 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEANet: A Multi-modal Speech Enhancement Network
Oct 01, 2020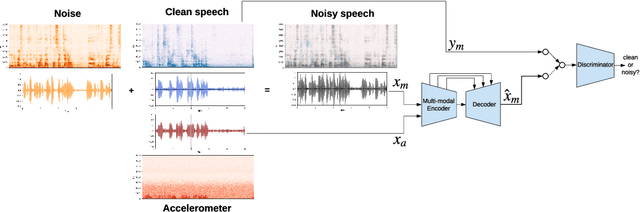
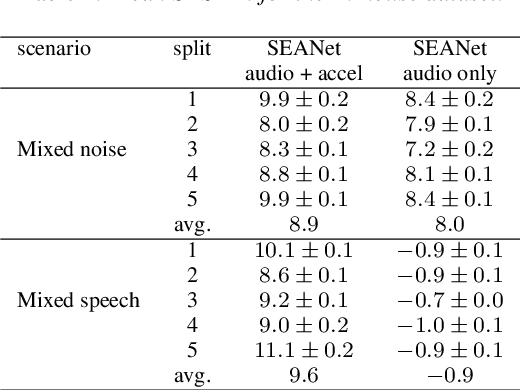
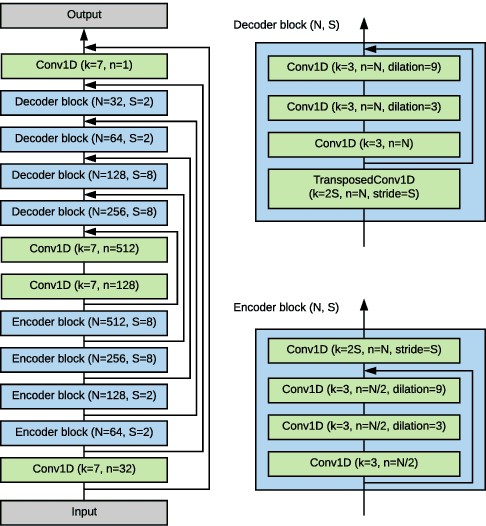

We explore the possibility of leveraging accelerometer data to perform speech enhancement in very noisy conditions. Although it is possible to only partially reconstruct user's speech from the accelerometer, the latter provides a strong conditioning signal that is not influenced from noise sources in the environment. Based on this observation, we feed a multi-modal input to SEANet (Sound EnhAncement Network), a wave-to-wave fully convolutional model, which adopts a combination of feature losses and adversarial losses to reconstruct an enhanced version of user's speech. We trained our model with data collected by sensors mounted on an earbud and synthetically corrupted by adding different kinds of noise sources to the audio signal. Our experimental results demonstrate that it is possible to achieve very high quality results, even in the case of interfering speech at the same level of loudness. A sample of the output produced by our model is available at https://google-research.github.io/seanet/multimodal/speech.
Learning to Denoise Historical Music
Aug 05, 2020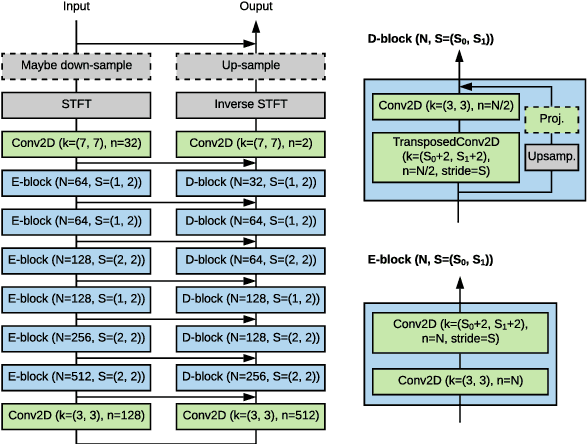
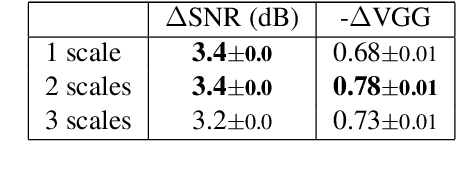
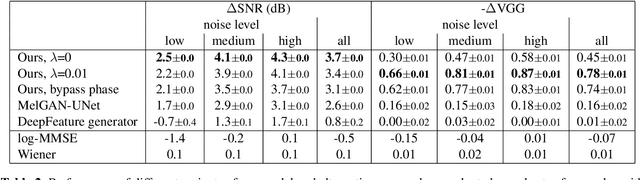
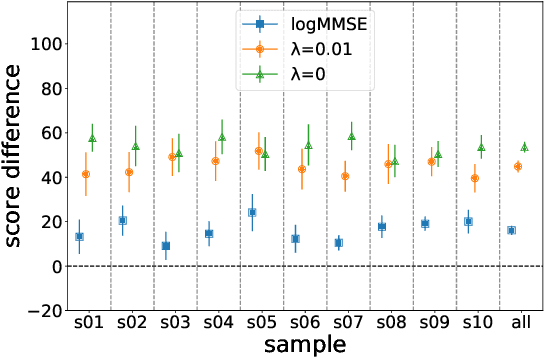
We propose an audio-to-audio neural network model that learns to denoise old music recordings. Our model internally converts its input into a time-frequency representation by means of a short-time Fourier transform (STFT), and processes the resulting complex spectrogram using a