 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Prior of a Googol Gaussians: a Tensor Ring Induced Prior for Generative Models
Oct 29, 2019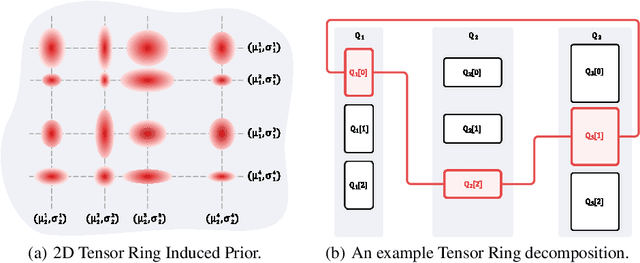
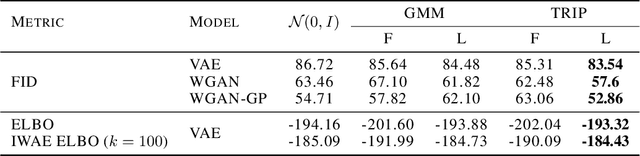
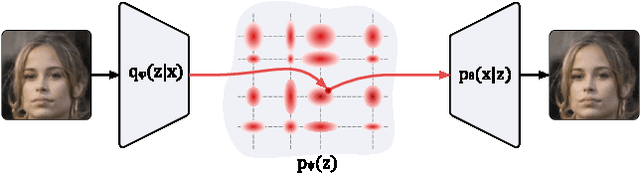

Generative models produce realistic objects in many domains, including text, image, video, and audio synthesis. Most popular models---Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs)---usually employ a standard Gaussian distribution as a prior. Previous works show that the richer family of prior distributions may help to avoid the mode collapse problem in GANs and to improve the evidence lower bound in VAEs. We propose a new family of prior distributions---Tensor Ring Induced Prior (TRIP)---that packs an exponential number of Gaussians into a high-dimensional lattice with a relatively small number of parameters. We show that these priors improve Fr\'echet Inception Distance for GANs and Evidence Lower Bound for VAEs. We also study generative models with TRIP in the conditional generation setup with missing conditions. Altogether, we propose a novel plug-and-play framework for generative models that can be utilized in any GAN and VAE-like architectures.
Subspace Inference for Bayesian Deep Learning
Jul 17, 2019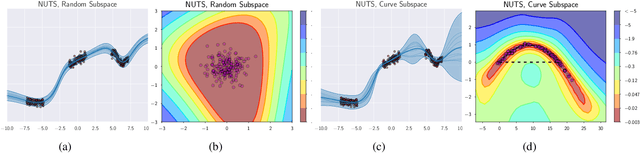
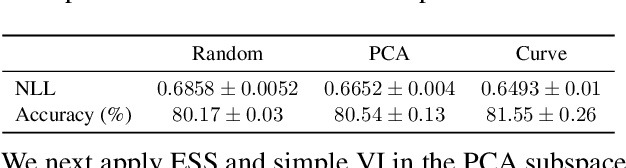
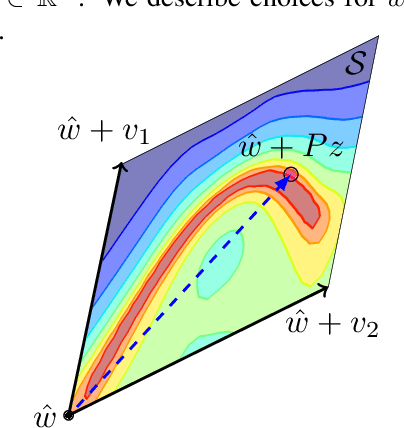

Bayesian inference was once a gold standard for learning with neural networks, providing accurate full predictive distributions and well calibrated uncertainty. However, scaling Bayesian inference techniques to deep neural networks is challenging due to the high dimensionality of the parameter space. In this paper, we construct low-dimensional subspaces of parameter space, such as the first principal components of the stochastic gradient descent (SGD) trajectory, which contain diverse sets of high performing models. In these subspaces, we are able to apply elliptical slice sampling and variational inference, which struggle in the full parameter space. We show that Bayesian model averaging over the induced posterior in these subspaces produces accurate predictions and well calibrated predictive uncertainty for both regression and image classification.
