 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Image Captioning via Generative Pretrained Transformers
Sep 28, 2022
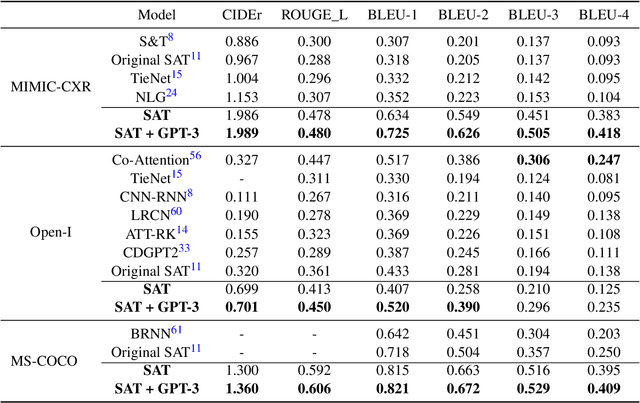
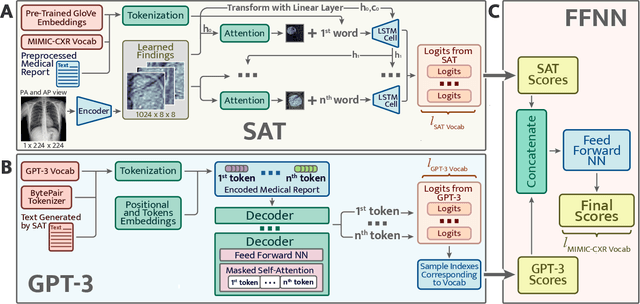
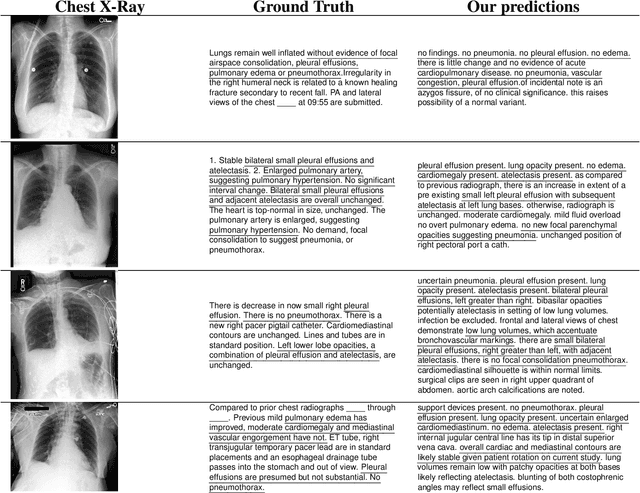
The automatic clinical caption generation problem is referred to as proposed model combining the analysis of frontal chest X-Ray scans with structured patient information from the radiology records. We combine two language models, the Show-Attend-Tell and the GPT-3, to generate comprehensive and descriptive radiology records. The proposed combination of these models generates a textual summary with the essential information about pathologies found, their location, and the 2D heatmaps localizing each pathology on the original X-Ray scans. The proposed model is tested on two medical datasets, the Open-I, MIMIC-CXR, and the general-purpose MS-COCO. The results measured with the natural language assessment metrics prove their efficient applicability to the chest X-Ray image captioning.
