 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSame Author or Just Same Topic? Towards Content-Independent Style Representations
Apr 11, 2022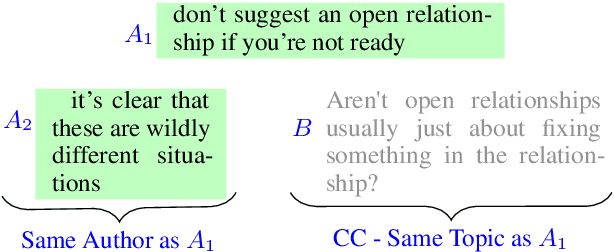
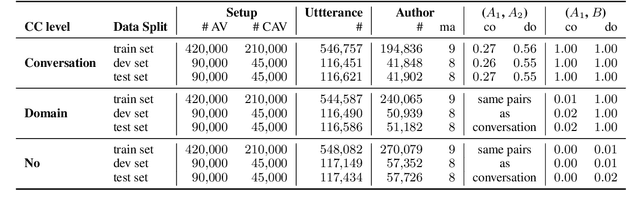
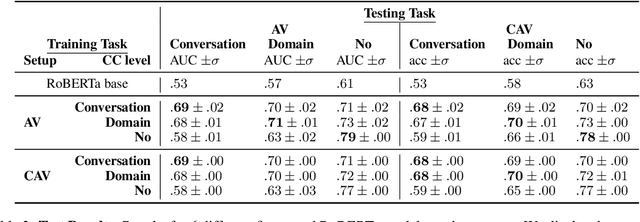

Linguistic style is an integral component of language. Recent advances in the development of style representations have increasingly used training objectives from authorship verification (AV): Do two texts have the same author? The assumption underlying the AV training task (same author approximates same writing style) enables self-supervised and, thus, extensive training. However, a good performance on the AV task does not ensure good "general-purpose" style representations. For example, as the same author might typically write about certain topics, representations trained on AV might also encode content information instead of style alone. We introduce a variation of the AV training task that controls for content using conversation or domain labels. We evaluate whether known style dimensions are represented and preferred over content information through an original variation to the recently proposed STEL framework. We find that representations trained by controlling for conversation are better than representations trained with domain or no content control at representing style independent from content.
Evaluating the Construct Validity of Text Embeddings with Application to Survey Questions
Feb 18, 2022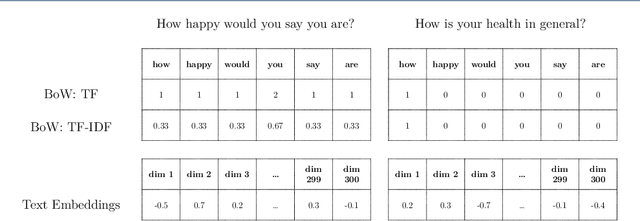

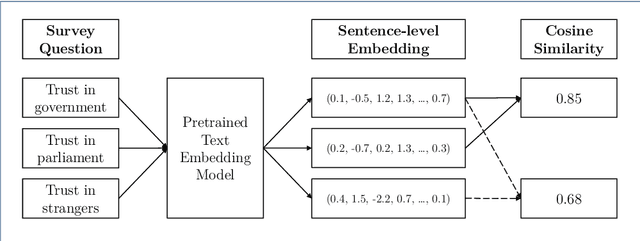
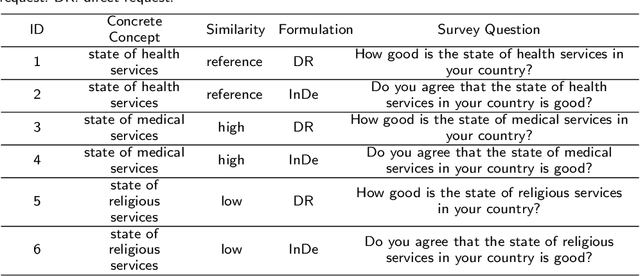
Text embedding models from Natural Language Processing can map text data (e.g. words, sentences, documents) to supposedly meaningful numerical representations (a.k.a. text embeddings). While such models are increasingly applied in social science research, one important issue is often not addressed: the extent to which these embeddings are valid representations of constructs relevant for social science research. We therefore propose the use of the classic construct validity framework to evaluate the validity of text embeddings. We show how this framework can be adapted to the opaque and high-dimensional nature of text embeddings, with application to survey questions. We include several popular text embedding methods (e.g. fastText, GloVe, BERT, Sentence-BERT, Universal Sentence Encoder) in our construct validity analyses. We find evidence of convergent and discriminant validity in some cases. We also show that embeddings can be used to predict respondent's answers to completely new survey questions. Furthermore, BERT-based embedding techniques and the Universal Sentence Encoder provide more valid representations of survey questions than do others. Our results thus highlight the necessity to examine the construct validity of text embeddings before deploying them in social science research.