The Implicit Metropolis-Hastings Algorithm
Jun 09, 2019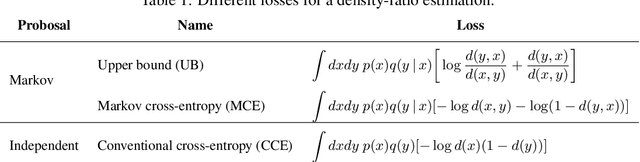
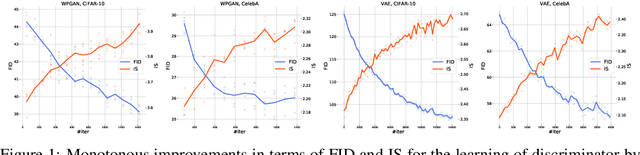

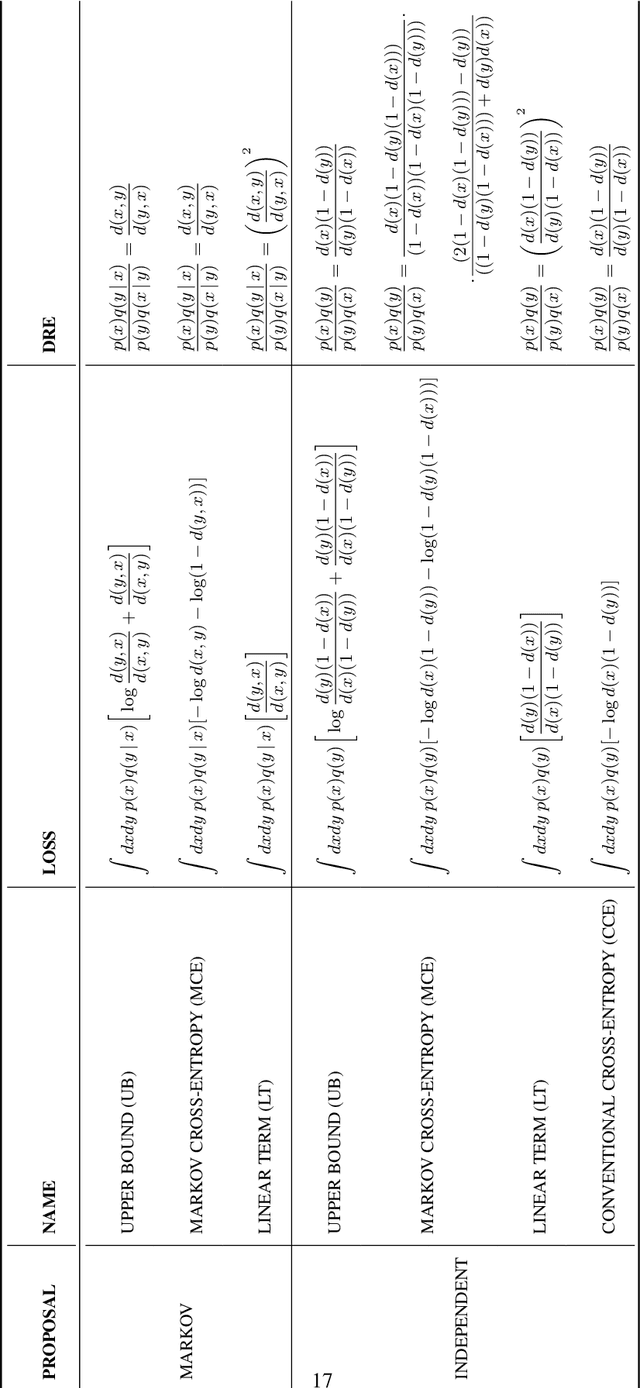
Recent works propose using the discriminator of a GAN to filter out unrealistic samples of the generator. We generalize these ideas by introducing the implicit Metropolis-Hastings algorithm. For any implicit probabilistic model and a target distribution represented by a set of samples, implicit Metropolis-Hastings operates by learning a discriminator to estimate the density-ratio and then generating a chain of samples. Since the approximation of density ratio introduces an error on every step of the chain, it is crucial to analyze the stationary distribution of such chain. For that purpose, we present a theoretical result stating that the discriminator loss upper bounds the total variation distance between the target distribution and the stationary distribution. Finally, we validate the proposed algorithm both for independent and Markov proposals on CIFAR-10 and CelebA datasets.