PyTorch Image Quality: Metrics for Image Quality Assessment
Aug 31, 2022
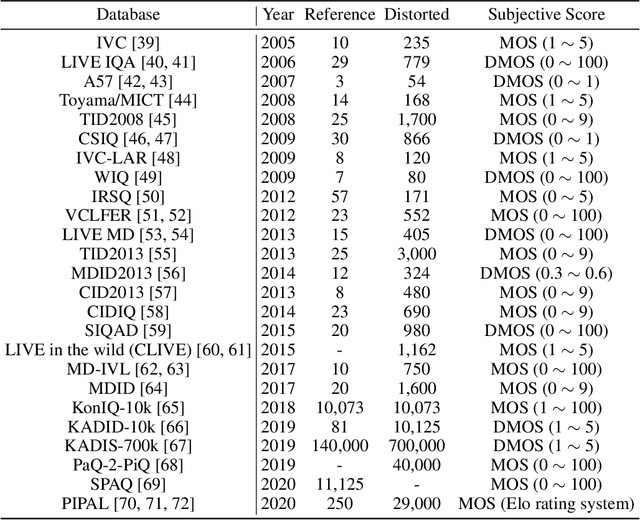
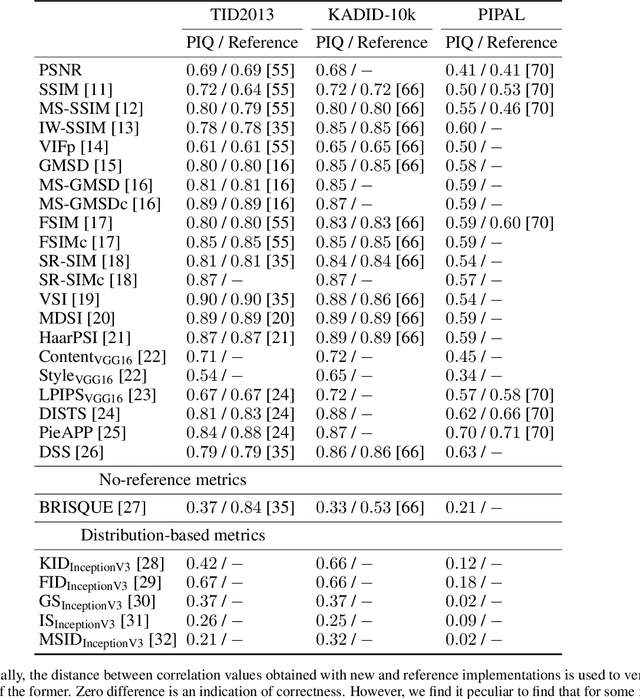
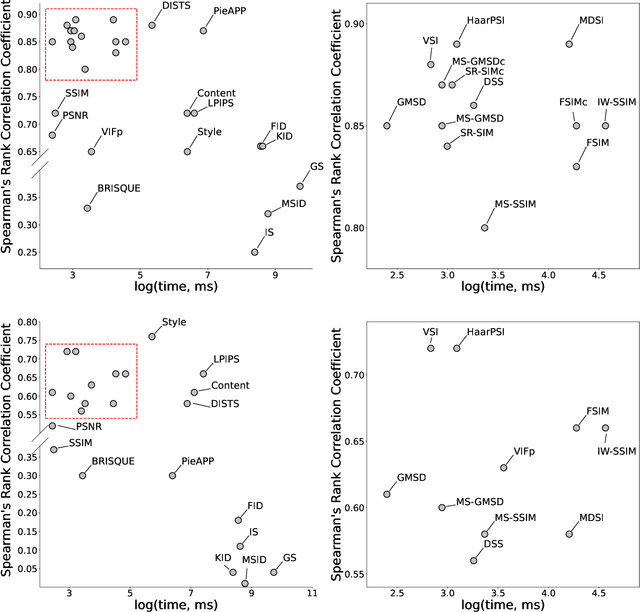
Image Quality Assessment (IQA) metrics are widely used to quantitatively estimate the extent of image degradation following some forming, restoring, transforming, or enhancing algorithms. We present PyTorch Image Quality (PIQ), a usability-centric library that contains the most popular modern IQA algorithms, guaranteed to be correctly implemented according to their original propositions and thoroughly verified. In this paper, we detail the principles behind the foundation of the library, describe the evaluation strategy that makes it reliable, provide the benchmarks that showcase the performance-time trade-offs, and underline the benefits of GPU acceleration given the library is used within the PyTorch backend. PyTorch Image Quality is an open source software: https://github.com/photosynthesis-team/piq/.
