 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReintroducing Straight-Through Estimators as Principled Methods for Stochastic Binary Networks
Jun 11, 2020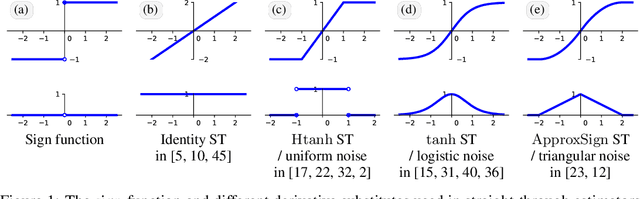
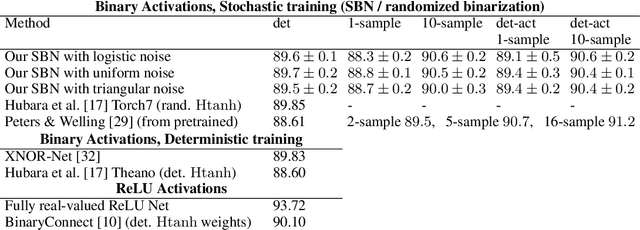
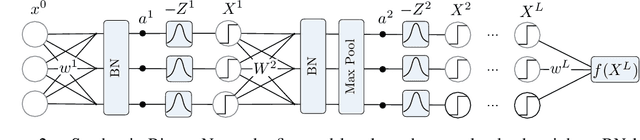

Training neural networks with binary weights and activations is a challenging problem due to the lack of gradients and difficulty of optimization over discrete weights. Many successful experimental results have been recently achieved using the empirical straight-through estimation approach. This approach has generated a variety of ad-hoc rules for propagating gradients through non-differentiable activations and updating discrete weights. We put such methods on a solid basis by obtaining them as viable approximations in the stochastic binary network (SBN) model with Bernoulli weights. In this model gradients are well-defined and the weight probabilities can be optimized by continuous techniques. By choosing the activation noises in SBN appropriately and choosing mirror descent (MD) for optimization, we obtain methods that closely resemble several existing straight-through variants, but unlike them, all work reliably and produce equally good results. We further show that variational inference for Bayesian learning of Binary weights can be implemented using MD updates with the same simplicity.