Understanding Public Opinion on Using Hydroxychloroquine for COVID-19 Treatment via Social Media
Jan 01, 2022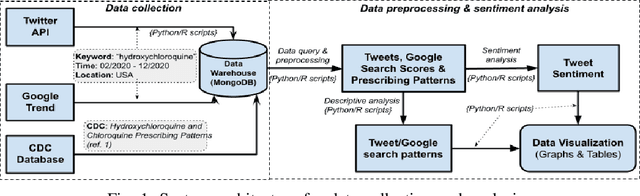

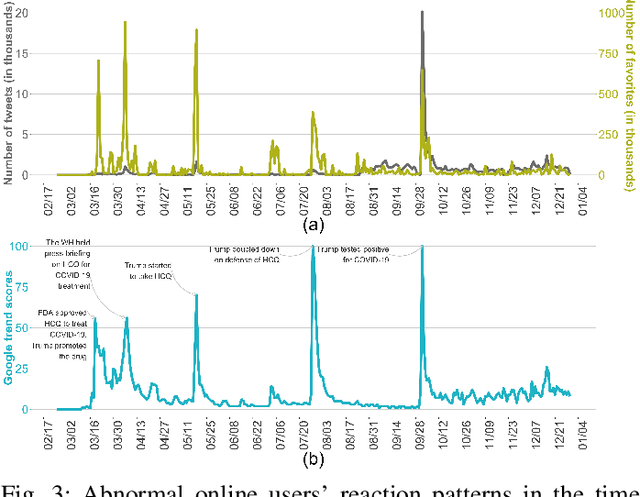

Hydroxychloroquine (HCQ) is used to prevent or treat malaria caused by mosquito bites. Recently, the drug has been suggested to treat COVID-19, but that has not been supported by scientific evidence. The information regarding the drug efficacy has flooded social networks, posting potential threats to the community by perverting their perceptions of the drug efficacy. This paper studies the reactions of social network users on the recommendation of using HCQ for COVID-19 treatment by analyzing the reaction patterns and sentiment of the tweets. We collected 164,016 tweets from February to December 2020 and used a text mining approach to identify social reaction patterns and opinion change over time. Our descriptive analysis identified an irregularity of the users' reaction patterns associated tightly with the social and news feeds on the development of HCQ and COVID-19 treatment. The study linked the tweets and Google search frequencies to reveal the viewpoints of local communities on the use of HCQ for COVID-19 treatment across different states. Further, our tweet sentiment analysis reveals that public opinion changed significantly over time regarding the recommendation of using HCQ for COVID-19 treatment. The data showed that high support in the early dates but it significantly declined in October. Finally, using the manual classification of 4,850 tweets by humans as our benchmark, our sentiment analysis showed that the Google Cloud Natural Language algorithm outperformed the Valence Aware Dictionary and sEntiment Reasoner in classifying tweets, especially in the sarcastic tweet group.