Importance Weighted Hierarchical Variational Inference
May 08, 2019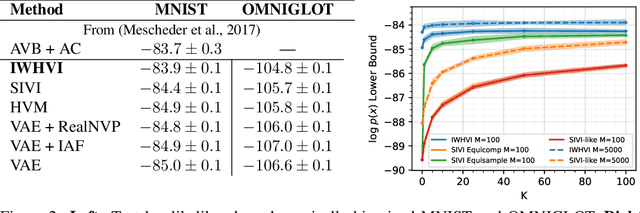
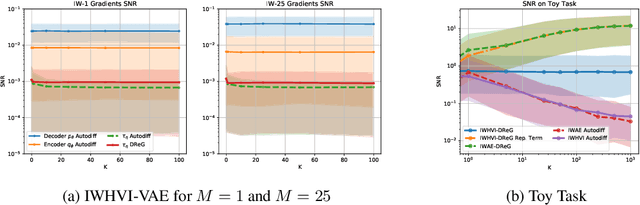
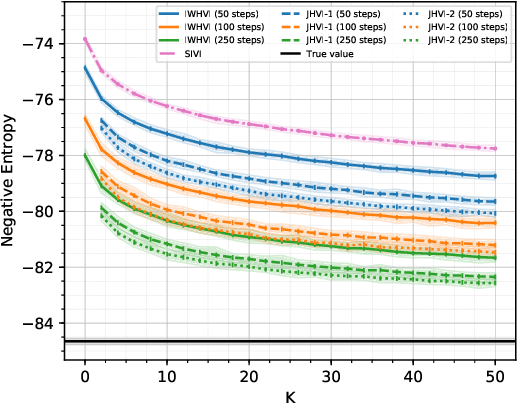
Variational Inference is a powerful tool in the Bayesian modeling toolkit, however, its effectiveness is determined by the expressivity of the utilized variational distributions in terms of their ability to match the true posterior distribution. In turn, the expressivity of the variational family is largely limited by the requirement of having a tractable density function. To overcome this roadblock, we introduce a new family of variational upper bounds on a marginal log density in the case of hierarchical models (also known as latent variable models). We then give an upper bound on the Kullback-Leibler divergence and derive a family of increasingly tighter variational lower bounds on the otherwise intractable standard evidence lower bound for hierarchical variational distributions, enabling the use of more expressive approximate posteriors. We show that previously known methods, such as Hierarchical Variational Models, Semi-Implicit Variational Inference and Doubly Semi-Implicit Variational Inference can be seen as special cases of the proposed approach, and empirically demonstrate superior performance of the proposed method in a set of experiments.