Deep Ensembles on a Fixed Memory Budget: One Wide Network or Several Thinner Ones?
May 14, 2020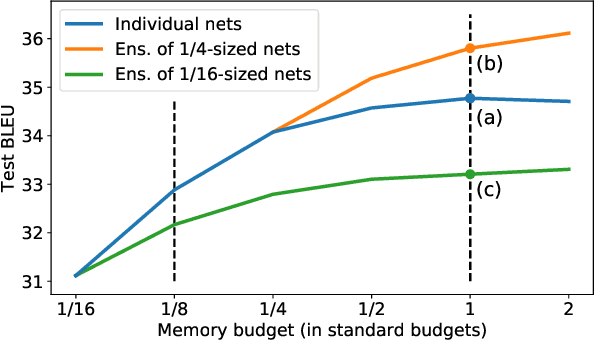
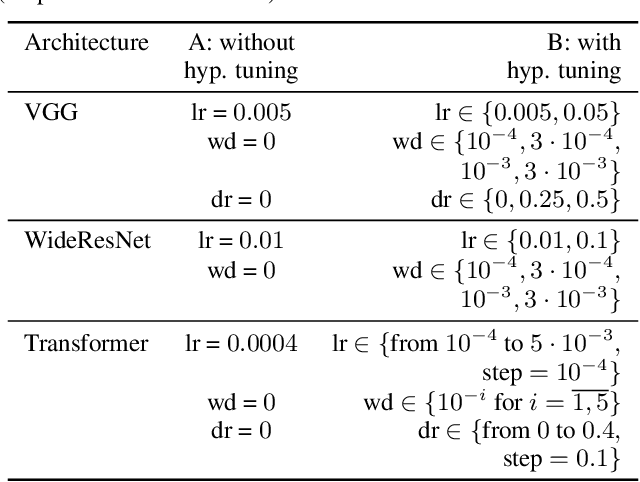
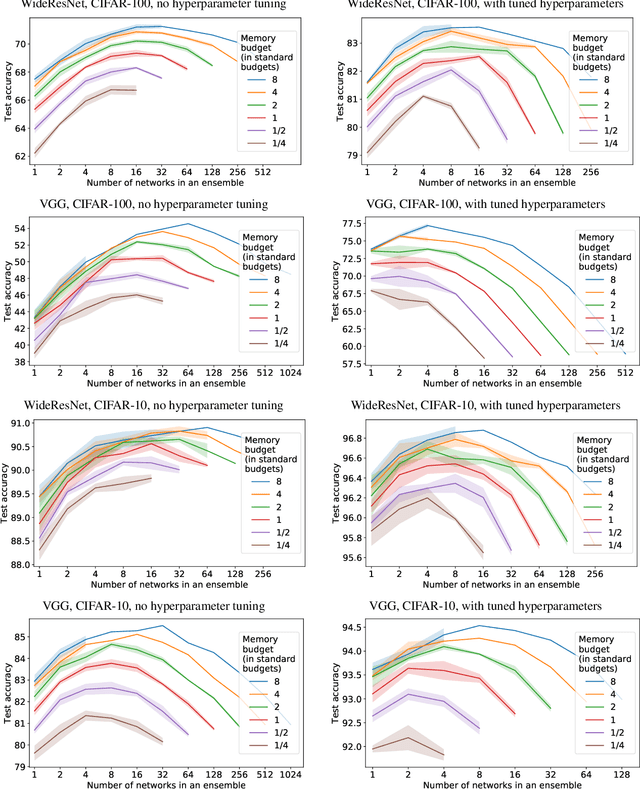
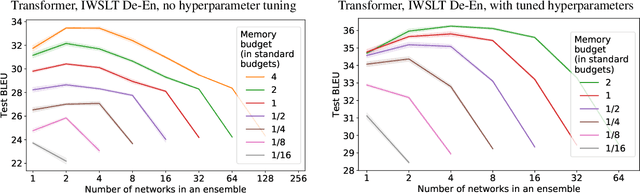
One of the generally accepted views of modern deep learning is that increasing the number of parameters usually leads to better quality. The two easiest ways to increase the number of parameters is to increase the size of the network, e.g. width, or to train a deep ensemble; both approaches improve the performance in practice. In this work, we consider a fixed memory budget setting, and investigate, what is more effective: to train a single wide network, or to perform a memory split -- to train an ensemble of several thinner networks, with the same total number of parameters? We find that, for large enough budgets, the number of networks in the ensemble, corresponding to the optimal memory split, is usually larger than one. Interestingly, this effect holds for the commonly used sizes of the standard architectures. For example, one WideResNet-28-10 achieves significantly worse test accuracy on CIFAR-100 than an ensemble of sixteen thinner WideResNets: 80.6% and 82.52% correspondingly. We call the described effect the Memory Split Advantage and show that it holds for a variety of datasets and model architectures.