Does It Capture STEL? A Modular, Similarity-based Linguistic Style Evaluation Framework
Sep 10, 2021

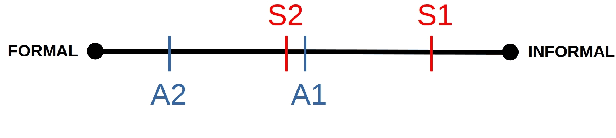
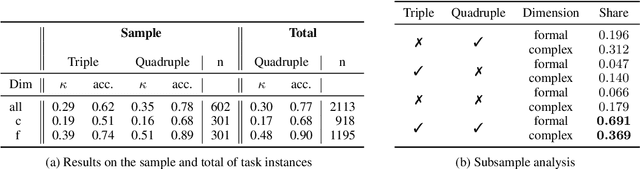
Style is an integral part of natural language. However, evaluation methods for style measures are rare, often task-specific and usually do not control for content. We propose the modular, fine-grained and content-controlled similarity-based STyle EvaLuation framework (STEL) to test the performance of any model that can compare two sentences on style. We illustrate STEL with two general dimensions of style (formal/informal and simple/complex) as well as two specific characteristics of style (contrac'tion and numb3r substitution). We find that BERT-based methods outperform simple versions of commonly used style measures like 3-grams, punctuation frequency and LIWC-based approaches. We invite the addition of further tasks and task instances to STEL and hope to facilitate the improvement of style-sensitive measures.
Assessing the Reliability of Word Embedding Gender Bias Measures
Sep 10, 2021

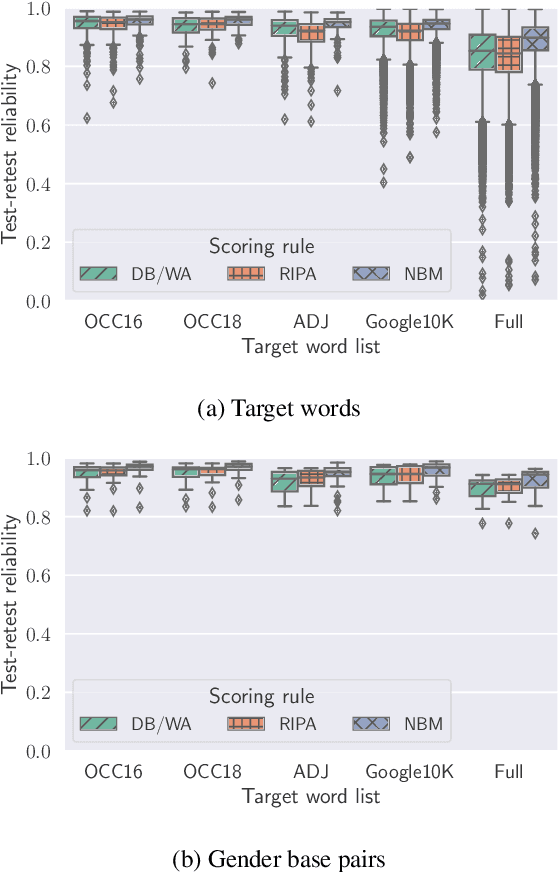
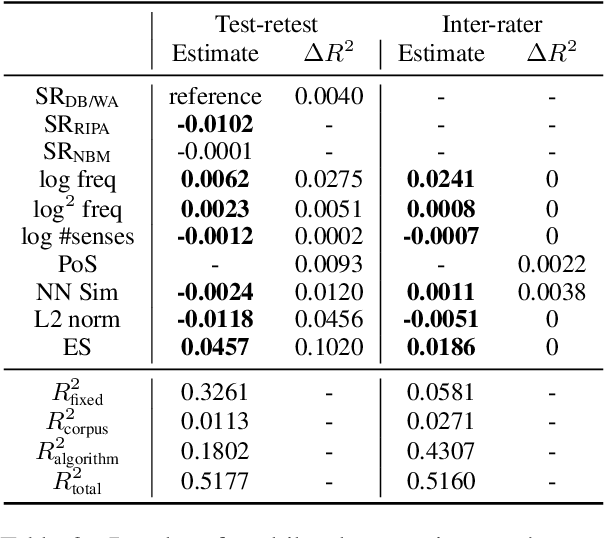
Various measures have been proposed to quantify human-like social biases in word embeddings. However, bias scores based on these measures can suffer from measurement error. One indication of measurement quality is reliability, concerning the extent to which a measure produces consistent results. In this paper, we assess three types of reliability of word embedding gender bias measures, namely test-retest reliability, inter-rater consistency and internal consistency. Specifically, we investigate the consistency of bias scores across different choices of random seeds, scoring rules and words. Furthermore, we analyse the effects of various factors on these measures' reliability scores. Our findings inform better design of word embedding gender bias measures. Moreover, we urge researchers to be more critical about the application of such measures.