Feather-Light Fourier Domain Adaptation in Magnetic Resonance Imaging
Jul 31, 2022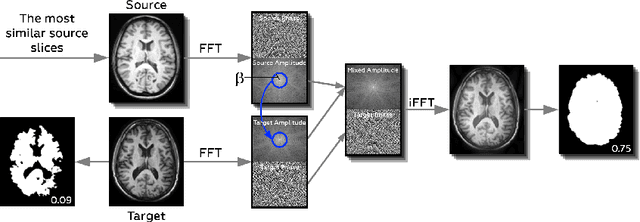

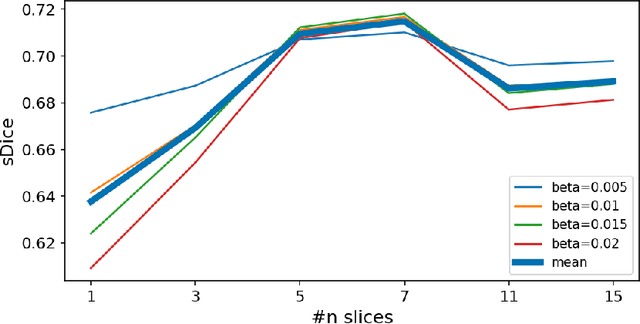
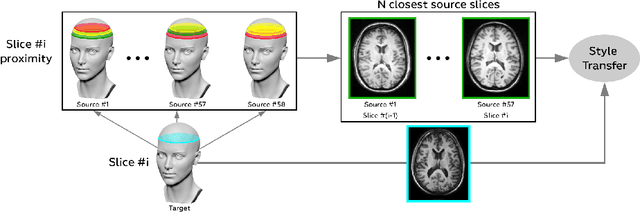
Generalizability of deep learning models may be severely affected by the difference in the distributions of the train (source domain) and the test (target domain) sets, e.g., when the sets are produced by different hardware. As a consequence of this domain shift, a certain model might perform well on data from one clinic, and then fail when deployed in another. We propose a very light and transparent approach to perform test-time domain adaptation. The idea is to substitute the target low-frequency Fourier space components that are deemed to reflect the style of an image. To maximize the performance, we implement the "optimal style donor" selection technique, and use a number of source data points for altering a single target scan appearance (Multi-Source Transferring). We study the effect of severity of domain shift on the performance of the method, and show that our training-free approach reaches the state-of-the-art level of complicated deep domain adaptation models. The code for our experiments is released.
Image Quality Assessment for Magnetic Resonance Imaging
Mar 15, 2022
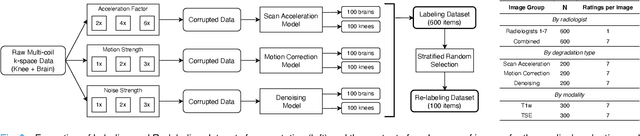
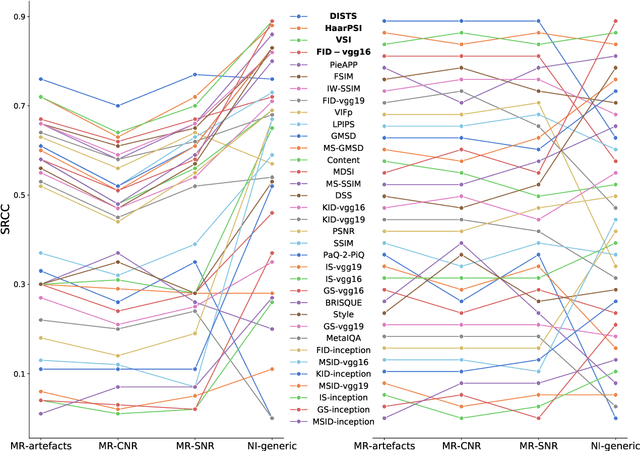
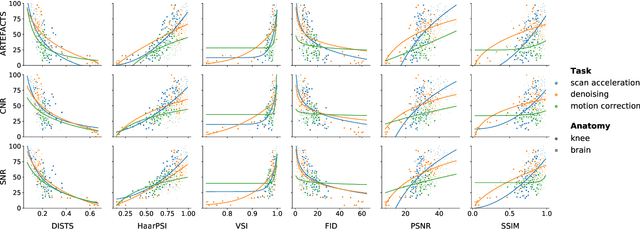
Image quality assessment (IQA) algorithms aim to reproduce the human's perception of the image quality. The growing popularity of image enhancement, generation, and recovery models instigated the development of many methods to assess their performance. However, most IQA solutions are designed to predict image quality in the general domain, with the applicability to specific areas, such as medical imaging, remaining questionable. Moreover, the selection of these IQA metrics for a specific task typically involves intentionally induced distortions, such as manually added noise or artificial blurring; yet, the chosen metrics are then used to judge the output of real-life computer vision models. In this work, we aspire to fill these gaps by carrying out the most extensive IQA evaluation study for Magnetic Resonance Imaging (MRI) to date (14,700 subjective scores). We use outputs of neural network models trained to solve problems relevant to MRI, including image reconstruction in the scan acceleration, motion correction, and denoising. Seven trained radiologists assess these distorted images, with their verdicts then correlated with 35 different image quality metrics (full-reference, no-reference, and distribution-based metrics considered). Our emphasis is on reflecting the radiologist's perception of the reconstructed images, gauging the most diagnostically influential criteria for the quality of MRI scans: signal-to-noise ratio, contrast-to-noise ratio, and the presence of artifacts.