Controlling Overestimation Bias with Truncated Mixture of Continuous Distributional Quantile Critics
May 08, 2020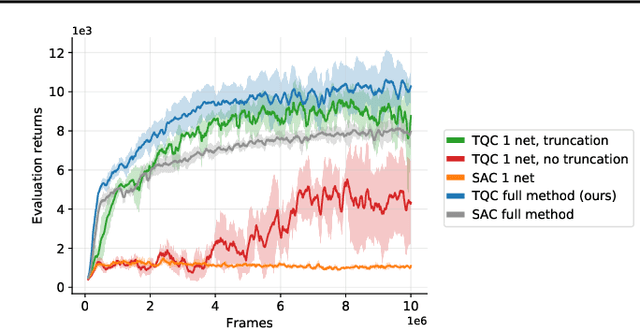

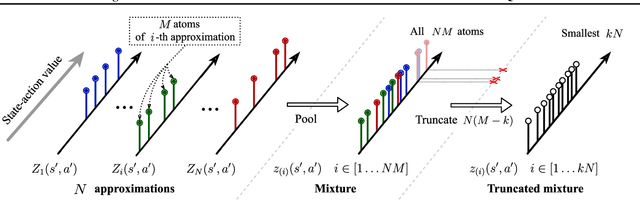
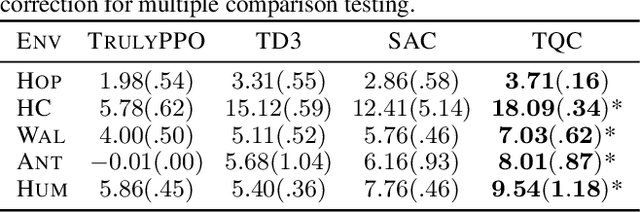
The overestimation bias is one of the major impediments to accurate off-policy learning. This paper investigates a novel way to alleviate the overestimation bias in a continuous control setting. Our method---Truncated Quantile Critics, TQC,---blends three ideas: distributional representation of a critic, truncation of critics prediction, and ensembling of multiple critics. Distributional representation and truncation allow for arbitrary granular overestimation control, while ensembling provides additional score improvements. TQC outperforms the current state of the art on all environments from the continuous control benchmark suite, demonstrating 25% improvement on the most challenging Humanoid environment.
Deterministic Decoding for Discrete Data in Variational Autoencoders
Mar 04, 2020
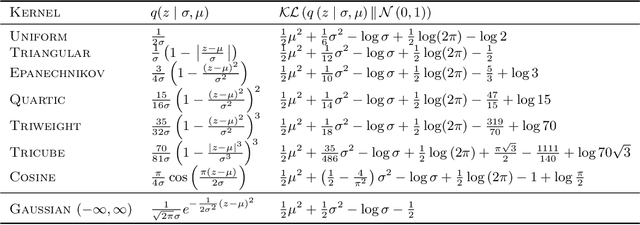
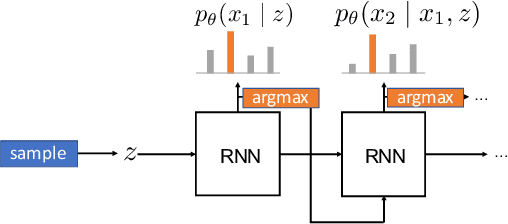
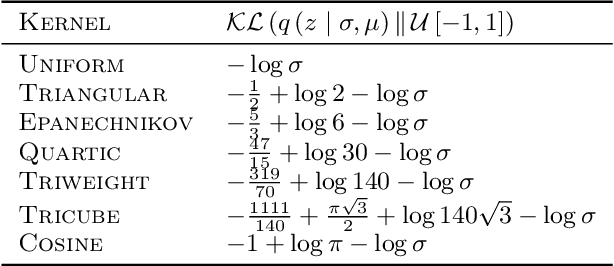
Variational autoencoders are prominent generative models for modeling discrete data. However, with flexible decoders, they tend to ignore the latent codes. In this paper, we study a VAE model with a deterministic decoder (DD-VAE) for sequential data that selects the highest-scoring tokens instead of sampling. Deterministic decoding solely relies on latent codes as the only way to produce diverse objects, which improves the structure of the learned manifold. To implement DD-VAE, we propose a new class of bounded support proposal distributions and derive Kullback-Leibler divergence for Gaussian and uniform priors. We also study a continuous relaxation of deterministic decoding objective function and analyze the relation of reconstruction accuracy and relaxation parameters. We demonstrate the performance of DD-VAE on multiple datasets, including molecular generation and optimization problems.