Semantic Journeys: Quantifying Change in Emoji Meaning from 2012-2018
May 04, 2021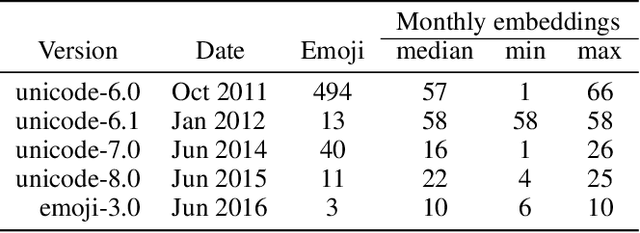
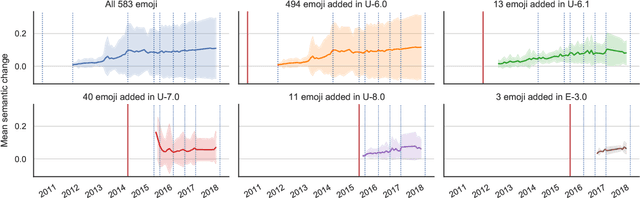
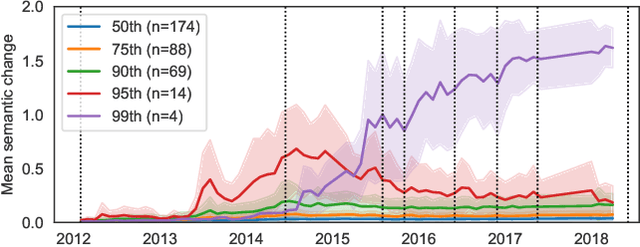

The semantics of emoji has, to date, been considered from a static perspective. We offer the first longitudinal study of how emoji semantics changes over time, applying techniques from computational linguistics to six years of Twitter data. We identify five patterns in emoji semantic development and find evidence that the less abstract an emoji is, the more likely it is to undergo semantic change. In addition, we analyse select emoji in more detail, examining the effect of seasonality and world events on emoji semantics. To aid future work on emoji and semantics, we make our data publicly available along with a web-based interface that anyone can use to explore semantic change in emoji.
