 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD3R-Net: Dual-Domain Denoising Reconstruction Network for Robust Industrial Anomaly Detection
Jan 27, 2026Unsupervised anomaly detection (UAD) is a key ingredient of automated visual inspection in modern manufacturing. The reconstruction-based methods appeal because they have basic architectural design and they process data quickly but they produce oversmoothed results for high-frequency details. As a result, subtle defects are partially reconstructed rather than highlighted, which limits segmentation accuracy. We build on this line of work and introduce D3R-Net, a Dual-Domain Denoising Reconstruction framework that couples a self-supervised 'healing' task with frequency-aware regularization. During training, the network receives synthetically corrupted normal images and is asked to reconstruct the clean targets, which prevents trivial identity mapping and pushes the model to learn the manifold of defect-free textures. In addition to the spatial mean squared error, we employ a Fast Fourier Transform (FFT) magnitude loss that encourages consistency in the frequency domain. The implementation also allows an optional structural similarity (SSIM) term, which we study in an ablation. On the MVTec AD Hazelnut benchmark, D3R-Net with the FFT loss improves localization consistency over a spatial-only baseline: PRO AUC increases from 0.603 to 0.687, while image-level ROC AUC remains robust. Evaluated across fifteen MVTec categories, the FFT variant raises the average pixel ROC AUC from 0.733 to 0.751 and PRO AUC from 0.417 to 0.468 compared to the MSE-only baseline, at roughly 20 FPS on a single GPU. The network is trained from scratch and uses a lightweight convolutional autoencoder backbone, providing a practical alternative to heavy pre-trained feature embedding methods.
Motion-Compensated Latent Semantic Canvases for Visual Situational Awareness on Edge
Dec 29, 2025We propose Motion-Compensated Latent Semantic Canvases (MCLSC) for visual situational awareness on resource-constrained edge devices. The core idea is to maintain persistent semantic metadata in two latent canvases - a slowly accumulating static layer and a rapidly updating dynamic layer - defined in a baseline coordinate frame stabilized from the video stream. Expensive panoptic segmentation (Mask2Former) runs asynchronously and is motion-gated: inference is triggered only when motion indicates new information, while stabilization/motion compensation preserves a consistent coordinate system for latent semantic memory. On prerecorded 480p clips, our prototype reduces segmentation calls by >30x and lowers mean end-to-end processing time by >20x compared to naive per-frame segmentation, while maintaining coherent static/dynamic semantic overlays.
AI-Driven Decision-Making System for Hiring Process
Dec 17, 2025



Early-stage candidate validation is a major bottleneck in hiring, because recruiters must reconcile heterogeneous inputs (resumes, screening answers, code assignments, and limited public evidence). This paper presents an AI-driven, modular multi-agent hiring assistant that integrates (i) document and video preprocessing, (ii) structured candidate profile construction, (iii) public-data verification, (iv) technical/culture-fit scoring with explicit risk penalties, and (v) human-in-the-loop validation via an interactive interface. The pipeline is orchestrated by an LLM under strict constraints to reduce output variability and to generate traceable component-level rationales. Candidate ranking is computed by a configurable aggregation of technical fit, culture fit, and normalized risk penalties. The system is evaluated on 64 real applicants for a mid-level Python backend engineer role, using an experienced recruiter as the reference baseline and a second, less experienced recruiter for additional comparison. Alongside precision/recall, we propose an efficiency metric measuring expected time per qualified candidate. In this study, the system improves throughput and achieves 1.70 hours per qualified candidate versus 3.33 hours for the experienced recruiter, with substantially lower estimated screening cost, while preserving a human decision-maker as the final authority.
Brain Tumor Diagnosis and Classification via Pre-Trained Convolutional Neural Networks
Jul 27, 2022The brain tumor is the most aggressive kind of tumor and can cause low life expectancy if diagnosed at the later stages. Manual identification of brain tumors is tedious and prone to errors. Misdiagnosis can lead to false treatment and thus reduce the chances of survival for the patient. Medical resonance imaging (MRI) is the conventional method used to diagnose brain tumors and their types. This paper attempts to eliminate the manual process from the diagnosis process and use machine learning instead. We proposed the use of pretrained convolutional neural networks (CNN) for the diagnosis and classification of brain tumors. Three types of tumors were classified with one class of non-tumor MRI images. Networks that has been used are ResNet50, EfficientNetB1, EfficientNetB7, EfficientNetV2B1. EfficientNet has shown promising results due to its scalable nature. EfficientNetB1 showed the best results with training and validation accuracy of 87.67% and 89.55%, respectively.