Stochasticity in Neural ODEs: An Empirical Study
Feb 22, 2020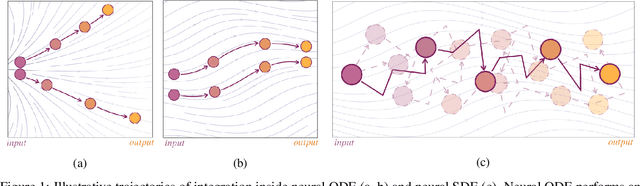
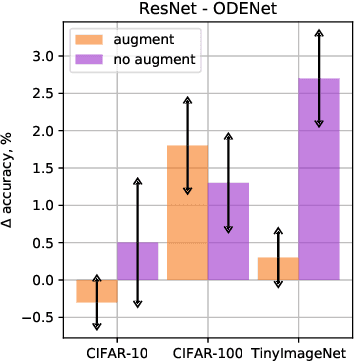
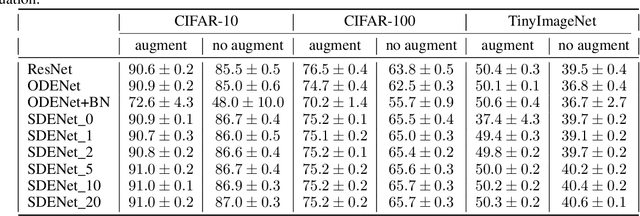
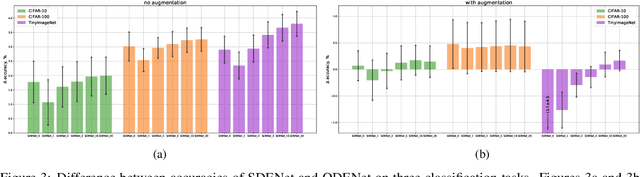
Stochastic regularization of neural networks (e.g. dropout) is a wide-spread technique in deep learning that allows for better generalization. Despite its success, continuous-time models, such as neural ordinary differential equation (ODE), usually rely on a completely deterministic feed-forward operation. This work provides an empirical study of stochastically regularized neural ODE on several image-classification tasks (CIFAR-10, CIFAR-100, TinyImageNet). Building upon the formalism of stochastic differential equations (SDEs), we demonstrate that neural SDE is able to outperform its deterministic counterpart. Further, we show that data augmentation during the training improves the performance of both deterministic and stochastic versions of the same model. However, the improvements obtained by the data augmentation completely eliminate the empirical gains of the stochastic regularization, making the difference in the performance of neural ODE and neural SDE negligible.
Greedy Policy Search: A Simple Baseline for Learnable Test-Time Augmentation
Feb 21, 2020
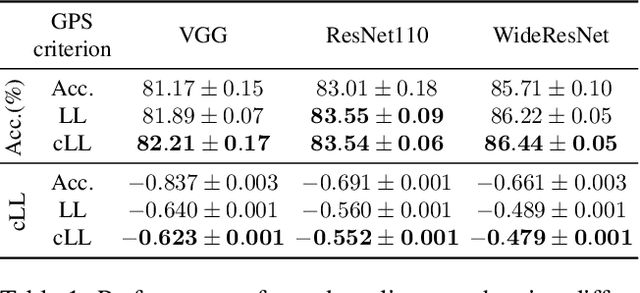
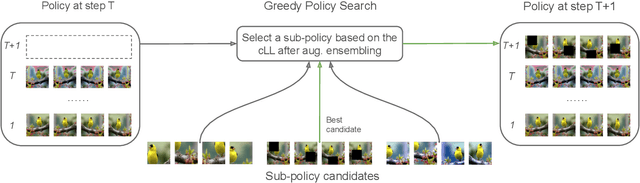

Test-time data augmentation---averaging the predictions of a machine learning model across multiple augmented samples of data---is a widely used technique that improves the predictive performance. While many advanced learnable data augmentation techniques have emerged in recent years, they are focused on the training phase. Such techniques are not necessarily optimal for test-time augmentation and can be outperformed by a policy consisting of simple crops and flips. The primary goal of this paper is to demonstrate that test-time augmentation policies can be successfully learned too. We~introduce \emph{greedy policy search} (GPS), a simple but high-performing method for learning a policy of test-time augmentation. We demonstrate that augmentation policies learned with GPS achieve superior predictive performance on image classification problems, provide better in-domain uncertainty estimation, and improve the robustness to domain shift.