Semi-Conditional Normalizing Flows for Semi-Supervised Learning
May 01, 2019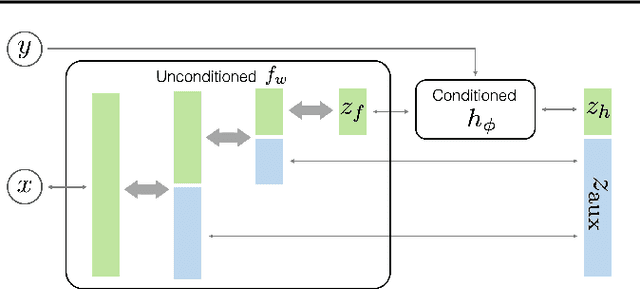
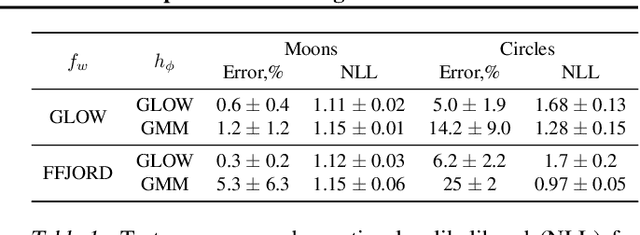
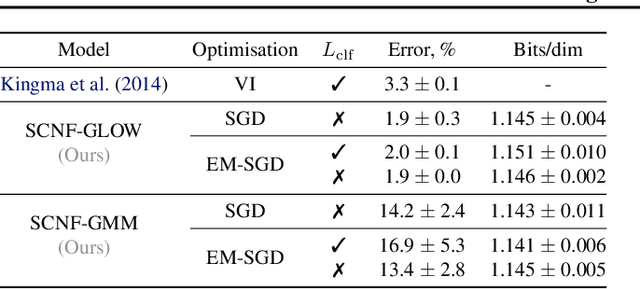
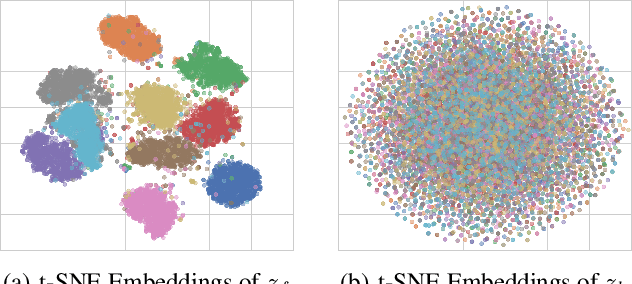
This paper proposes a semi-conditional normalizing flow model for semi-supervised learning. The model uses both labelled and unlabeled data to learn an explicit model of joint distribution over objects and labels. Semi-conditional architecture of the model allows us to efficiently compute a value and gradients of the marginal likelihood for unlabeled objects. The conditional part of the model is based on a proposed conditional coupling layer. We demonstrate performance of the model for semi-supervised classification problem on different datasets. The model outperforms the baseline approach based on variational auto-encoders on MNIST dataset.
User-Controllable Multi-Texture Synthesis with Generative Adversarial Networks
Apr 24, 2019We propose a novel multi-texture synthesis model based on generative adversarial networks (GANs) with a user-controllable mechanism. The user control ability allows to explicitly specify the texture which should be generated by the model. This property follows from using an encoder part which learns a latent representation for each texture from the dataset. To ensure a dataset coverage, we use an adversarial loss function that penalizes for incorrect reproductions of a given texture. In experiments, we show that our model can learn descriptive texture manifolds for large datasets and from raw data such as a collection of high-resolution photos. Moreover, we apply our method to produce 3D textures and show that it outperforms existing baselines.