Forest and Water Bodies Segmentation Through Satellite Images Using U-Net
Jul 12, 2022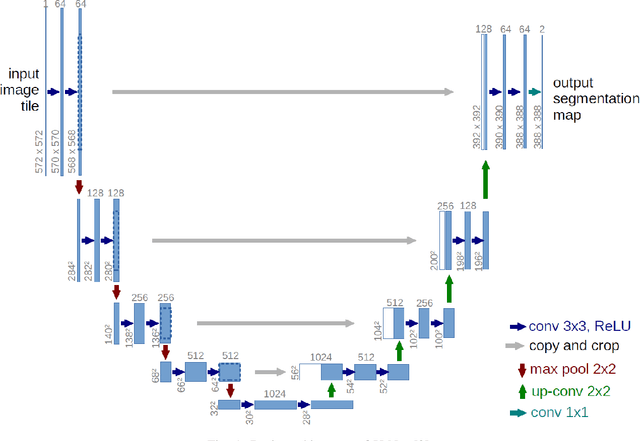
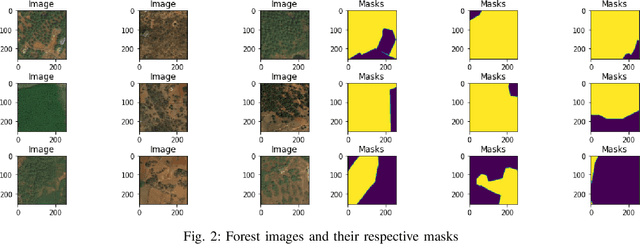

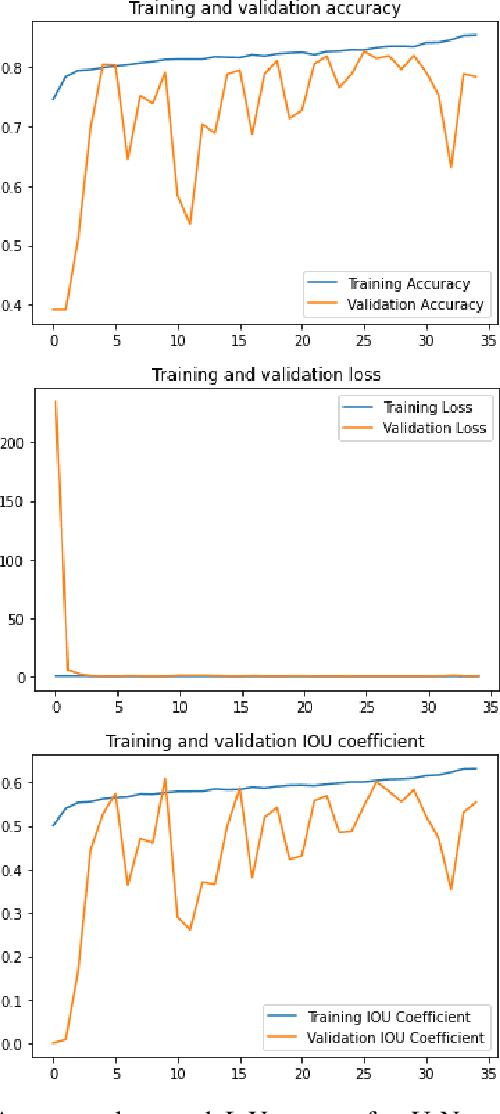
Global environment monitoring is a task that requires additional attention in the contemporary rapid climate change environment. This includes monitoring the rate of deforestation and areas affected by flooding. Satellite imaging has greatly helped monitor the earth, and deep learning techniques have helped to automate this monitoring process. This paper proposes a solution for observing the area covered by the forest and water. To achieve this task UNet model has been proposed, which is an image segmentation model. The model achieved a validation accuracy of 82.55% and 82.92% for the segmentation of areas covered by forest and water, respectively.
Unified vector space mapping for knowledge representation systems
Feb 21, 2015One of the most significant problems which inhibits further developments in the areas of Knowledge Representation and Artificial Intelligence is a problem of semantic alignment or knowledge mapping. The progress in its solution will be greatly beneficial for further advances of information retrieval, ontology alignment, relevance calculation, text mining, natural language processing etc. In the paper the concept of multidimensional global knowledge map, elaborated through unsupervised extraction of dependencies from large documents corpus, is proposed. In addition, the problem of direct Human - Knowledge Representation System interface is addressed and a concept of adaptive decoder proposed for the purpose of interaction with previously described unified mapping model. In combination these two approaches are suggested as basis for a development of a new generation of knowledge representation systems.