mechanism, MAN is capable of extracting both aspect level and overall sentiments from the text reviews using the aspect level and overall customer ratings, and it can also detect the vital aspect(s) leading to the overall sentiment polarity among different aspects via a new aspect ranking scheme. We carry out extensive experiments to demonstrate the strong performance of MAN compared to other state-of-the-art ABSA approaches and the explainability of our approach by visualizing and interpreting attention weights in case studies.
On the Learning Property of Logistic and Softmax Losses for Deep Neural Networks
Mar 04, 2020
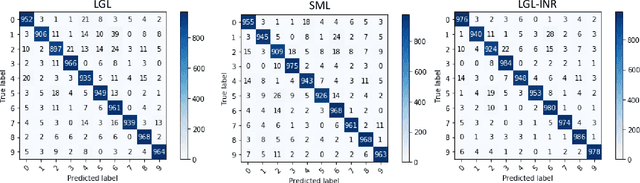

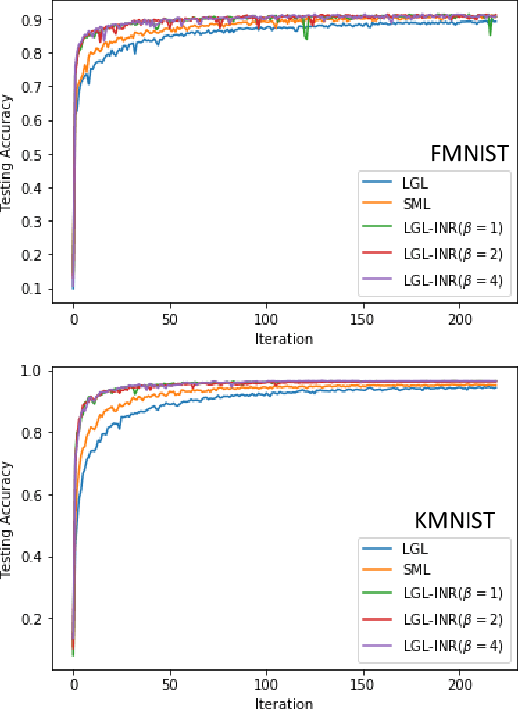
Deep convolutional neural networks (CNNs) trained with logistic and softmax losses have made significant advancement in visual recognition tasks in computer vision. When training data exhibit class imbalances, the class-wise reweighted version of logistic and softmax losses are often used to boost performance of the unweighted version. In this paper, motivated to explain the reweighting mechanism, we explicate the learning property of those two loss functions by analyzing the necessary condition (e.g., gradient equals to zero) after training CNNs to converge to a local minimum. The analysis immediately provides us explanations for understanding (1) quantitative effects of the class-wise reweighting mechanism: deterministic effectiveness for binary classification using logistic loss yet indeterministic for multi-class classification using softmax loss; (2) disadvantage of logistic loss for single-label multi-class classification via one-vs.-all approach, which is due to the averaging effect on predicted probabilities for the negative class (e.g., non-target classes) in the learning process. With the disadvantage and advantage of logistic loss disentangled, we thereafter propose a novel reweighted logistic loss for multi-class classification. Our simple yet effective formulation improves ordinary logistic loss by focusing on learning hard non-target classes (target vs. non-target class in one-vs.-all) and turned out to be competitive with softmax loss. We evaluate our method on several benchmark datasets to demonstrate its effectiveness.
Improve SGD Training via Aligning Mini-batches
Feb 27, 2020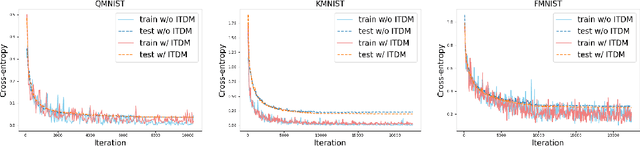
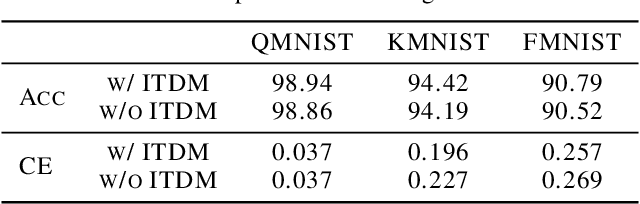
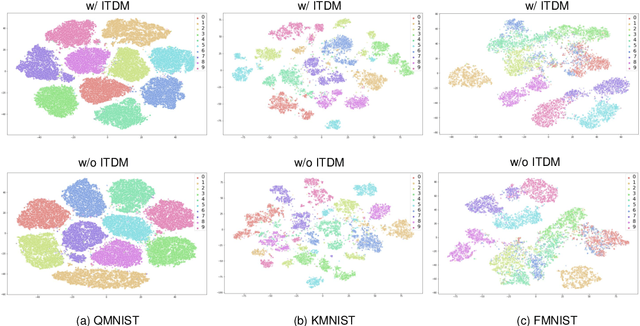
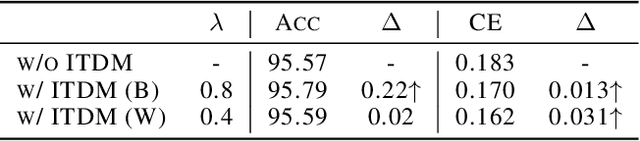
Deep neural networks (DNNs) for supervised learning can be viewed as a pipeline of a feature extractor (i.e. last hidden layer) and a linear classifier (i.e. output layer) that is trained jointly with stochastic gradient descent (SGD). In each iteration of SGD, a mini-batch from the training data is sampled and the true gradient of the loss function is estimated as the noisy gradient calculated on this mini-batch. From the feature learning perspective, the feature extractor should be updated to learn meaningful features with respect to the entire data, and reduce the accommodation to noise in the mini-batch. With this motivation, we propose In-Training Distribution Matching (ITDM) to improve DNN training and reduce overfitting. Specifically, along with the loss function, ITDM regularizes the feature extractor by matching the moments of distributions of different mini-batches in each iteration of SGD, which is fulfilled by minimizing the maximum mean discrepancy. As such, ITDM does not assume any explicit parametric form of data distribution in the latent feature space. Extensive experiments are conducted to demonstrate the effectiveness of our proposed strategy.