A Simple Baseline for Bayesian Uncertainty in Deep Learning
Feb 07, 2019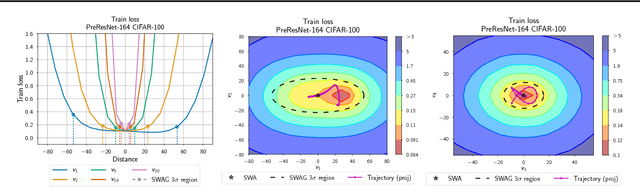
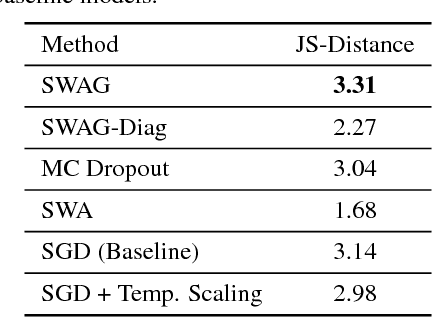
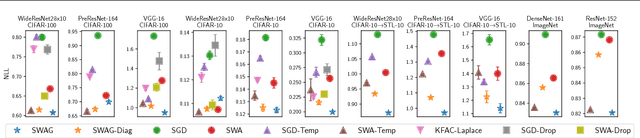
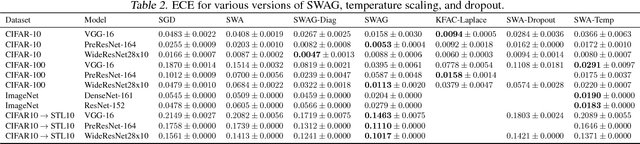
We propose SWA-Gaussian (SWAG), a simple, scalable, and general purpose approach for uncertainty representation and calibration in deep learning. Stochastic Weight Averaging (SWA), which computes the first moment of stochastic gradient descent (SGD) iterates with a modified learning rate schedule, has recently been shown to improve generalization in deep learning. With SWAG, we fit a Gaussian using the SWA solution as the first moment and a low rank plus diagonal covariance also derived from the SGD iterates, forming an approximate posterior distribution over neural network weights; we then sample from this Gaussian distribution to perform Bayesian model averaging. We empirically find that SWAG approximates the shape of the true posterior, in accordance with results describing the stationary distribution of SGD iterates. Moreover, we demonstrate that SWAG performs well on a wide variety of computer vision tasks, including out of sample detection, calibration, and transfer learning, in comparison to many popular alternatives including MC dropout, KFAC Laplace, and temperature scaling.
Bayesian Sparsification of Gated Recurrent Neural Networks
Dec 12, 2018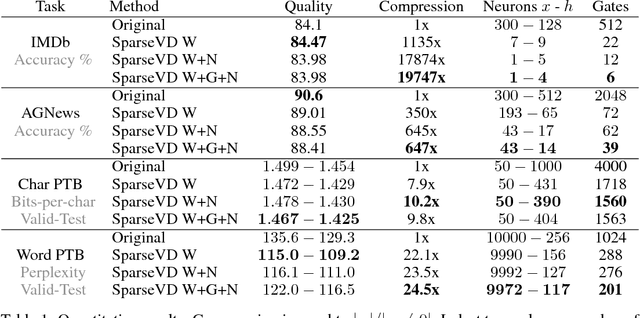

Bayesian methods have been successfully applied to sparsify weights of neural networks and to remove structure units from the networks, e. g. neurons. We apply and further develop this approach for gated recurrent architectures. Specifically, in addition to sparsification of individual weights and neurons, we propose to sparsify preactivations of gates and information flow in LSTM. It makes some gates and information flow components constant, speeds up forward pass and improves compression. Moreover, the resulting structure of gate sparsity is interpretable and depends on the task. Code is available on github: https://github.com/tipt0p/SparseBayesianRNN
ReSet: Learning Recurrent Dynamic Routing in ResNet-like Neural Networks