HateCheck: Functional Tests for Hate Speech Detection Models
Dec 31, 2020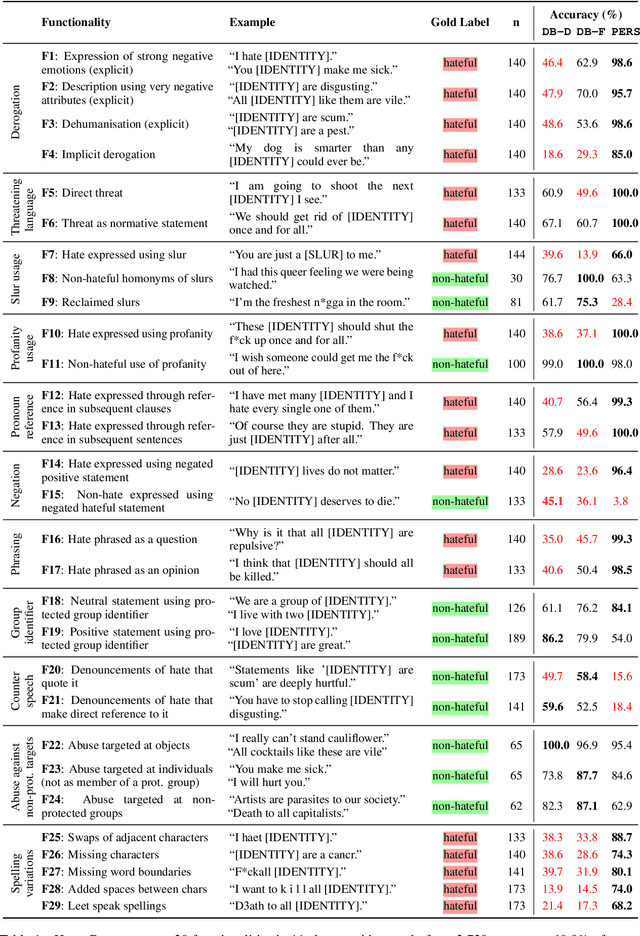
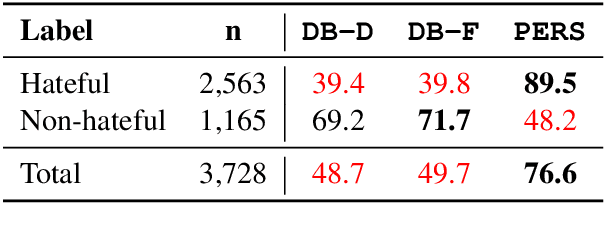
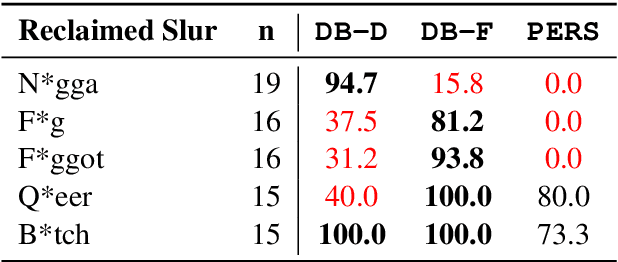

Detecting online hate is a difficult task that even state-of-the-art models struggle with. In previous research, hate speech detection models are typically evaluated by measuring their performance on held-out test data using metrics such as accuracy and F1 score. However, this approach makes it difficult to identify specific model weak points. It also risks overestimating generalisable model quality due to increasingly well-evidenced systematic gaps and biases in hate speech datasets. To enable more targeted diagnostic insights, we introduce HateCheck, a first suite of functional tests for hate speech detection models. We specify 29 model functionalities, the selection of which we motivate by reviewing previous research and through a series of interviews with civil society stakeholders. We craft test cases for each functionality and validate data quality through a structured annotation process. To illustrate HateCheck's utility, we test near-state-of-the-art transformer detection models as well as a popular commercial model, revealing critical model weaknesses.
Better Early than Late: Fusing Topics with Word Embeddings for Neural Question Paraphrase Identification
Jul 22, 2020



Question paraphrase identification is a key task in Community Question Answering (CQA) to determine if an incoming question has been previously asked. Many current models use word embeddings to identify duplicate questions, but the use of topic models in feature-engineered systems suggests that they can be helpful for this task, too. We therefore propose two ways of merging topics with word embeddings (early vs. late fusion) in a new neural architecture for question paraphrase identification. Our results show that our system outperforms neural baselines on multiple CQA datasets, while an ablation study highlights the importance of topics and especially early topic-embedding fusion in our architecture.
