 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Stay or Not to Stay in the Pre-train Basin: Insights on Ensembling in Transfer Learning
Mar 06, 2023Transfer learning and ensembling are two popular techniques for improving the performance and robustness of neural networks. Due to the high cost of pre-training, ensembles of models fine-tuned from a single pre-trained checkpoint are often used in practice. Such models end up in the same basin of the loss landscape and thus have limited diversity. In this work, we study if it is possible to improve ensembles trained from a single pre-trained checkpoint by better exploring the pre-train basin or a close vicinity outside of it. We show that while exploration of the pre-train basin may be beneficial for the ensemble, leaving the basin results in losing the benefits of transfer learning and degradation of the ensemble quality.
Differentiable Rendering with Reparameterized Volume Sampling
Feb 21, 2023



In view synthesis, a neural radiance field approximates underlying density and radiance fields based on a sparse set of scene pictures. To generate a pixel of a novel view, it marches a ray through the pixel and computes a weighted sum of radiance emitted from a dense set of ray points. This rendering algorithm is fully differentiable and facilitates gradient-based optimization of the fields. However, in practice, only a tiny opaque portion of the ray contributes most of the radiance to the sum. We propose an end-to-end differentiable sampling algorithm based on inverse transform sampling. It generates samples according to the probability distribution induced by the density field and picks non-transparent points on the ray. We utilize the algorithm in two ways. First, we propose a novel rendering approach based on Monte Carlo estimates. Such a rendering algorithm allows for optimizing a neural radiance field with just a few radiance field evaluations per ray. Second, we use the sampling algorithm to modify the hierarchical scheme used in the original work on neural radiance fields. In this setup, we were able to train the proposal network end-to-end without any auxiliary losses and improved the baseline performance.
Star-Shaped Denoising Diffusion Probabilistic Models
Feb 10, 2023Methods based on Denoising Diffusion Probabilistic Models (DDPM) became a ubiquitous tool in generative modeling. However, they are mostly limited to Gaussian and discrete diffusion processes. We propose Star-Shaped Denoising Diffusion Probabilistic Models (SS-DDPM), a model with a non-Markovian diffusion-like noising process. In the case of Gaussian distributions, this model is equivalent to Markovian DDPMs. However, it can be defined and applied with arbitrary noising distributions, and admits efficient training and sampling algorithms for a wide range of distributions that lie in the exponential family. We provide a simple recipe for designing diffusion-like models with distributions like Beta, von Mises--Fisher, Dirichlet, Wishart and others, which can be especially useful when data lies on a constrained manifold such as the unit sphere, the space of positive semi-definite matrices, the probabilistic simplex, etc. We evaluate the model in different settings and find it competitive even on image data, where Beta SS-DDPM achieves results comparable to a Gaussian DDPM.
StyleDomain: Analysis of StyleSpace for Domain Adaptation of StyleGAN
Dec 20, 2022



Domain adaptation of GANs is a problem of fine-tuning the state-of-the-art GAN models (e.g. StyleGAN) pretrained on a large dataset to a specific domain with few samples (e.g. painting faces, sketches, etc.). While there are a great number of methods that tackle this problem in different ways there are still many important questions that remain unanswered. In this paper, we provide a systematic and in-depth analysis of the domain adaptation problem of GANs, focusing on the StyleGAN model. First, we perform a detailed exploration of the most important parts of StyleGAN that are responsible for adapting the generator to a new domain depending on the similarity between the source and target domains. In particular, we show that affine layers of StyleGAN can be sufficient for fine-tuning to similar domains. Second, inspired by these findings, we investigate StyleSpace to utilize it for domain adaptation. We show that there exist directions in the StyleSpace that can adapt StyleGAN to new domains. Further, we examine these directions and discover their many surprising properties. Finally, we leverage our analysis and findings to deliver practical improvements and applications in such standard tasks as image-to-image translation and cross-domain morphing.