Pitfalls of In-Domain Uncertainty Estimation and Ensembling in Deep Learning
Feb 15, 2020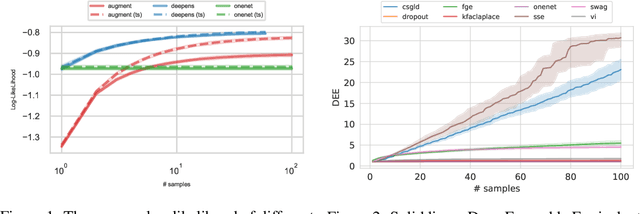


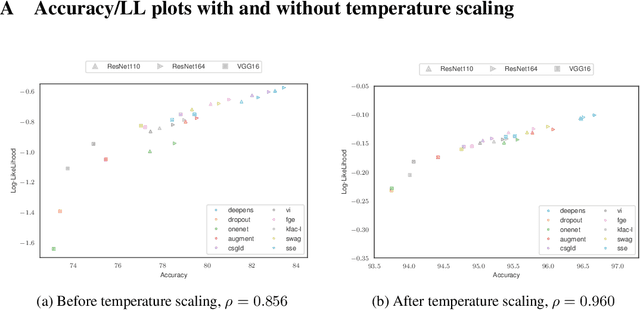
Uncertainty estimation and ensembling methods go hand-in-hand. Uncertainty estimation is one of the main benchmarks for assessment of ensembling performance. At the same time, deep learning ensembles have provided state-of-the-art results in uncertainty estimation. In this work, we focus on in-domain uncertainty for image classification. We explore the standards for its quantification and point out pitfalls of existing metrics. Avoiding these pitfalls, we perform a broad study of different ensembling techniques. To provide more insight in this study, we introduce the deep ensemble equivalent score (DEE) and show that many sophisticated ensembling techniques are equivalent to an ensemble of only few independently trained networks in terms of test performance.
MLRG Deep Curvature