How we do things with words: Analyzing text as social and cultural data
Jul 02, 2019In this article we describe our experiences with computational text analysis. We hope to achieve three primary goals. First, we aim to shed light on thorny issues not always at the forefront of discussions about computational text analysis methods. Second, we hope to provide a set of best practices for working with thick social and cultural concepts. Our guidance is based on our own experiences and is therefore inherently imperfect. Still, given our diversity of disciplinary backgrounds and research practices, we hope to capture a range of ideas and identify commonalities that will resonate for many. And this leads to our final goal: to help promote interdisciplinary collaborations. Interdisciplinary insights and partnerships are essential for realizing the full potential of any computational text analysis that involves social and cultural concepts, and the more we are able to bridge these divides, the more fruitful we believe our work will be.
Emo, Love, and God: Making Sense of Urban Dictionary, a Crowd-Sourced Online Dictionary
Apr 05, 2018
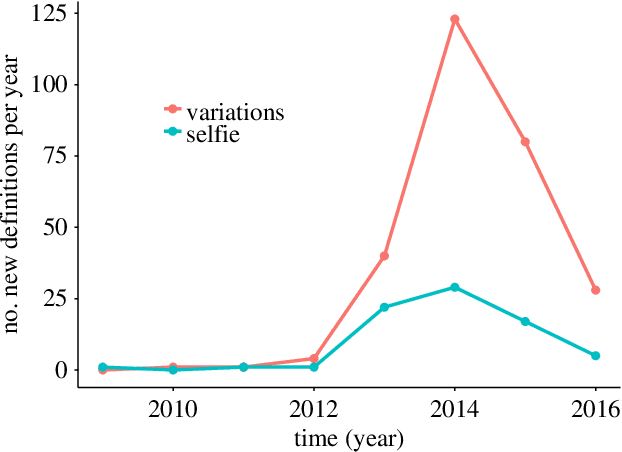

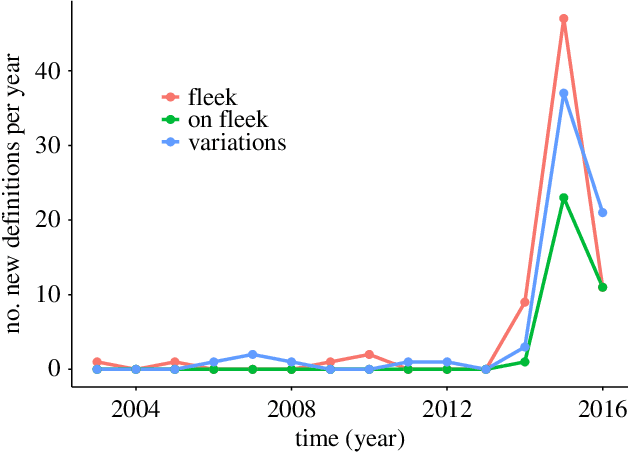
The Internet facilitates large-scale collaborative projects and the emergence of Web 2.0 platforms, where producers and consumers of content unify, has drastically changed the information market. On the one hand, the promise of the "wisdom of the crowd" has inspired successful projects such as Wikipedia, which has become the primary source of crowd-based information in many languages. On the other hand, the decentralized and often un-monitored environment of such projects may make them susceptible to low quality content. In this work, we focus on Urban Dictionary, a crowd-sourced online dictionary. We combine computational methods with qualitative annotation and shed light on the overall features of Urban Dictionary in terms of growth, coverage and types of content. We measure a high presence of opinion-focused entries, as opposed to the meaning-focused entries that we expect from traditional dictionaries. Furthermore, Urban Dictionary covers many informal, unfamiliar words as well as proper nouns. Urban Dictionary also contains offensive content, but highly offensive content tends to receive lower scores through the dictionary's voting system. The low threshold to include new material in Urban Dictionary enables quick recording of new words and new meanings, but the resulting heterogeneous content can pose challenges in using Urban Dictionary as a source to study language innovation.