Entropic Neural Optimal Transport via Diffusion Processes
Nov 02, 2022



We propose a novel neural algorithm for the fundamental problem of computing the entropic optimal transport (EOT) plan between probability distributions which are accessible by samples. Our algorithm is based on the saddle point reformulation of the dynamic version of EOT which is known as the Schr\"odinger Bridge problem. In contrast to the prior methods for large-scale EOT, our algorithm is end-to-end and consists of a single learning step, has fast inference procedure, and allows handling small values of the entropy regularization coefficient which is of particular importance in some applied problems. Empirically, we show the performance of the method on several large-scale EOT tasks.
HyperDomainNet: Universal Domain Adaptation for Generative Adversarial Networks
Oct 18, 2022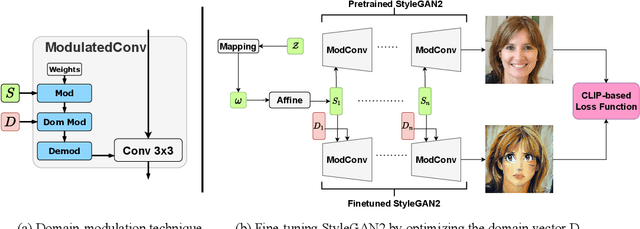
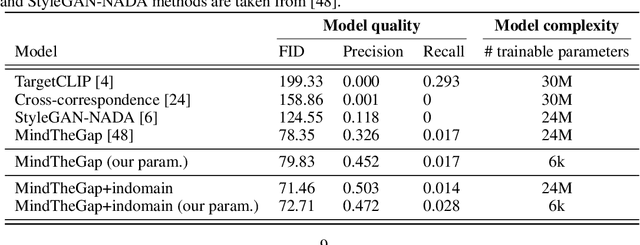
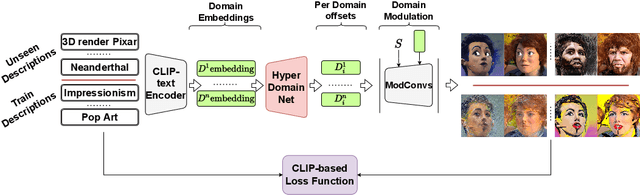
Domain adaptation framework of GANs has achieved great progress in recent years as a main successful approach of training contemporary GANs in the case of very limited training data. In this work, we significantly improve this framework by proposing an extremely compact parameter space for fine-tuning the generator. We introduce a novel domain-modulation technique that allows to optimize only 6 thousand-dimensional vector instead of 30 million weights of StyleGAN2 to adapt to a target domain. We apply this parameterization to the state-of-art domain adaptation methods and show that it has almost the same expressiveness as the full parameter space. Additionally, we propose a new regularization loss that considerably enhances the diversity of the fine-tuned generator. Inspired by the reduction in the size of the optimizing parameter space we consider the problem of multi-domain adaptation of GANs, i.e. setting when the same model can adapt to several domains depending on the input query. We propose the HyperDomainNet that is a hypernetwork that predicts our parameterization given the target domain. We empirically confirm that it can successfully learn a number of domains at once and may even generalize to unseen domains. Source code can be found at https://github.com/MACderRu/HyperDomainNet
Training Scale-Invariant Neural Networks on the Sphere Can Happen in Three Regimes
Sep 08, 2022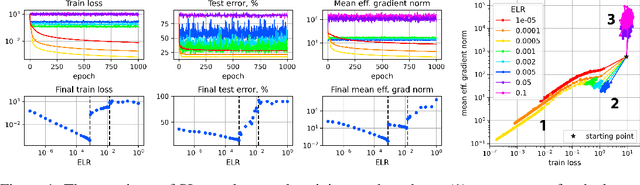

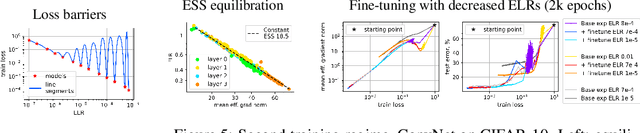

A fundamental property of deep learning normalization techniques, such as batch normalization, is making the pre-normalization parameters scale invariant. The intrinsic domain of such parameters is the unit sphere, and therefore their gradient optimization dynamics can be represented via spherical optimization with varying effective learning rate (ELR), which was studied previously. In this work, we investigate the properties of training scale-invariant neural networks directly on the sphere using a fixed ELR. We discover three regimes of such training depending on the ELR value: convergence, chaotic equilibrium, and divergence. We study these regimes in detail both on a theoretical examination of a toy example and on a thorough empirical analysis of real scale-invariant deep learning models. Each regime has unique features and reflects specific properties of the intrinsic loss landscape, some of which have strong parallels with previous research on both regular and scale-invariant neural networks training. Finally, we demonstrate how the discovered regimes are reflected in conventional training of normalized networks and how they can be leveraged to achieve better optima.