Autofocusing+: Noise-Resilient Motion Correction in Magnetic Resonance Imaging
Mar 10, 2022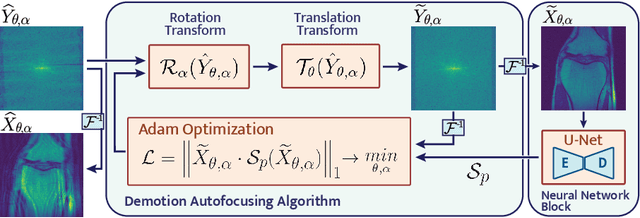
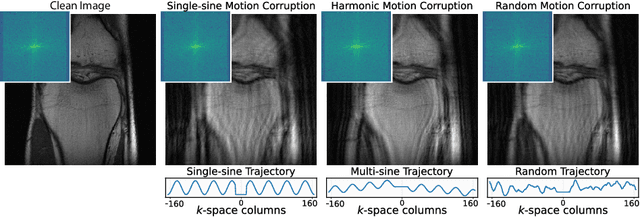
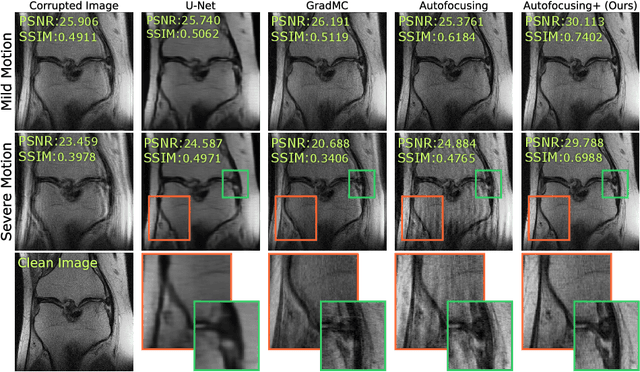
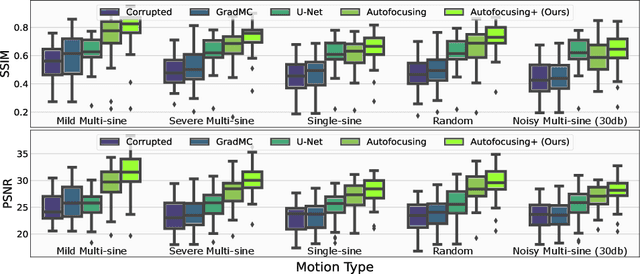
Image corruption by motion artifacts is an ingrained problem in Magnetic Resonance Imaging (MRI). In this work, we propose a neural network-based regularization term to enhance Autofocusing, a classic optimization-based method to remove motion artifacts. The method takes the best of both worlds: the optimization-based routine iteratively executes the blind demotion and deep learning-based prior penalizes for unrealistic restorations and speeds up the convergence. We validate the method on three models of motion trajectories, using synthetic and real noisy data. The method proves resilient to noise and anatomic structure variation, outperforming the state-of-the-art demotion methods.
Decentralized Autofocusing System with Hierarchical Agents
Aug 29, 2021

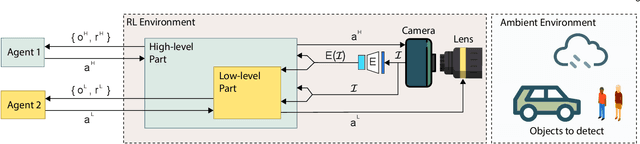
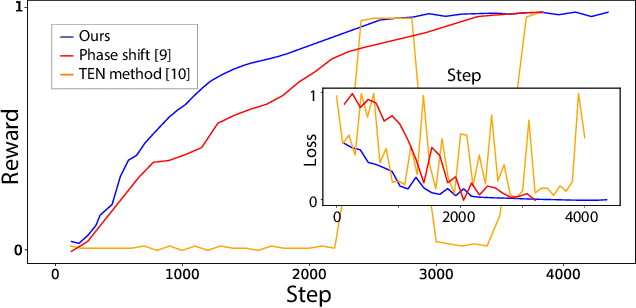
State-of-the-art object detection models are frequently trained offline using available datasets, such as ImageNet: large and overly diverse data that are unbalanced and hard to cluster semantically. This kind of training drops the object detection performance should the change in illumination, in the environmental conditions (e.g., rain), or in the lens positioning (out-of-focus blur) occur. We propose a decentralized hierarchical multi-agent deep reinforcement learning approach for intelligently controlling the camera and the lens focusing settings, leading to significant improvement to the capacity of the popular detection models (YOLO, Fast R-CNN, and Retina are considered). The algorithm relies on the latent representation of the camera's stream and, thus, it is the first method to allow a completely no-reference tuning of the camera, where the system trains itself to auto-focus itself.