convolutional neural network. The network is trained with both reconstruction and adversarial objectives on a synthetic noisy music dataset, which is created by mixing clean music with real noise samples extracted from quiet segments of old recordings. We evaluate our method quantitatively on held-out test examples of the synthetic dataset, and qualitatively by human rating on samples of actual historical recordings. Our results show that the proposed method is effective in removing noise, while preserving the quality and details of the original music.
Training Keyword Spotters with Limited and Synthesized Speech Data
Jan 31, 2020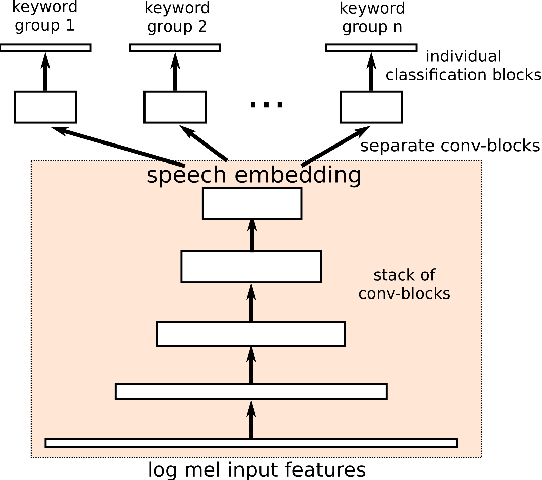
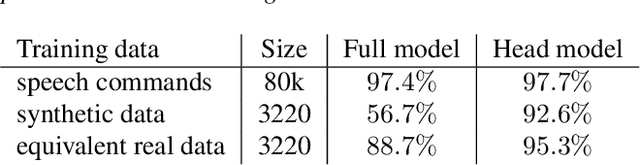
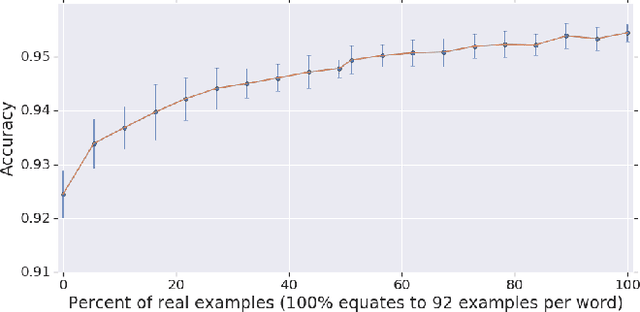
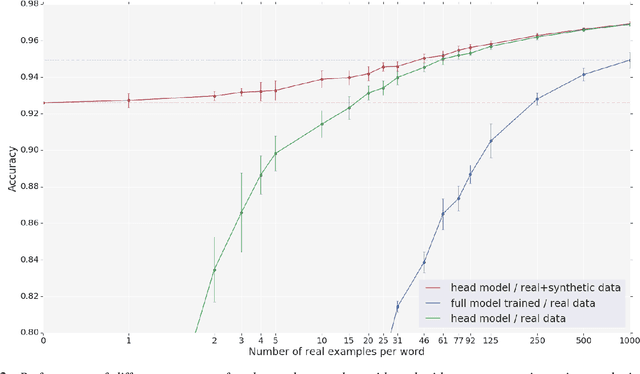
With the rise of low power speech-enabled devices, there is a growing demand to quickly produce models for recognizing arbitrary sets of keywords. As with many machine learning tasks, one of the most challenging parts in the model creation process is obtaining a sufficient amount of training data. In this paper, we explore the effectiveness of synthesized speech data in training small, spoken term detection models of around 400k parameters. Instead of training such models directly on the audio or low level features such as MFCCs, we use a pre-trained speech embedding model trained to extract useful features for keyword spotting models. Using this speech embedding, we show that a model which detects 10 keywords when trained on only synthetic speech is equivalent to a model trained on over 500 real examples. We also show that a model without our speech embeddings would need to be trained on over 4000 real examples to reach the same accuracy.