Dec 20, 2019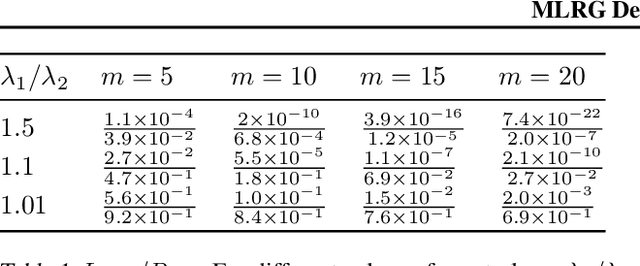
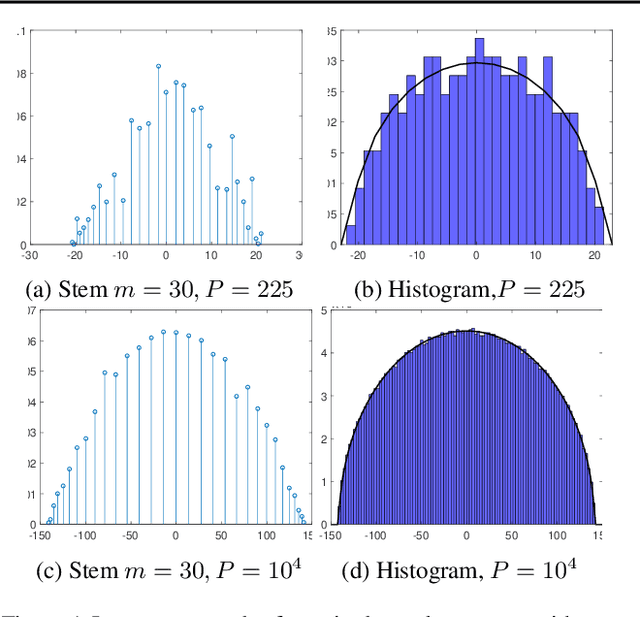
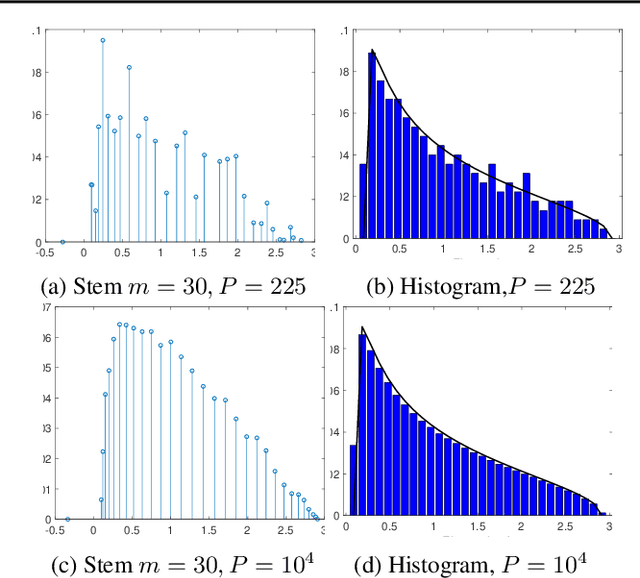
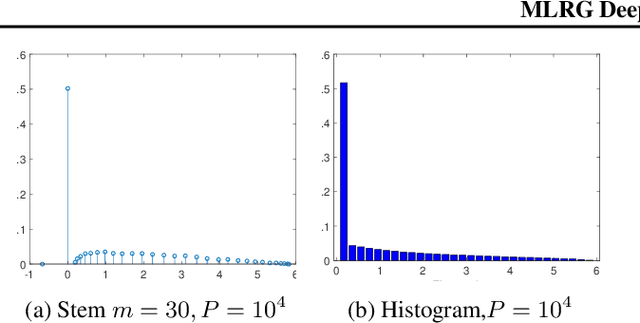
We present MLRG Deep Curvature suite, a PyTorch-based, open-source package for analysis and visualisation of neural network curvature and loss landscape. Despite of providing rich information into properties of neural network and useful for a various designed tasks, curvature information is still not made sufficient use for various reasons, and our method aims to bridge this gap. We present a primer, including its main practical desiderata and common misconceptions, of \textit{Lanczos algorithm}, the theoretical backbone of our package, and present a series of examples based on synthetic toy examples and realistic modern neural networks tested on CIFAR datasets, and show the superiority of our package against existing competing approaches for the similar purposes.