Optimal MRI Undersampling Patterns for Ultimate Benefit of Medical Vision Tasks
Aug 10, 2021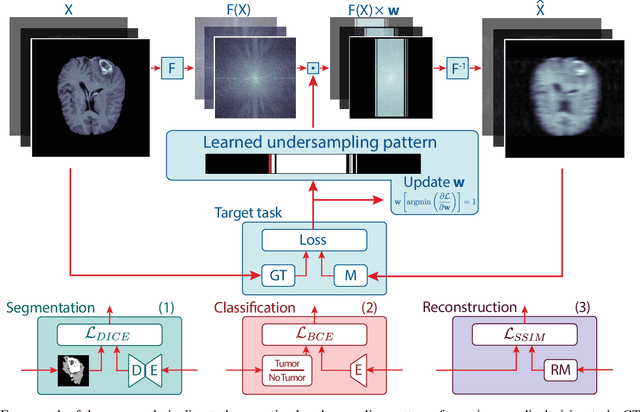
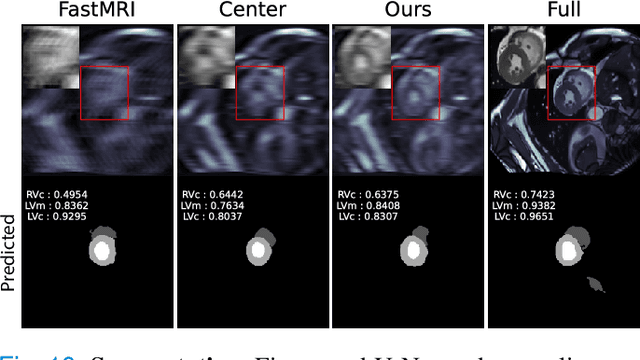
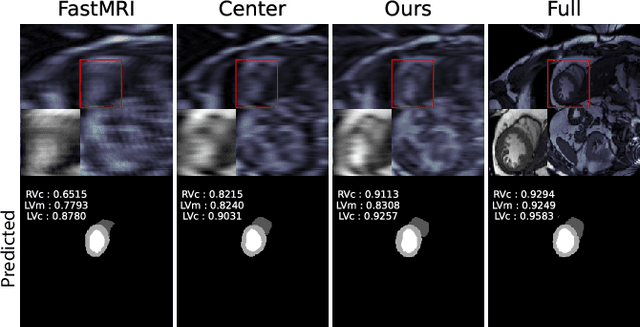
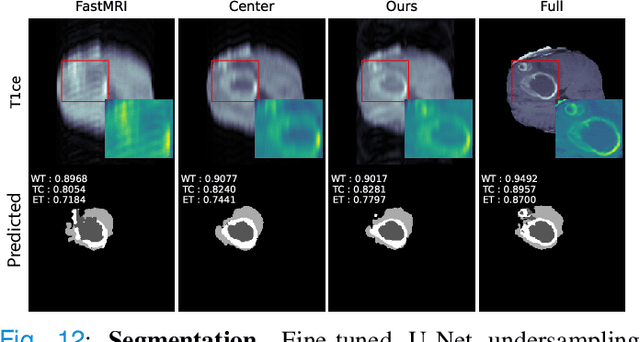
To accelerate MRI, the field of compressed sensing is traditionally concerned with optimizing the image quality after a partial undersampling of the measurable $\textit{k}$-space. In our work, we propose to change the focus from the quality of the reconstructed image to the quality of the downstream image analysis outcome. Specifically, we propose to optimize the patterns according to how well a sought-after pathology could be detected or localized in the reconstructed images. We find the optimal undersampling patterns in $\textit{k}$-space that maximize target value functions of interest in commonplace medical vision problems (reconstruction, segmentation, and classification) and propose a new iterative gradient sampling routine universally suitable for these tasks. We validate the proposed MRI acceleration paradigm on three classical medical datasets, demonstrating a noticeable improvement of the target metrics at the high acceleration factors (for the segmentation problem at $\times$16 acceleration, we report up to 12% improvement in Dice score over the other undersampling patterns).