Learning audio representations via phase prediction
Oct 25, 2019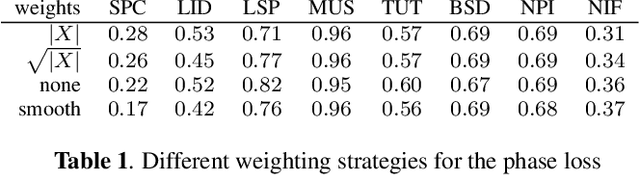
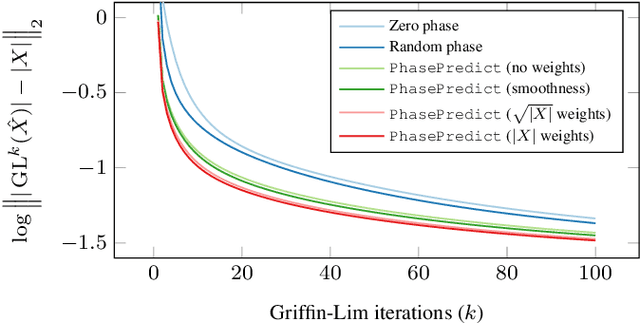
We learn audio representations by solving a novel self-supervised learning task, which consists of predicting the phase of the short-time Fourier transform from its magnitude. A convolutional encoder is used to map the magnitude spectrum of the input waveform to a lower dimensional embedding. A convolutional decoder is then used to predict the instantaneous frequency (i.e., the temporal rate of change of the phase) from such embedding. To evaluate the quality of the learned representations, we evaluate how they transfer to a wide variety of downstream audio tasks. Our experiments reveal that the phase prediction task leads to representations that generalize across different tasks, partially bridging the gap with fully-supervised models. In addition, we show that the predicted phase can be used as initialization of the Griffin-Lim algorithm, thus reducing the number of iterations needed to reconstruct the waveform in the time domain.
SPICE: Self-supervised Pitch Estimation
Oct 25, 2019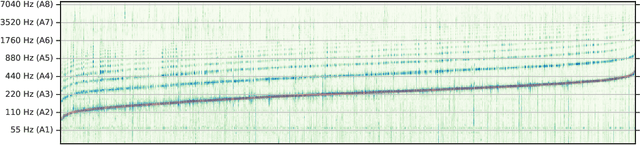
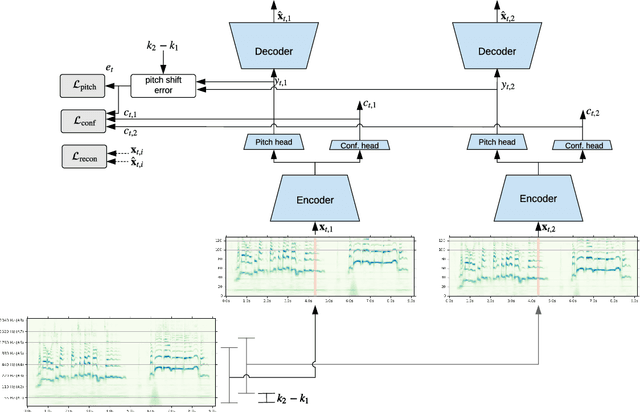
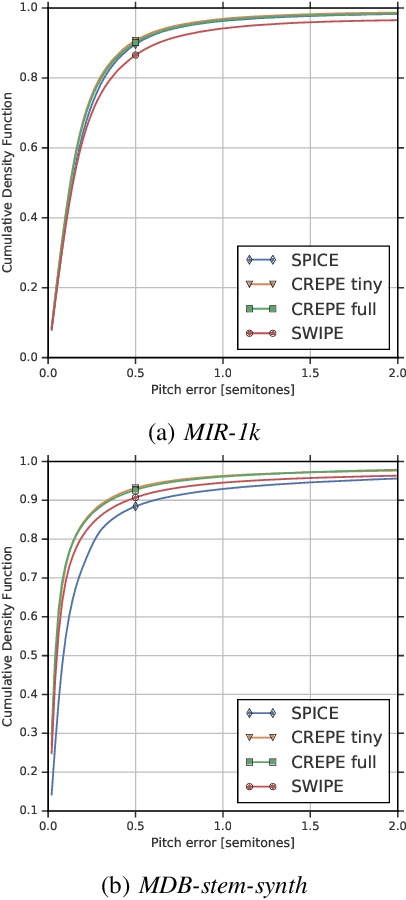
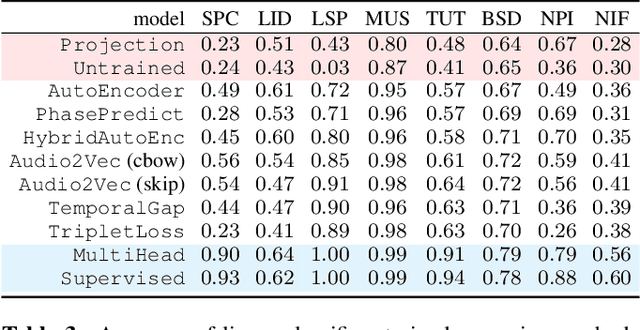
We propose a model to estimate the fundamental frequency in monophonic audio, often referred to as pitch estimation. We acknowledge the fact that obtaining ground truth annotations at the required temporal and frequency resolution is a particularly daunting task. Therefore, we propose to adopt a self-supervised learning technique, which is able to estimate (relative) pitch without any form of supervision. The key observation is that pitch shift maps to a simple translation when the audio signal is analysed through the lens of the