FFC-SE: Fast Fourier Convolution for Speech Enhancement
Apr 06, 2022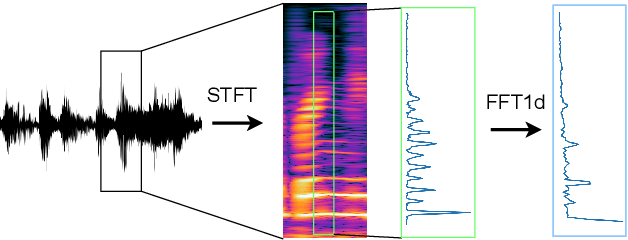
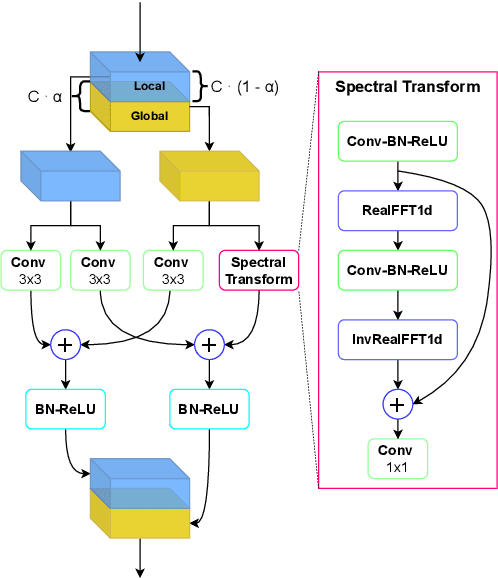
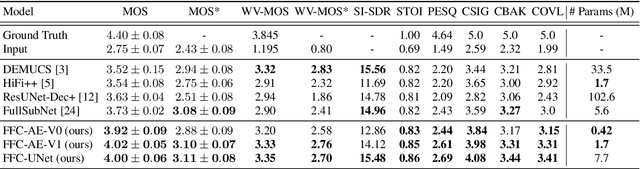
Fast Fourier convolution (FFC) is the recently proposed neural operator showing promising performance in several computer vision problems. The FFC operator allows employing large receptive field operations within early layers of the neural network. It was shown to be especially helpful for inpainting of periodic structures which are common in audio processing. In this work, we design neural network architectures which adapt FFC for speech enhancement. We hypothesize that a large receptive field allows these networks to produce more coherent phases than vanilla convolutional models, and validate this hypothesis experimentally. We found that neural networks based on Fast Fourier convolution outperform analogous convolutional models and show better or comparable results with other speech enhancement baselines.
