 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges in Explaining Pretrained Clinical Text Classifiers
May 27, 2026Explaining the predictions of neural models in clinical NLP remains a significant challenge, especially for complex tasks involving long, unstructured medical texts. While post-hoc methods like LIME and SHAP are widely used, they often fall short when applied to clinical narratives. In this paper, we identify core limitations of token-level and perturbation-based explanation techniques through targeted demonstra- tions on a hospital length-of-stay prediction task. Our findings reveal issues such as overemphasis on non-informative tokens, instability in at- tributions, and high-confidence predictions for incoherent input variants. These results underscore the need for explanation strategies that are clin- ically meaningful, semantically grounded, and robust to linguistic noise.
* 9 pages, 7 figures. Accepted at the First Workshop on Responsible Healthcare using Machine Learning (RHCML 2025), co-located with ECML PKDD 2025
QFS-Composer: Query-focused summarization pipeline for less resourced languages
Apr 12, 2026Large language models (LLMs) demonstrate strong performance in text summarization, yet their effectiveness drops significantly across languages with restricted training resources. This work addresses the challenge of query-focused summarization (QFS) in less-resourced languages, where labeled datasets and evaluation tools are limited. We present a novel QFS framework, QFS-Composer, that integrates query decomposition, question generation (QG), question answering (QA), and abstractive summarization to improve the factual alignment of a summary with user intent. We test our approach on the Slovenian language. To enable high-quality supervision and evaluation, we develop the Slovenian QA and QG models based on a Slovene LLM and adapt evaluation approaches for reference-free summary evaluation. Empirical evaluation shows that the QA-guided summarization pipeline yields improved consistency and relevance over baseline LLMs. Our work establishes an extensible methodology for advancing QFS in less-resourced languages.
Better sampling in explanation methods can prevent dieselgate-like deception
Jan 26, 2021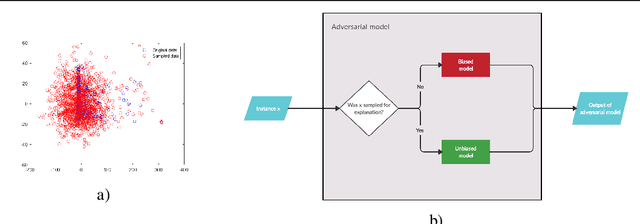

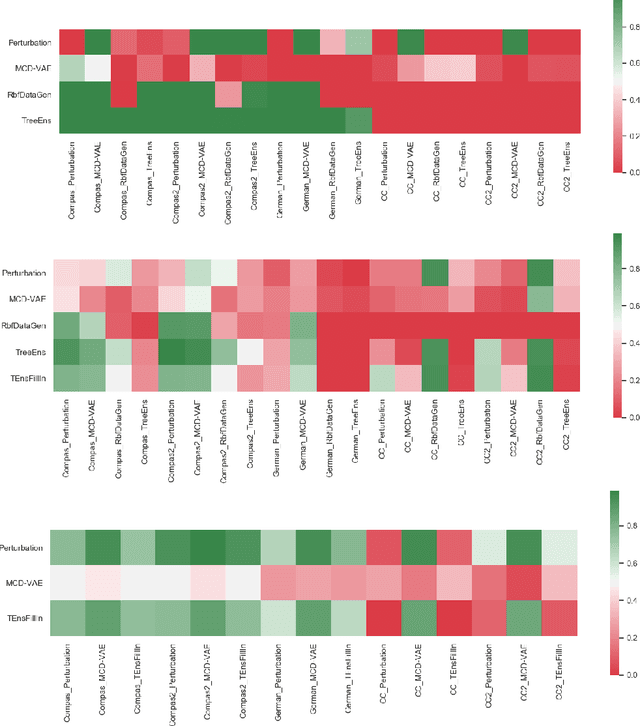
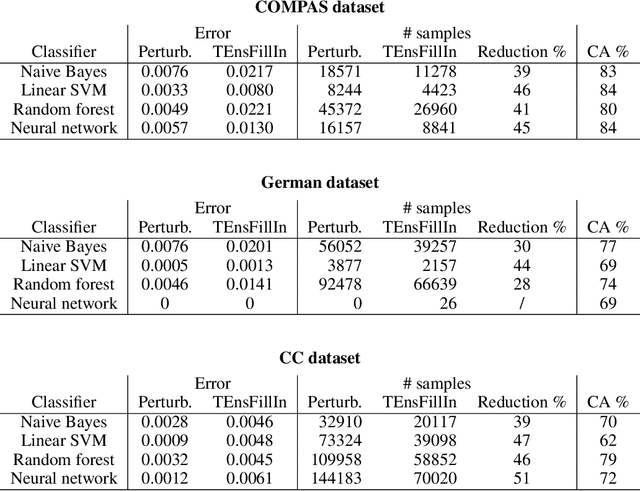
Machine learning models are used in many sensitive areas where besides predictive accuracy their comprehensibility is also important. Interpretability of prediction models is necessary to determine their biases and causes of errors, and is a necessary prerequisite for users' confidence. For complex state-of-the-art black-box models post-hoc model-independent explanation techniques are an established solution. Popular and effective techniques, such as IME, LIME, and SHAP, use perturbation of instance features to explain individual predictions. Recently, Slack et al. (2020) put their robustness into question by showing that their outcomes can be manipulated due to poor perturbation sampling employed. This weakness would allow dieselgate type cheating of owners of sensitive models who could deceive inspection and hide potentially unethical or illegal biases existing in their predictive models. This could undermine public trust in machine learning models and give rise to legal restrictions on their use. We show that better sampling in these explanation methods prevents malicious manipulations. The proposed sampling uses data generators that learn the training set distribution and generate new perturbation instances much more similar to the training set. We show that the improved sampling increases the robustness of the LIME and SHAP, while previously untested method IME is already the most robust of all.