constant-Q transform (CQT). We design a self-supervised task by feeding two shifted slices of the CQT to the same convolutional encoder, and require that the difference in the outputs is proportional to the corresponding difference in pitch. In addition, we introduce a small model head on top of the encoder, which is able to determine the confidence of the pitch estimate, so as to distinguish between voiced and unvoiced audio. Our results show that the proposed method is able to estimate pitch at a level of accuracy comparable to fully supervised models, both on clean and noisy audio samples, yet it does not require access to large labeled datasets
From Here to There: Video Inbetweening Using Direct 3D Convolutions
Jun 04, 2019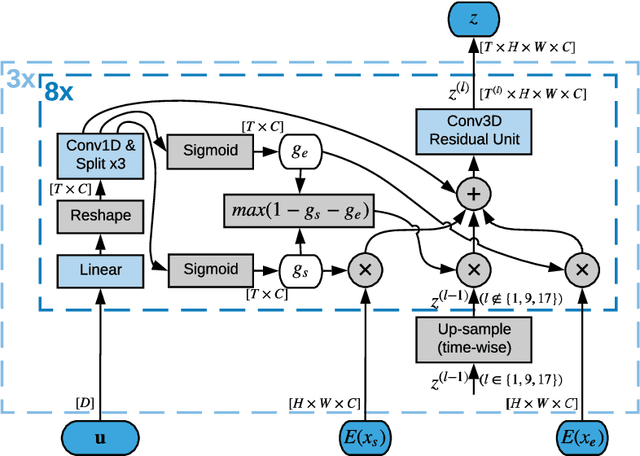

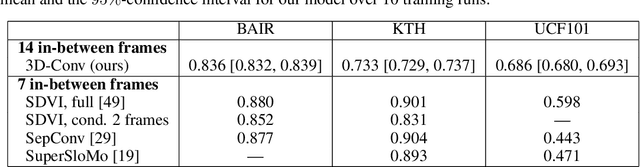
We consider the problem of generating plausible and diverse video sequences, when we are only given a start and an end frame. This task is also known as inbetweening, and it belongs to the broader area of stochastic video generation, which is generally approached by means of recurrent neural networks (RNN). In this paper, we propose instead a fully convolutional model to generate video sequences directly in the pixel domain. We first obtain a latent video representation using a stochastic fusion mechanism that learns how to incorporate information from the start and end frames. Our model learns to produce such latent representation by progressively increasing the temporal resolution, and then decode in the spatiotemporal domain using 3D convolutions. The model is trained end-to-end by minimizing an adversarial loss. Experiments on several widely-used benchmark datasets show that it is able to generate meaningful and diverse in-between video sequences, according to both quantitative and qualitative evaluations.