Low-variance Black-box Gradient Estimates for the Plackett-Luce Distribution
Nov 22, 2019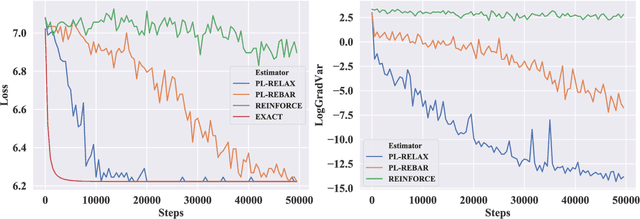
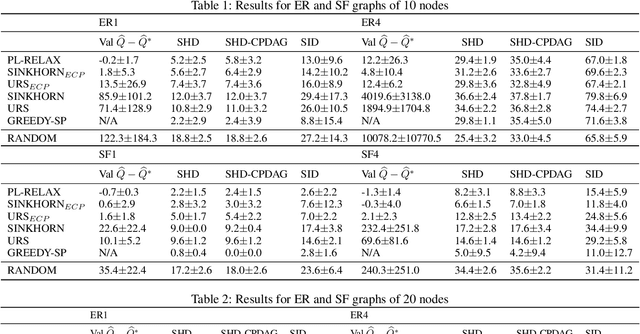
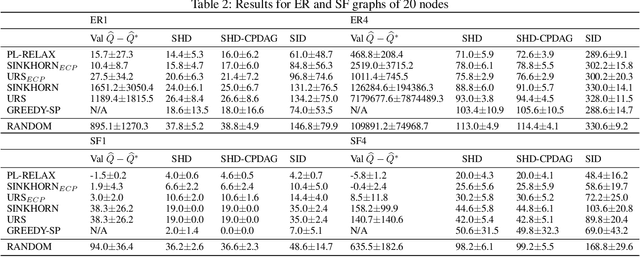
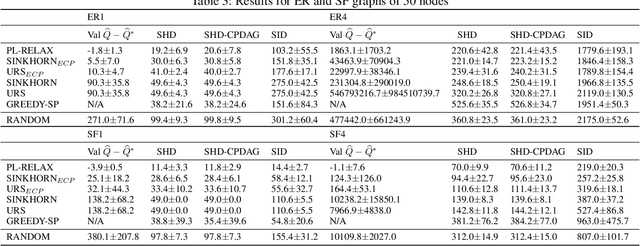
Learning models with discrete latent variables using stochastic gradient descent remains a challenge due to the high variance of gradient estimates. Modern variance reduction techniques mostly consider categorical distributions and have limited applicability when the number of possible outcomes becomes large. In this work, we consider models with latent permutations and propose control variates for the Plackett-Luce distribution. In particular, the control variates allow us to optimize black-box functions over permutations using stochastic gradient descent. To illustrate the approach, we consider a variety of causal structure learning tasks for continuous and discrete data. We show that our method outperforms competitive relaxation-based optimization methods and is also applicable to non-differentiable score functions.
Structured Sparsification of Gated Recurrent Neural Networks
Nov 13, 2019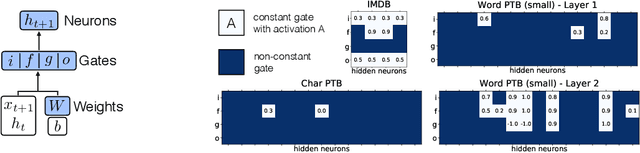
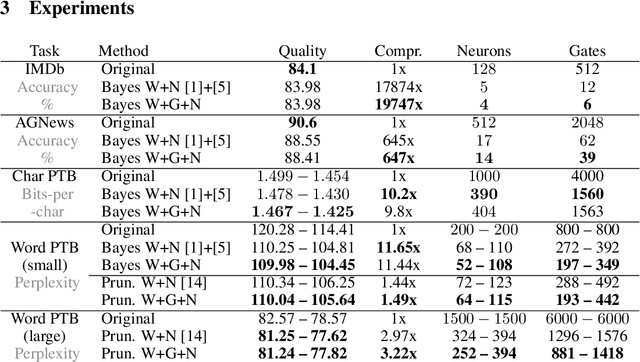
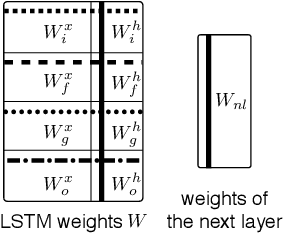

Recently, a lot of techniques were developed to sparsify the weights of neural networks and to remove networks' structure units, e.g. neurons. We adjust the existing sparsification approaches to the gated recurrent architectures. Specifically, in addition to the sparsification of weights and neurons, we propose sparsifying the preactivations of gates. This makes some gates constant and simplifies LSTM structure. We test our approach on the text classification and language modeling tasks. We observe that the resulting structure of gate sparsity depends on the task and connect the learned structure to the specifics of the particular tasks. Our method also improves neuron-wise compression of the model in most of the tasks.