 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Channel-Independent Time-Series Forecasting via Cross-Variate Patch Embedding
May 19, 2025Transformers have recently gained popularity in time series forecasting due to their ability to capture long-term dependencies. However, many existing models focus only on capturing temporal dependencies while omitting intricate relationships between variables. Recent models have tried tackling this by explicitly modeling both cross-time and cross-variate dependencies through a sequential or unified attention mechanism, but they are entirely channel dependent (CD) across all layers, making them potentially susceptible to overfitting. To address this, we propose Cross-Variate Patch Embeddings (CVPE), a lightweight CD module that injects cross-variate context into channel-independent (CI) models by simply modifying the patch embedding process. We achieve this by adding a learnable positional encoding and a lightweight router-attention block to the vanilla patch embedding layer. We then integrate CVPE into Time-LLM, a multimodal CI forecasting model, to demonstrate its effectiveness in capturing cross-variate dependencies and enhance the CI model's performance. Extensive experimental results on seven real-world datasets show that our enhanced Time-LLM outperforms the original baseline model simply by incorporating the CVPE module, with no other changes.
Creating a Cooperative AI Policymaking Platform through Open Source Collaboration
Dec 09, 2024

Advances in artificial intelligence (AI) present significant risks and opportunities, requiring improved governance to mitigate societal harms and promote equitable benefits. Current incentive structures and regulatory delays may hinder responsible AI development and deployment, particularly in light of the transformative potential of large language models (LLMs). To address these challenges, we propose developing the following three contributions: (1) a large multimodal text and economic-timeseries foundation model that integrates economic and natural language policy data for enhanced forecasting and decision-making, (2) algorithmic mechanisms for eliciting diverse and representative perspectives, enabling the creation of data-driven public policy recommendations, and (3) an AI-driven web platform for supporting transparent, inclusive, and data-driven policymaking.
Contextual Outlier Interpretation
May 04, 2018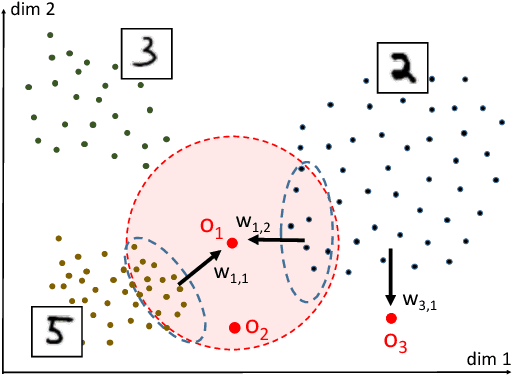
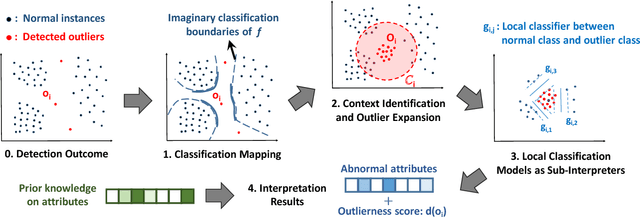
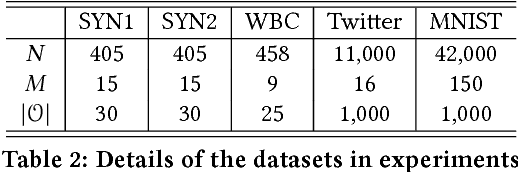
Outlier detection plays an essential role in many data-driven applications to identify isolated instances that are different from the majority. While many statistical learning and data mining techniques have been used for developing more effective outlier detection algorithms, the interpretation of detected outliers does not receive much attention. Interpretation is becoming increasingly important to help people trust and evaluate the developed models through providing intrinsic reasons why the certain outliers are chosen. It is difficult, if not impossible, to simply apply feature selection for explaining outliers due to the distinct characteristics of various detection models, complicated structures of data in certain applications, and imbalanced distribution of outliers and normal instances. In addition, the role of contrastive contexts where outliers locate, as well as the relation between outliers and contexts, are usually overlooked in interpretation. To tackle the issues above, in this paper, we propose a novel Contextual Outlier INterpretation (COIN) method to explain the abnormality of existing outliers spotted by detectors. The interpretability for an outlier is achieved from three aspects: outlierness score, attributes that contribute to the abnormality, and contextual description of its neighborhoods. Experimental results on various types of datasets demonstrate the flexibility and effectiveness of the proposed framework compared with existing interpretation approaches.