Representation Learning with Autoencoders for Electronic Health Records: A Comparative Study
Sep 20, 2019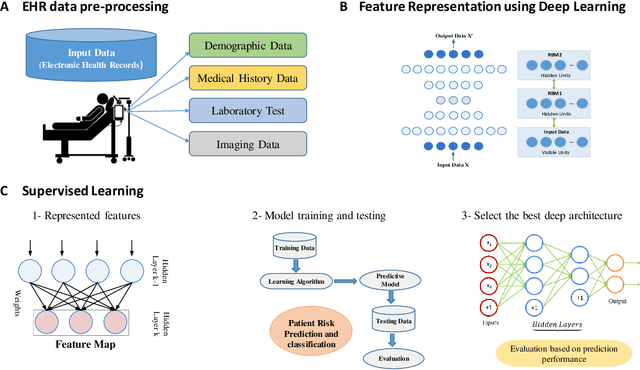
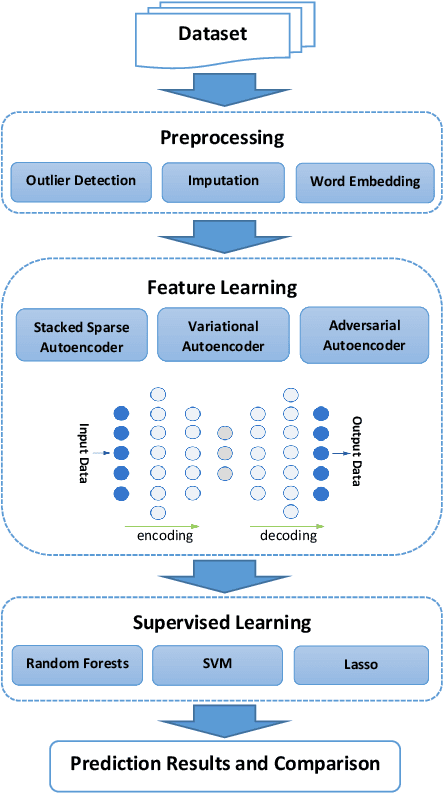
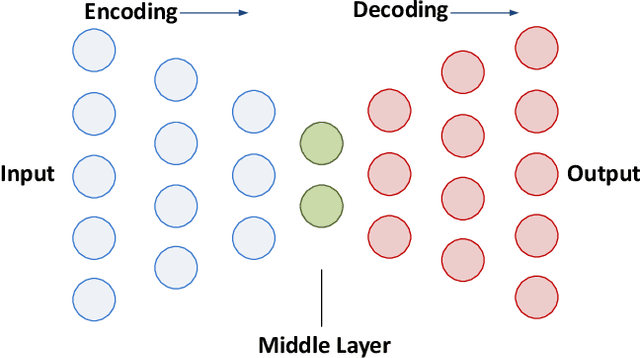
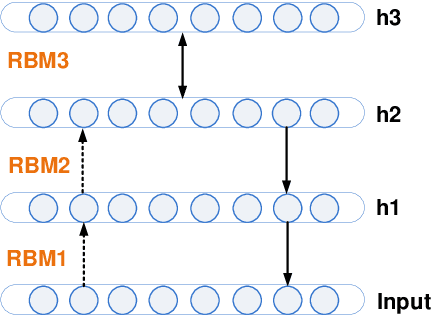
Increasing volume of Electronic Health Records (EHR) in recent years provides great opportunities for data scientists to collaborate on different aspects of healthcare research by applying advanced analytics to these EHR clinical data. A key requirement however is obtaining meaningful insights from high dimensional, sparse and complex clinical data. Data science approaches typically address this challenge by performing feature learning in order to build more reliable and informative feature representations from clinical data followed by supervised learning. In this paper, we propose a predictive modeling approach based on deep learning based feature representations and word embedding techniques. Our method uses different deep architectures (stacked sparse autoencoders, deep belief network, adversarial autoencoders and variational autoencoders) for feature representation in higher-level abstraction to obtain effective and robust features from EHRs, and then build prediction models on top of them. Our approach is particularly useful when the unlabeled data is abundant whereas labeled data is scarce. We investigate the performance of representation learning through a supervised learning approach. Our focus is to present a comparative study to evaluate the performance of different deep architectures through supervised learning and provide insights in the choice of deep feature representation techniques. Our experiments demonstrate that for small data sets, stacked sparse autoencoder demonstrates a superior generality performance in prediction due to sparsity regularization whereas variational autoencoders outperform the competing approaches for large data sets due to its capability of learning the representation distribution