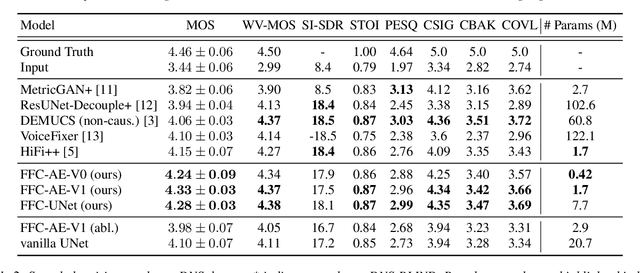
HiFi++: a Unified Framework for Neural Vocoding, Bandwidth Extension and Speech Enhancement
Mar 24, 2022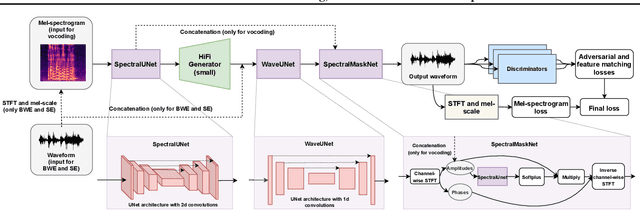
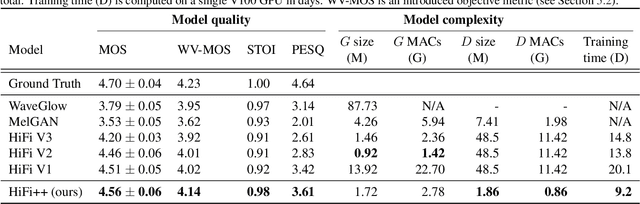
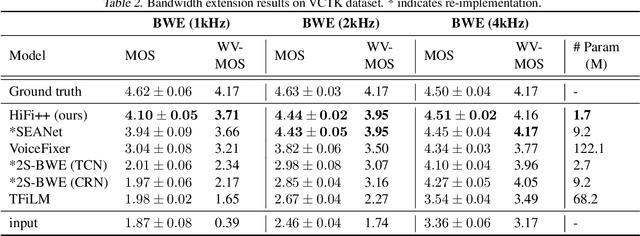
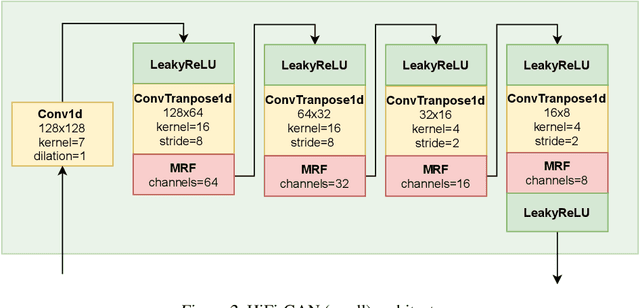
Generative adversarial networks have recently demonstrated outstanding performance in neural vocoding outperforming best autoregressive and flow-based models. In this paper, we show that this success can be extended to other tasks of conditional audio generation. In particular, building upon HiFi vocoders, we propose a novel HiFi++ general framework for neural vocoding, bandwidth extension, and speech enhancement. We show that with the improved generator architecture and simplified multi-discriminator training, HiFi++ performs on par with the state-of-the-art in these tasks while spending significantly less memory and computational resources. The effectiveness of our approach is validated through a series of extensive experiments.
Machine Learning Methods for Spectral Efficiency Prediction in Massive MIMO Systems
