 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Uncertainty Principle: A Unified View of Adversarial Fragility and LLM Hallucination
Mar 20, 2026Adversarial vulnerability in vision and hallucination in large language models are conventionally viewed as separate problems, each addressed with modality-specific patches. This study first reveals that they share a common geometric origin: the input and its loss gradient are conjugate observables subject to an irreducible uncertainty bound. Formalizing a Neural Uncertainty Principle (NUP) under a loss-induced state, we find that in near-bound regimes, further compression must be accompanied by increased sensitivity dispersion (adversarial fragility), while weak prompt-gradient coupling leaves generation under-constrained (hallucination). Crucially, this bound is modulated by an input-gradient correlation channel, captured by a specifically designed single-backward probe. In vision, masking highly coupled components improves robustness without costly adversarial training; in language, the same prefill-stage probe detects hallucination risk before generating any answer tokens. NUP thus turns two seemingly separate failure taxonomies into a shared uncertainty-budget view and provides a principled lens for reliability analysis. Guided by this NUP theory, we propose ConjMask (masking high-contribution input components) and LogitReg (logit-side regularization) to improve robustness without adversarial training, and use the probe as a decoding-free risk signal for LLMs, enabling hallucination detection and prompt selection. NUP thus provides a unified, practical framework for diagnosing and mitigating boundary anomalies across perception and generation tasks.
On the uncertainty principle of neural networks
May 03, 2022
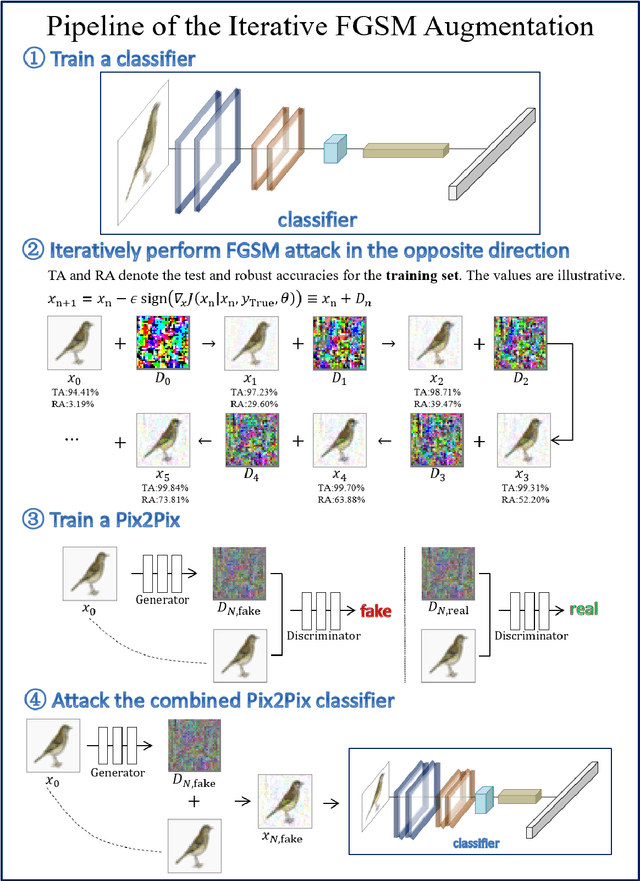
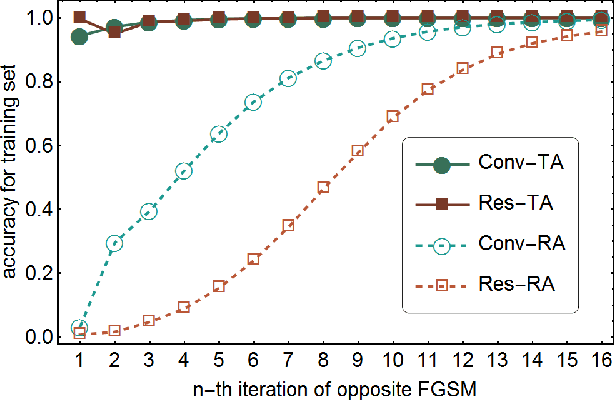
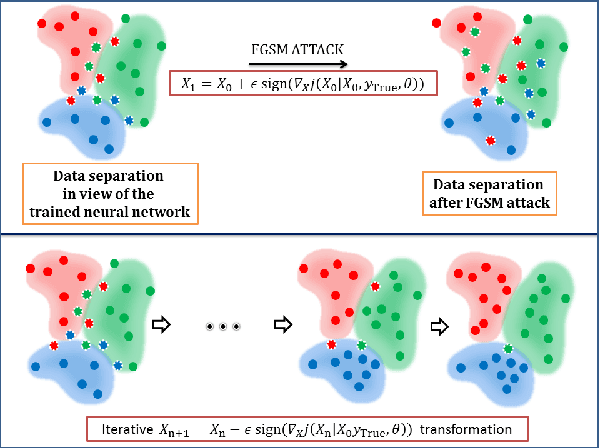
Despite the successes in many fields, it is found that neural networks are vulnerability and difficult to be both accurate and robust (robust means that the prediction of the trained network stays unchanged for inputs with non-random perturbations introduced by adversarial attacks). Various empirical and analytic studies have suggested that there is more or less a trade-off between the accuracy and robustness of neural networks. If the trade-off is inherent, applications based on the neural networks are vulnerable with untrustworthy predictions. It is then essential to ask whether the trade-off is an inherent property or not. Here, we show that the accuracy-robustness trade-off is an intrinsic property whose underlying mechanism is deeply related to the uncertainty principle in quantum mechanics. We find that for a neural network to be both accurate and robust, it needs to resolve the features of the two conjugated parts $x$ (the inputs) and $\Delta$ (the derivatives of the normalized loss function $J$ with respect to $x$), respectively. Analogous to the position-momentum conjugation in quantum mechanics, we show that the inputs and their conjugates cannot be resolved by a neural network simultaneously.