 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavioral Engagement in VR-Based Sign Language Learning: Visual Attention as a Predictor of Performance and Temporal Dynamics
Mar 20, 2026This study analyzes behavioral engagement in SONAR, a virtual reality application designed for sign language training and validation. We focus on three automatically derived engagement indicators (Visual Attention (VA), Video Replay Frequency (VRF), and Post-Playback Viewing Time (PPVT)) and examine their relationship with learning performance. Participants completed a self-paced Training phase, followed by a Validation quiz assessing retention. We employed Pearson correlation analysis to examine the relationships between engagement indicators and quiz performance, followed by binomial Generalized Linear Model (GLM) regression to assess their joint predictive contributions. Additionally, we conducted temporal analysis by aggregating moment-to-moment VA traces across all learners to characterize engagement dynamics during the learning session. Results show that VA exhibits a strong positive correlation with quiz performance,followed by PPVT, whereas VRF shows no meaningful association. A binomial GLM confirms that VA and PPVT are significant predictors of learning success, jointly explaining a substantial proportion of performance variance. Going beyond outcome-oriented analysis, we characterize temporal engagement patterns by aggregating moment-to-moment VA traces across all learners. The temporal profile reveals distinct attention peaks aligned with informationally dense segments of both training and validation videos, as well as phase-specific engagement dynamics, including initial acclimatization, oscillatory attention cycles during learning, and pronounced attentional peaks during assessment. Together, these findings highlight the central role of sustained and strategically allocated visual attention in VR-based sign language learning and demonstrate the value of behavioral trace data for understanding and predicting learner engagement in immersive environments.
* 22 pages. 5 figures. 2 tables
XML Matchers: approaches and challenges
Jul 10, 2014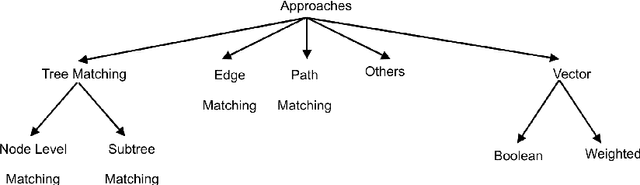

Schema Matching, i.e. the process of discovering semantic correspondences between concepts adopted in different data source schemas, has been a key topic in Database and Artificial Intelligence research areas for many years. In the past, it was largely investigated especially for classical database models (e.g., E/R schemas, relational databases, etc.). However, in the latest years, the widespread adoption of XML in the most disparate application fields pushed a growing number of researchers to design XML-specific Schema Matching approaches, called XML Matchers, aiming at finding semantic matchings between concepts defined in DTDs and XSDs. XML Matchers do not just take well-known techniques originally designed for other data models and apply them on DTDs/XSDs, but they exploit specific XML features (e.g., the hierarchical structure of a DTD/XSD) to improve the performance of the Schema Matching process. The design of XML Matchers is currently a well-established research area. The main goal of this paper is to provide a detailed description and classification of XML Matchers. We first describe to what extent the specificities of DTDs/XSDs impact on the Schema Matching task. Then we introduce a template, called XML Matcher Template, that describes the main components of an XML Matcher, their role and behavior. We illustrate how each of these components has been implemented in some popular XML Matchers. We consider our XML Matcher Template as the baseline for objectively comparing approaches that, at first glance, might appear as unrelated. The introduction of this template can be useful in the design of future XML Matchers. Finally, we analyze commercial tools implementing XML Matchers and introduce two challenging issues strictly related to this topic, namely XML source clustering and uncertainty management in XML Matchers.
* 34 pages, 8 tables, 7 figures