Dec 29, 2021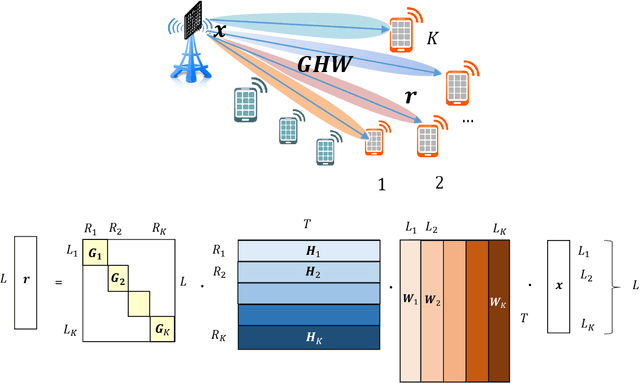

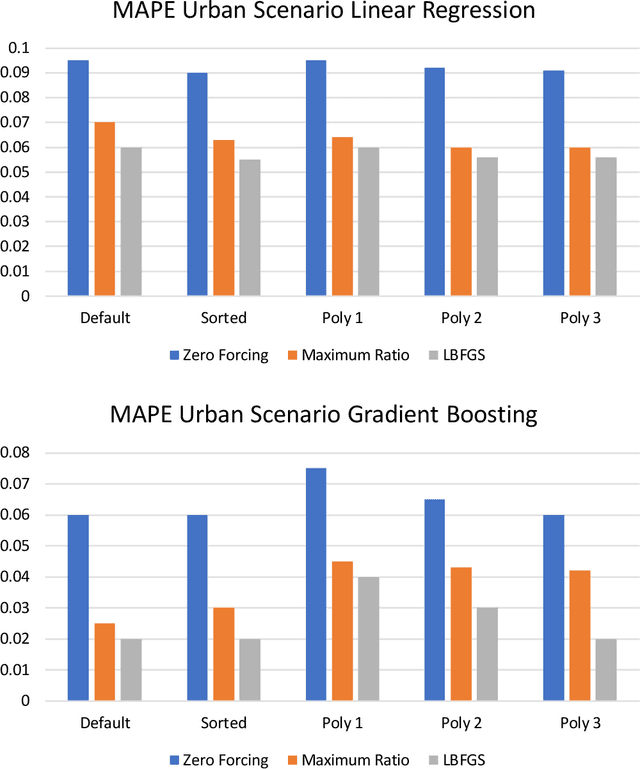
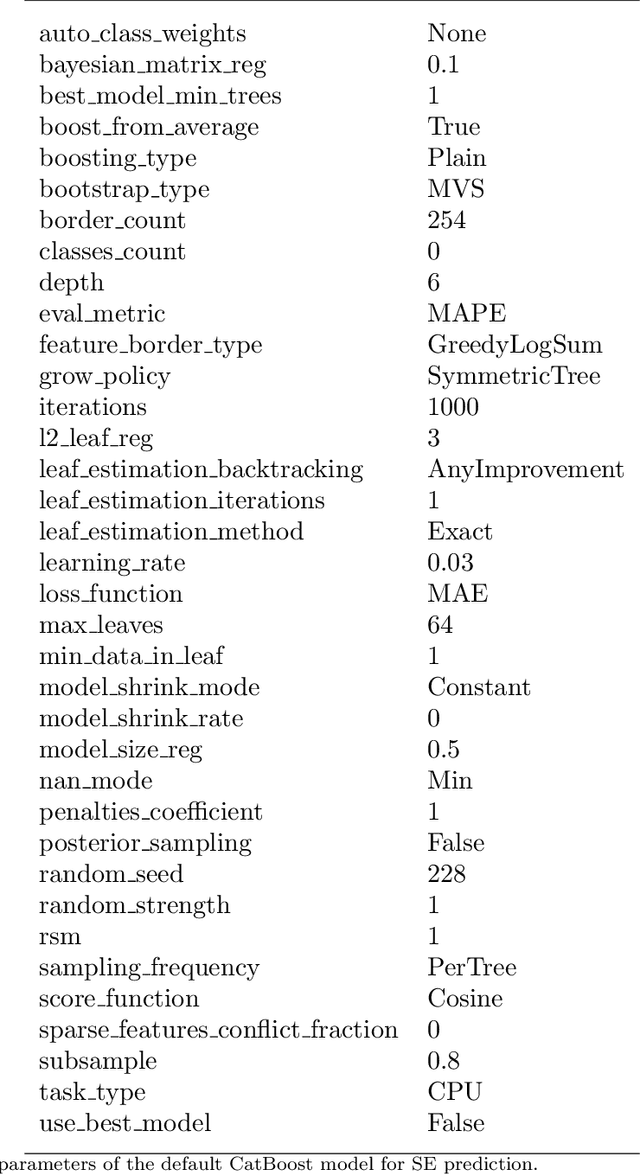
Channel decoding, channel detection, channel assessment, and resource management for wireless multiple-input multiple-output (MIMO) systems are all examples of problems where machine learning (ML) can be successfully applied. In this paper, we study several ML approaches to solve the problem of estimating the spectral efficiency (SE) value for a certain precoding scheme, preferably in the shortest possible time. The best results in terms of mean average percentage error (MAPE) are obtained with gradient boosting over sorted features, while linear models demonstrate worse prediction quality. Neural networks perform similarly to gradient boosting, but they are more resource- and time-consuming because of hyperparameter tuning and frequent retraining. We investigate the practical applicability of the proposed algorithms in a wide range of scenarios generated by the Quadriga simulator. In almost all scenarios, the MAPE achieved using gradient boosting and neural networks is less than 10\%.