Nov 11, 2018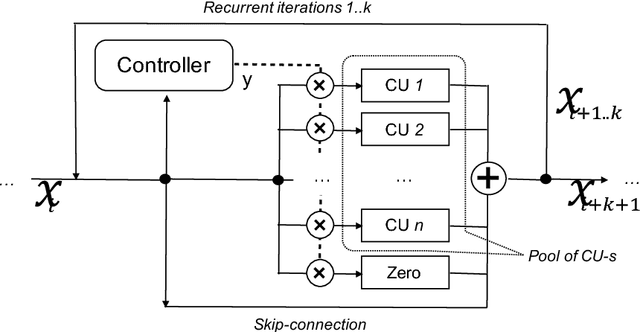
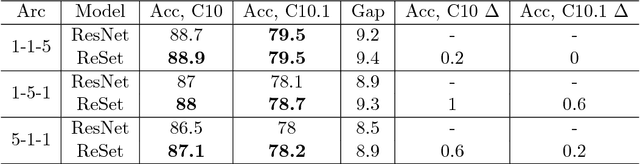
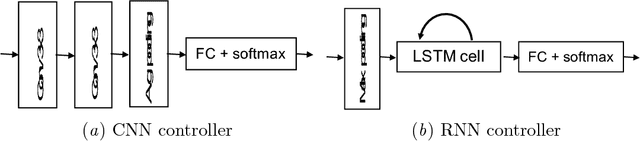
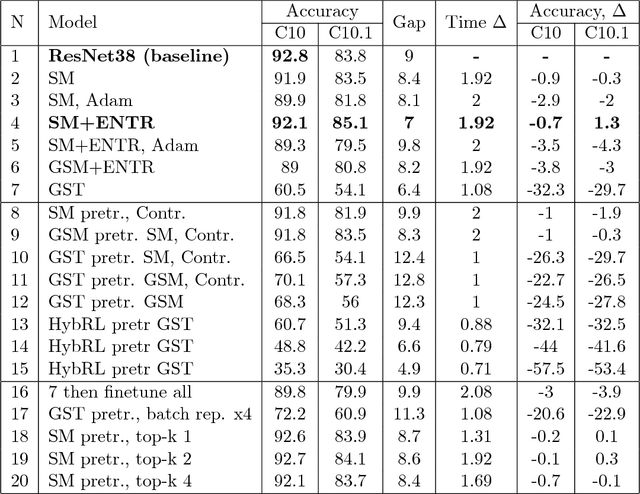
Neural Network is a powerful Machine Learning tool that shows outstanding performance in Computer Vision, Natural Language Processing, and Artificial Intelligence. In particular, recently proposed ResNet architecture and its modifications produce state-of-the-art results in image classification problems. ResNet and most of the previously proposed architectures have a fixed structure and apply the same transformation to all input images. In this work, we develop a ResNet-based model that dynamically selects Computational Units (CU) for each input object from a learned set of transformations. Dynamic selection allows the network to learn a sequence of useful transformations and apply only required units to predict the image label. We compare our model to ResNet-38 architecture and achieve better results than the original ResNet on CIFAR-10.1 test set. While examining the produced paths, we discovered that the network learned different routes for images from different classes and similar routes for similar images.
* Published in Proceedings of The 10th Asian Conference on Machine Learning, http://proceedings.mlr.press/v95/kemaev18a.html
Variational Dropout via Empirical Bayes
Nov 01, 2018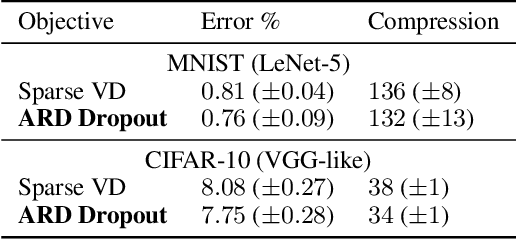
We study the Automatic Relevance Determination procedure applied to deep neural networks. We show that ARD applied to Bayesian DNNs with Gaussian approximate posterior distributions leads to a variational bound similar to that of variational dropout, and in the case of a fixed dropout rate, objectives are exactly the same. Experimental results show that the two approaches yield comparable results in practice even when the dropout rates are trained. This leads to an alternative Bayesian interpretation of dropout and mitigates some of the theoretical issues that arise with the use of improper priors in the variational dropout model. Additionally, we explore the use of the hierarchical priors in ARD and show that it helps achieve higher sparsity for the same accuracy.