Self-supervised audio representation learning for mobile devices
May 24, 2019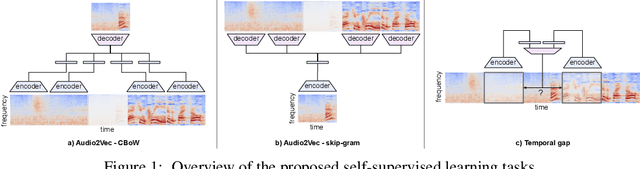
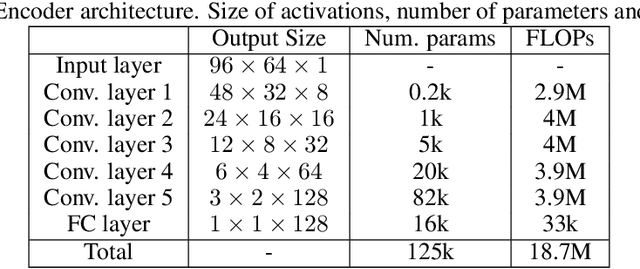
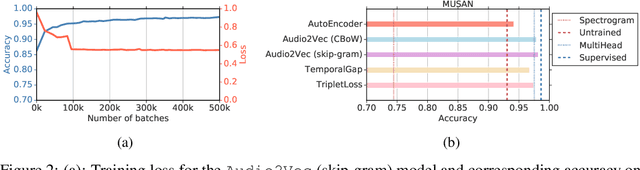
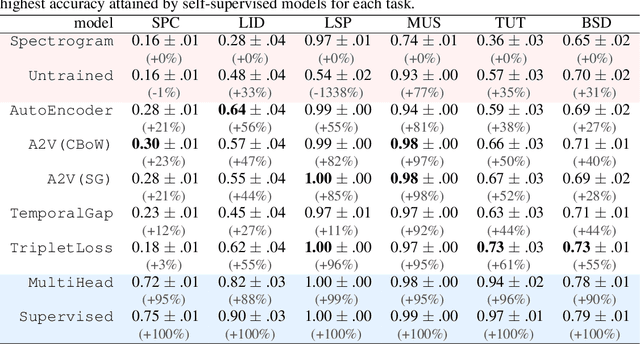
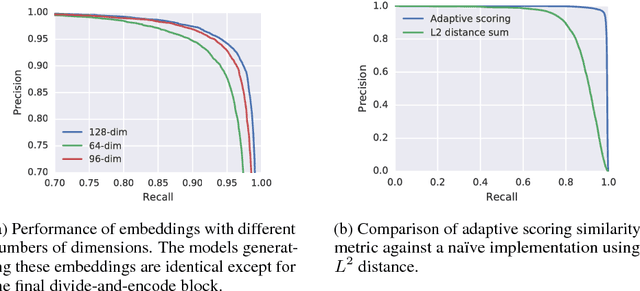
We explore self-supervised models that can be potentially deployed on mobile devices to learn general purpose audio representations. Specifically, we propose methods that exploit the temporal context in the spectrogram domain. One method estimates the temporal gap between two short audio segments extracted at random from the same audio clip. The other methods are inspired by Word2Vec, a popular technique used to learn word embeddings, and aim at reconstructing a temporal spectrogram slice from past and future slices or, alternatively, at reconstructing the context of surrounding slices from the current slice. We focus our evaluation on small encoder architectures, which can be potentially run on mobile devices during both inference (re-using a common learned representation across multiple downstream tasks) and training (capturing the true data distribution without compromising users' privacy when combined with federated learning). We evaluate the quality of the embeddings produced by the self-supervised learning models, and show that they can be re-used for a variety of downstream tasks, and for some tasks even approach the performance of fully supervised models of similar size.