Data Augmentation with Manifold Barycenters
Apr 02, 2021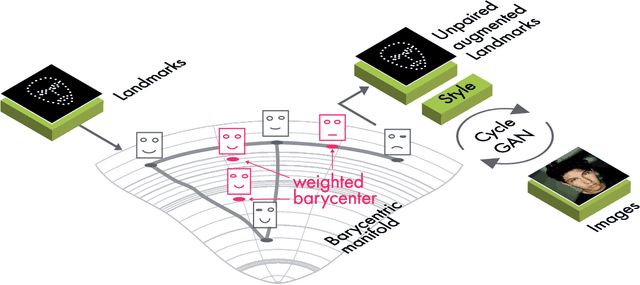


The training of Generative Adversarial Networks (GANs) requires a large amount of data, stimulating the development of new data augmentation methods to alleviate the challenge. Oftentimes, these methods either fail to produce enough new data or expand the dataset beyond the original knowledge domain. In this paper, we propose a new way of representing the available knowledge in the manifold of data barycenters. Such a representation allows performing data augmentation based on interpolation between the nearest data elements using Wasserstein distance. The proposed method finds cliques in the nearest-neighbors graph and, at each sampling iteration, randomly draws one clique to compute the Wasserstein barycenter with random uniform weights. These barycenters then become the new natural-looking elements that one could add to the dataset. We apply this approach to the problem of landmarks detection and augment the available landmarks data within the dataset. Additionally, the idea is validated on cardiac data for the task of medical segmentation. Our approach reduces the overfitting and improves the quality metrics both beyond the original data outcome and beyond the result obtained with classical augmentation methods.
Towards Ultrafast MRI via Extreme k-Space Undersampling and Superresolution
Mar 04, 2021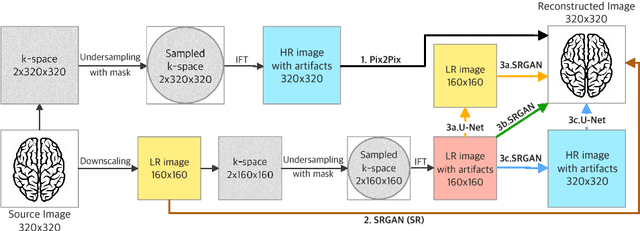
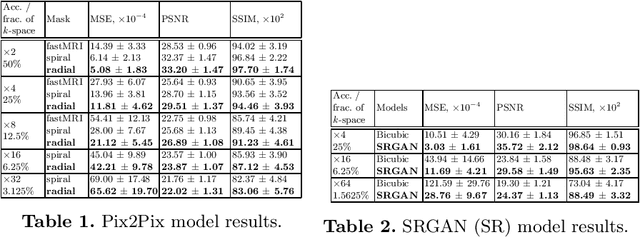
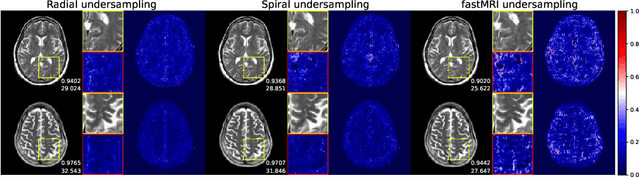
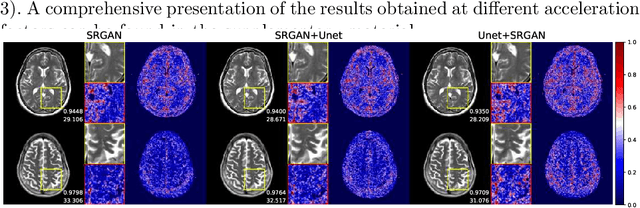
We went below the MRI acceleration factors (a.k.a., k-space undersampling) reported by all published papers that reference the original fastMRI challenge, and then considered powerful deep learning based image enhancement methods to compensate for the underresolved images. We thoroughly study the influence of the sampling patterns, the undersampling and the downscaling factors, as well as the recovery models on the final image quality for both the brain and the knee fastMRI benchmarks. The quality of the reconstructed images surpasses that of the other methods, yielding an MSE of 0.00114, a PSNR of 29.6 dB, and an SSIM of 0.956 at x16 acceleration factor. More extreme undersampling factors of x32 and x64 are also investigated, holding promise for certain clinical applications such as computer-assisted surgery or radiation planning. We survey 5 expert radiologists to assess 100 pairs of images and show that the recovered undersampled images statistically preserve their diagnostic value.
