 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding a Strong Instruction Language Model for a Less-Resourced Language
Mar 02, 2026Large language models (LLMs) have become an essential tool for natural language processing and artificial intelligence in general. Current open-source models are primarily trained on English texts, resulting in poorer performance on less-resourced languages and cultures. We present a set of methodological approaches necessary for the successful adaptation of an LLM to a less-resourced language, and demonstrate them using the Slovene language. We present GaMS3-12B, a generative model for Slovene with 12 billion parameters, and demonstrate that it is the best-performing open-source model for Slovene within its parameter range. We adapted the model to the Slovene language using three-stage continual pre-training of the Gemma 3 model, followed by two-stage supervised fine-tuning (SFT). We trained the model on a combination of 140B Slovene, English, Bosnian, Serbian, and Croatian pretraining tokens, and over 200 thousand English and Slovene SFT examples. We evaluate GaMS3-12B on the Slovenian-LLM-Eval datasets, English-to-Slovene translation, and the Slovene LLM arena. We show that the described model outperforms 12B Gemma 3 across all three scenarios and performs comparably to much larger commercial GPT-4o in the Slovene LLM arena, achieving a win rate of over 60 %.
Improving LLMs for Machine Translation Using Synthetic Preference Data
Aug 20, 2025Large language models have emerged as effective machine translation systems. In this paper, we explore how a general instruction-tuned large language model can be improved for machine translation using relatively few easily produced data resources. Using Slovene as a use case, we improve the GaMS-9B-Instruct model using Direct Preference Optimization (DPO) training on a programmatically curated and enhanced subset of a public dataset. As DPO requires pairs of quality-ranked instances, we generated its training dataset by translating English Wikipedia articles using two LLMs, GaMS-9B-Instruct and EuroLLM-9B-Instruct. We ranked the resulting translations based on heuristics coupled with automatic evaluation metrics such as COMET. The evaluation shows that our fine-tuned model outperforms both models involved in the dataset generation. In comparison to the baseline models, the fine-tuned model achieved a COMET score gain of around 0.04 and 0.02, respectively, on translating Wikipedia articles. It also more consistently avoids language and formatting errors.
Generative Model for Less-Resourced Language with 1 billion parameters
Oct 09, 2024



Large language models (LLMs) are a basic infrastructure for modern natural language processing. Many commercial and open-source LLMs exist for English, e.g., ChatGPT, Llama, Falcon, and Mistral. As these models are trained on mostly English texts, their fluency and knowledge of low-resource languages and societies are superficial. We present the development of large generative language models for a less-resourced language. GaMS 1B - Generative Model for Slovene with 1 billion parameters was created by continuing pretraining of the existing English OPT model. We developed a new tokenizer adapted to Slovene, Croatian, and English languages and used embedding initialization methods FOCUS and WECHSEL to transfer the embeddings from the English OPT model. We evaluate our models on several classification datasets from the Slovene suite of benchmarks and generative sentence simplification task SENTA. We only used a few-shot in-context learning of our models, which are not yet instruction-tuned. For classification tasks, in this mode, the generative models lag behind the existing Slovene BERT-type models fine-tuned for specific tasks. On a sentence simplification task, the GaMS models achieve comparable or better performance than the GPT-3.5-Turbo model.
Better sampling in explanation methods can prevent dieselgate-like deception
Jan 26, 2021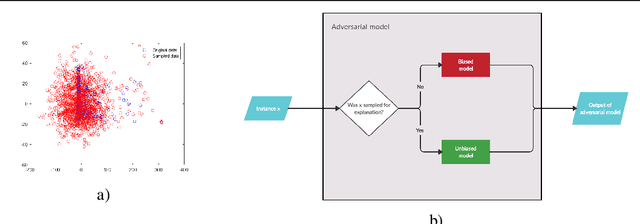

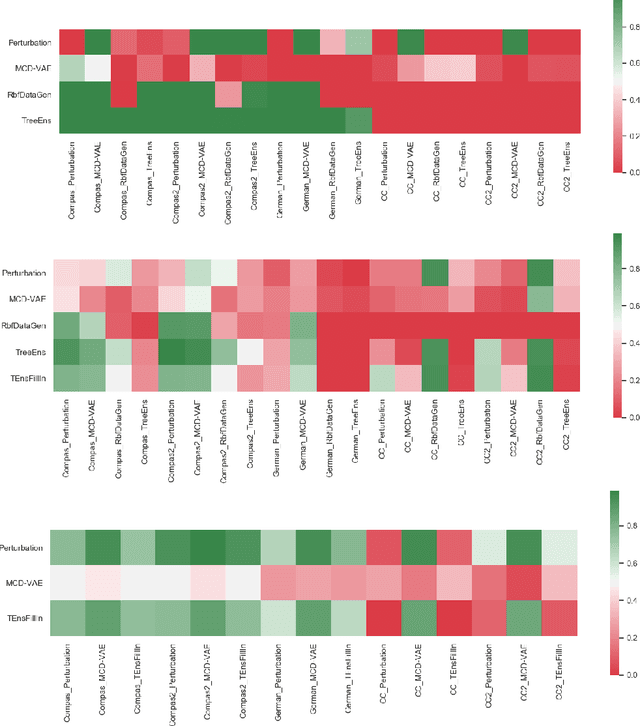
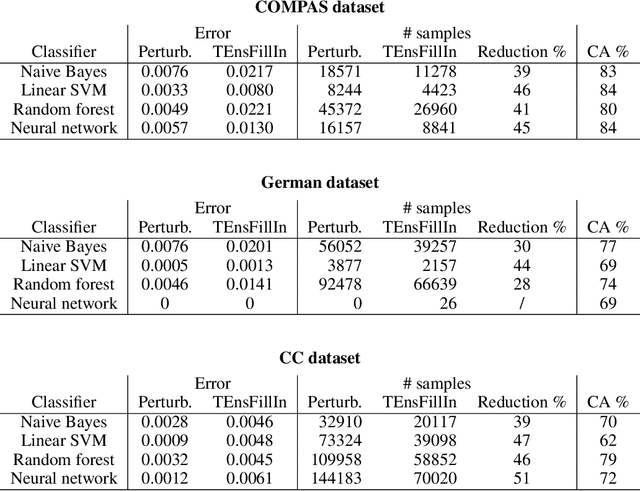
Machine learning models are used in many sensitive areas where besides predictive accuracy their comprehensibility is also important. Interpretability of prediction models is necessary to determine their biases and causes of errors, and is a necessary prerequisite for users' confidence. For complex state-of-the-art black-box models post-hoc model-independent explanation techniques are an established solution. Popular and effective techniques, such as IME, LIME, and SHAP, use perturbation of instance features to explain individual predictions. Recently, Slack et al. (2020) put their robustness into question by showing that their outcomes can be manipulated due to poor perturbation sampling employed. This weakness would allow dieselgate type cheating of owners of sensitive models who could deceive inspection and hide potentially unethical or illegal biases existing in their predictive models. This could undermine public trust in machine learning models and give rise to legal restrictions on their use. We show that better sampling in these explanation methods prevents malicious manipulations. The proposed sampling uses data generators that learn the training set distribution and generate new perturbation instances much more similar to the training set. We show that the improved sampling increases the robustness of the LIME and SHAP, while previously untested method IME is already the most robust of all.