An Empirical Study of Generative Models with Encoders
Dec 19, 2018

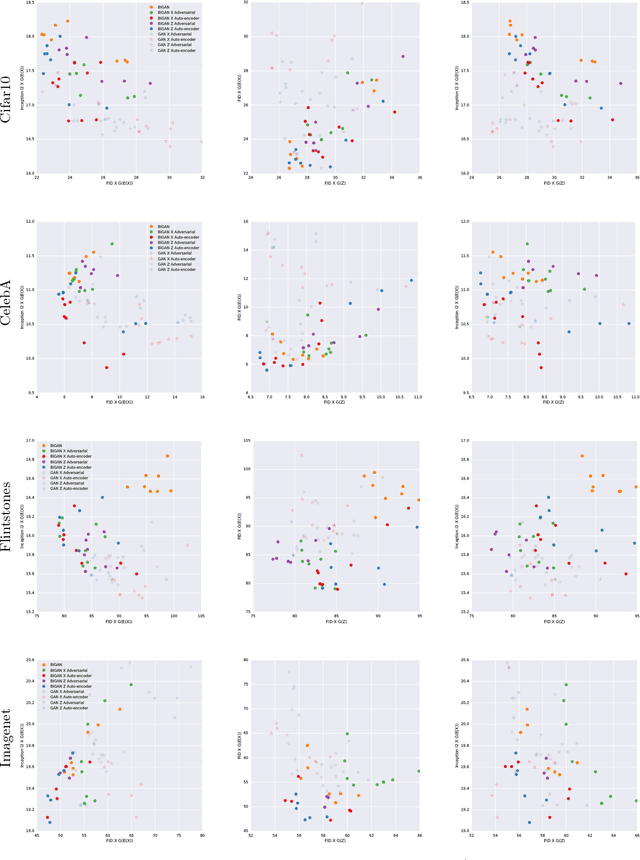
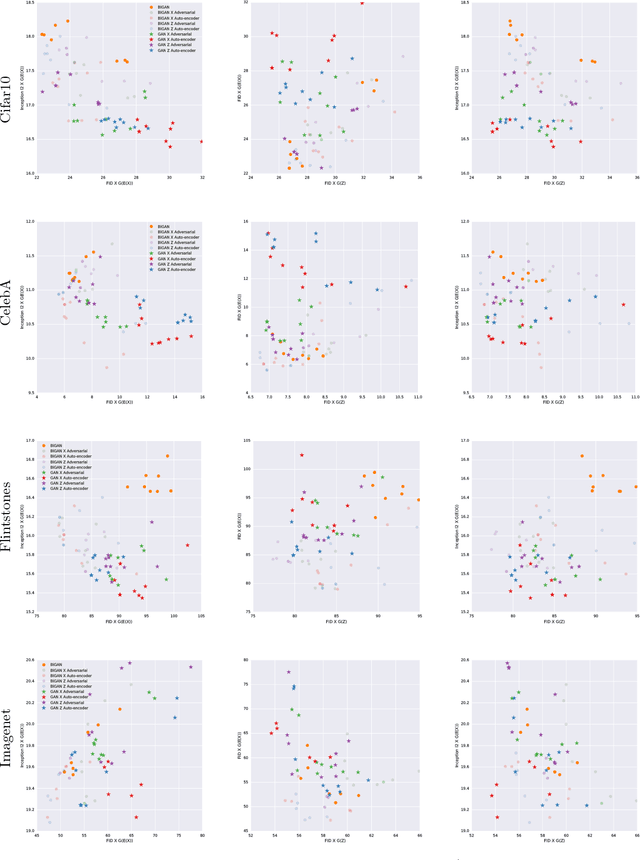
Generative adversarial networks (GANs) are capable of producing high quality image samples. However, unlike variational autoencoders (VAEs), GANs lack encoders that provide the inverse mapping for the generators, i.e., encode images back to the latent space. In this work, we consider adversarially learned generative models that also have encoders. We evaluate models based on their ability to produce high quality samples and reconstructions of real images. Our main contributions are twofold: First, we find that the baseline Bidirectional GAN (BiGAN) can be improved upon with the addition of an autoencoder loss, at the expense of an extra hyper-parameter to tune. Second, we show that comparable performance to BiGAN can be obtained by simply training an encoder to invert the generator of a normal GAN.