Active Learning for Sequence Tagging with Deep Pre-trained Models and Bayesian Uncertainty Estimates
Feb 18, 2021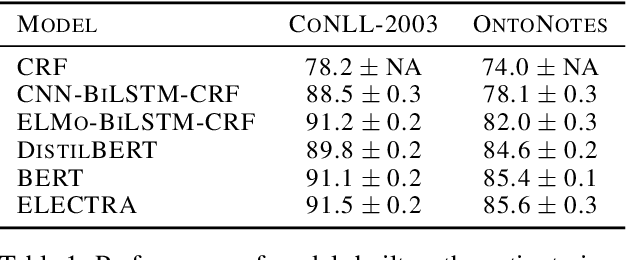
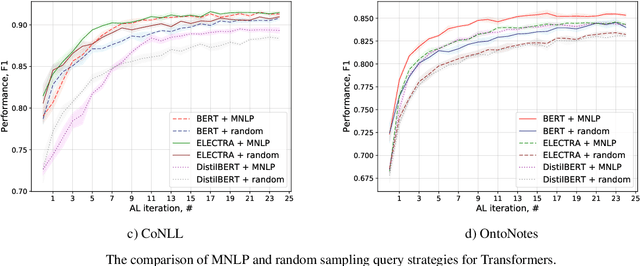
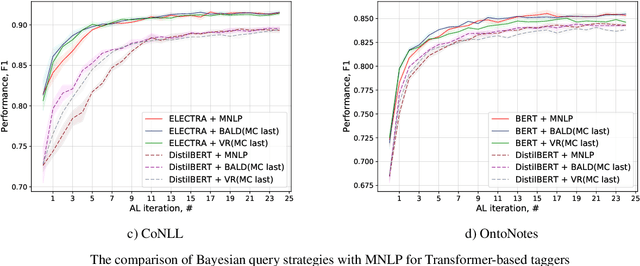
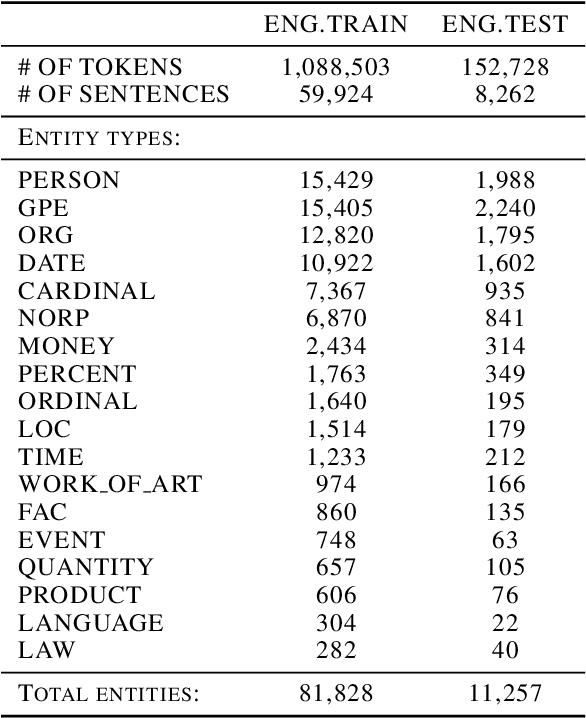
Annotating training data for sequence tagging of texts is usually very time-consuming. Recent advances in transfer learning for natural language processing in conjunction with active learning open the possibility to significantly reduce the necessary annotation budget. We are the first to thoroughly investigate this powerful combination for the sequence tagging task. We conduct an extensive empirical study of various Bayesian uncertainty estimation methods and Monte Carlo dropout options for deep pre-trained models in the active learning framework and find the best combinations for different types of models. Besides, we also demonstrate that to acquire instances during active learning, a full-size Transformer can be substituted with a distilled version, which yields better computational performance and reduces obstacles for applying deep active learning in practice.