 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoCov: Semi-Orthogonal Parametric Pooling of Covariance Matrix for Speaker Recognition
Apr 23, 2025In conventional deep speaker embedding frameworks, the pooling layer aggregates all frame-level features over time and computes their mean and standard deviation statistics as inputs to subsequent segment-level layers. Such statistics pooling strategy produces fixed-length representations from variable-length speech segments. However, this method treats different frame-level features equally and discards covariance information. In this paper, we propose the Semi-orthogonal parameter pooling of Covariance matrix (SoCov) method. The SoCov pooling computes the covariance matrix from the self-attentive frame-level features and compresses it into a vector using the semi-orthogonal parametric vectorization, which is then concatenated with the weighted standard deviation vector to form inputs to the segment-level layers. Deep embedding based on SoCov is called ``sc-vector''. The proposed sc-vector is compared to several different baselines on the SRE21 development and evaluation sets. The sc-vector system significantly outperforms the conventional x-vector system, with a relative reduction in EER of 15.5% on SRE21Eval. When using self-attentive deep feature, SoCov helps to reduce EER on SRE21Eval by about 30.9% relatively to the conventional ``mean + standard deviation'' statistics.
The CORAL++ Algorithm for Unsupervised Domain Adaptation of Speaker Recogntion
Feb 02, 2022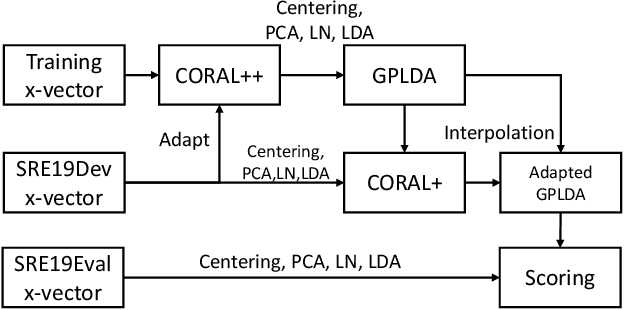


State-of-the-art speaker recognition systems are trained with a large amount of human-labeled training data set. Such a training set is usually composed of various data sources to enhance the modeling capability of models. However, in practical deployment, unseen condition is almost inevitable. Domain mismatch is a common problem in real-life applications due to the statistical difference between the training and testing data sets. To alleviate the degradation caused by domain mismatch, we propose a new feature-based unsupervised domain adaptation algorithm. The algorithm we propose is a further optimization based on the well-known CORrelation ALignment (CORAL), so we call it CORAL++. On the NIST 2019 Speaker Recognition Evaluation (SRE19), we use SRE18 CTS set as the development set to verify the effectiveness of CORAL++. With the typical x-vector/PLDA setup, the CORAL++ outperforms the CORAL by 9.40% relatively on EER.
Essence Knowledge Distillation for Speech Recognition
Jun 26, 2019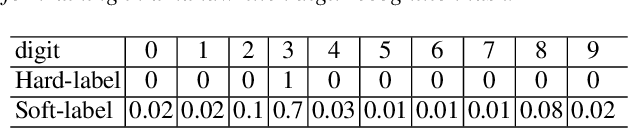
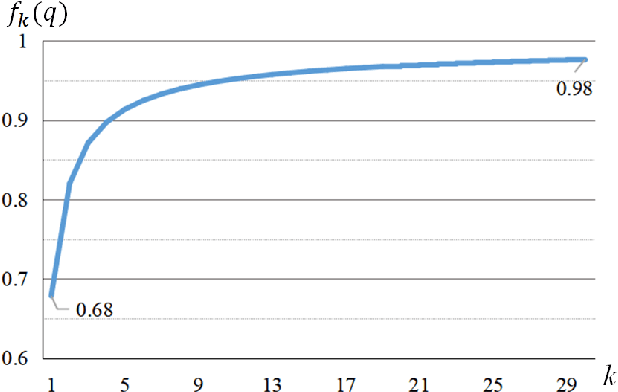
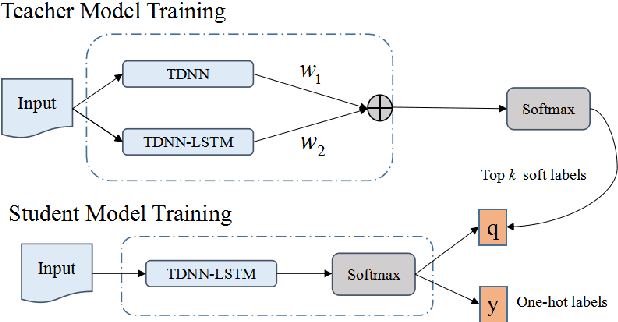
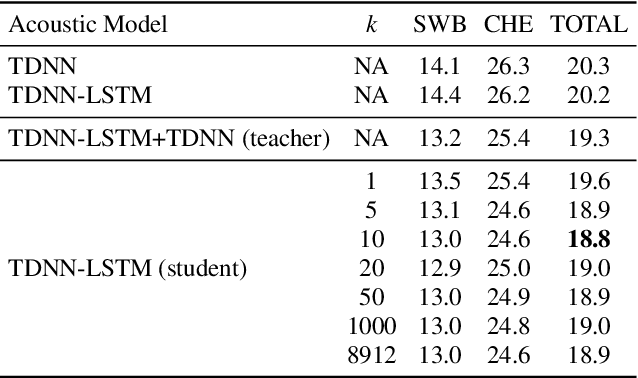
It is well known that a speech recognition system that combines multiple acoustic models trained on the same data significantly outperforms a single-model system. Unfortunately, real time speech recognition using a whole ensemble of models is too computationally expensive. In this paper, we propose to distill the knowledge of essence in an ensemble of models (i.e. the teacher model) to a single model (i.e. the student model) that needs much less computation to deploy. Previously, all the soften outputs of the teacher model are used to optimize the student model. We argue that not all the outputs of the ensemble are necessary to be distilled. Some of the outputs may even contain noisy information that is useless or even harmful to the training of the student model. In addition, we propose to train the student model with a multitask learning approach by utilizing both the soften outputs of the teacher model and the correct hard labels. The proposed method achieves some surprising results on the Switchboard data set. When the student model is trained together with the correct labels and the essence knowledge from the teacher model, it not only significantly outperforms another single model with the same architecture that is trained only with the correct labels, but also consistently outperforms the teacher model that is used to generate the soft labels.