Low-Dimensional Bottleneck Features for On-Device Continuous Speech Recognition
Oct 31, 2018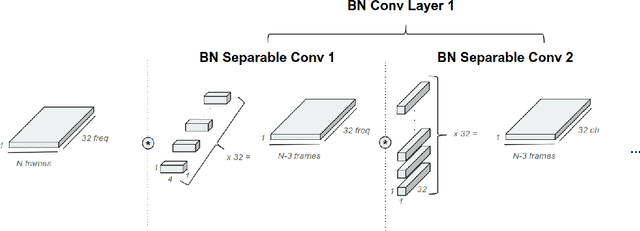

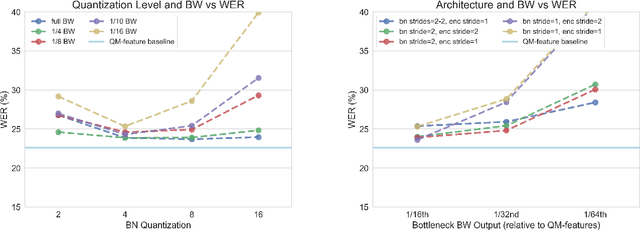
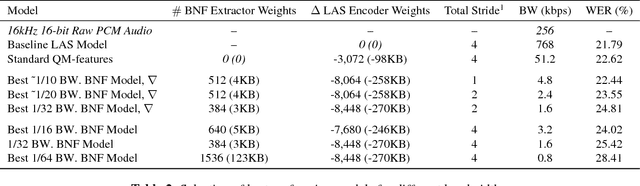
Low power digital signal processors (DSPs) typically have a very limited amount of memory in which to cache data. In this paper we develop efficient bottleneck feature (BNF) extractors that can be run on a DSP, and retrain a baseline large-vocabulary continuous speech recognition (LVCSR) system to use these BNFs with only a minimal loss of accuracy. The small BNFs allow the DSP chip to cache more audio features while the main application processor is suspended, thereby reducing the overall battery usage. Our presented system is able to reduce the footprint of standard, fixed point DSP spectral features by a factor of 10 without any loss in word error rate (WER) and by a factor of 64 with only a 5.8% relative increase in WER.
Now Playing: Continuous low-power music recognition
Nov 29, 2017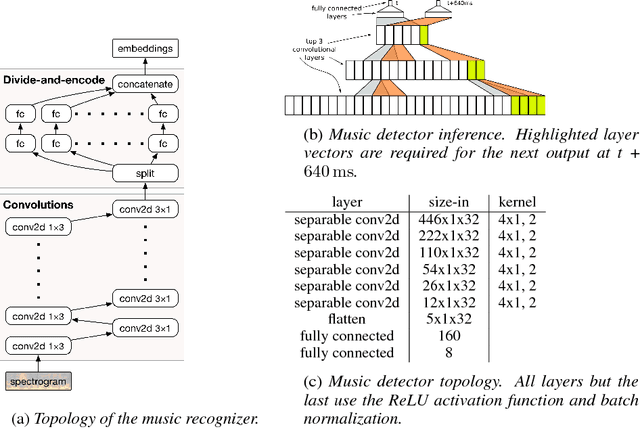
Existing music recognition applications require a connection to a server that performs the actual recognition. In this paper we present a low-power music recognizer that runs entirely on a mobile device and automatically recognizes music without user interaction. To reduce battery consumption, a small music detector runs continuously on the mobile device's DSP chip and wakes up the main application processor only when it is confident that music is present. Once woken, the recognizer on the application processor is provided with a few seconds of audio which is fingerprinted and compared to the stored fingerprints in the on-device fingerprint database of tens of thousands of songs. Our presented system, Now Playing, has a daily battery usage of less than 1% on average, respects user privacy by running entirely on-device and can passively recognize a wide range of music.