 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Constant-Time Implementation Methodology for Activation Functions on Microcontrollers
May 21, 2026Embedded neural-network inference can leak information through timing side channels, including leakage caused by the evaluation of activation functions. This work proposes a constant-time implementation methodology for activation functions on embedded microcontrollers and validates it on ReLU, sigmoid, tanh, GELU, and Swish on an ARM Cortex-M4 platform. The proposed methodology combines branchless selection, fixed-cost Padé-based approximation, dummy arithmetic where needed, and cycle alignment to obtain timing-regular activation-function implementations. As motivation, we also evaluate a desynchronization-based countermeasure and show that it remains vulnerable to a template-based timing attack. Experimental results show that the resulting protected implementations achieve identical cycle counts for all tested inputs, including (88) cycles in the three-function setting and (108) cycles in the five-function setting. At the same time, the numerical-error analysis indicates that the approximated nonlinear functions retain high accuracy. These results suggest that the proposed methodology provides a practical basis for constructing side-channel-resistant activation functions in embedded inference.
Side-Channel Analysis of OpenVINO-based Neural Network Models
Jul 23, 2024


Embedded devices with neural network accelerators offer great versatility for their users, reducing the need to use cloud-based services. At the same time, they introduce new security challenges in the area of hardware attacks, the most prominent being side-channel analysis (SCA). It was shown that SCA can recover model parameters with a high accuracy, posing a threat to entities that wish to keep their models confidential. In this paper, we explore the susceptibility of quantized models implemented in OpenVINO, an embedded framework for deploying neural networks on embedded and Edge devices. We show that it is possible to recover model parameters with high precision, allowing the recovered model to perform very close to the original one. Our experiments on GoogleNet v1 show only a 1% difference in the Top 1 and a 0.64% difference in the Top 5 accuracies.
A Desynchronization-Based Countermeasure Against Side-Channel Analysis of Neural Networks
Mar 25, 2023



Model extraction attacks have been widely applied, which can normally be used to recover confidential parameters of neural networks for multiple layers. Recently, side-channel analysis of neural networks allows parameter extraction even for networks with several multiple deep layers with high effectiveness. It is therefore of interest to implement a certain level of protection against these attacks. In this paper, we propose a desynchronization-based countermeasure that makes the timing analysis of activation functions harder. We analyze the timing properties of several activation functions and design the desynchronization in a way that the dependency on the input and the activation type is hidden. We experimentally verify the effectiveness of the countermeasure on a 32-bit ARM Cortex-M4 microcontroller and employ a t-test to show the side-channel information leakage. The overhead ultimately depends on the number of neurons in the fully-connected layer, for example, in the case of 4096 neurons in VGG-19, the overheads are between 2.8% and 11%.
SNIFF: Reverse Engineering of Neural Networks with Fault Attacks
Feb 23, 2020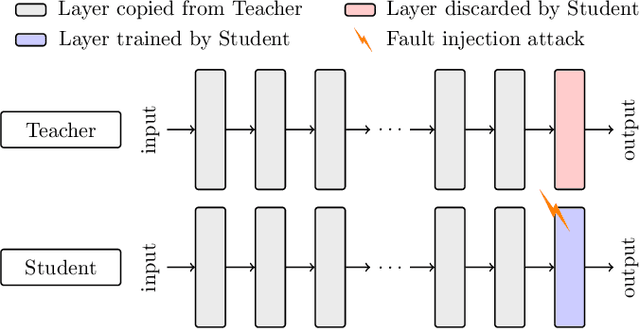
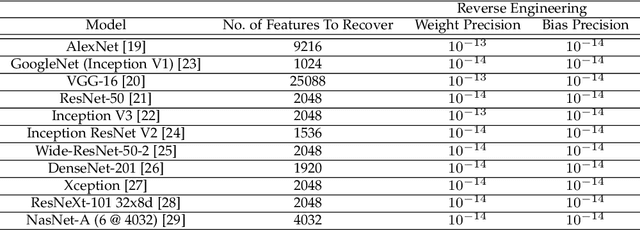

Neural networks have been shown to be vulnerable against fault injection attacks. These attacks change the physical behavior of the device during the computation, resulting in a change of value that is currently being computed. They can be realized by various fault injection techniques, ranging from clock/voltage glitching to application of lasers to rowhammer. In this paper we explore the possibility to reverse engineer neural networks with the usage of fault attacks. SNIFF stands for sign bit flip fault, which enables the reverse engineering by changing the sign of intermediate values. We develop the first exact extraction method on deep-layer feature extractor networks that provably allows the recovery of the model parameters. Our experiments with Keras library show that the precision error for the parameter recovery for the tested networks is less than $10^{-13}$ with the usage of 64-bit floats, which improves the current state of the art by 6 orders of magnitude. Additionally, we discuss the protection techniques against fault injection attacks that can be applied to enhance the fault resistance.
Enhancing Fault Tolerance of Neural Networks for Security-Critical Applications
Feb 05, 2019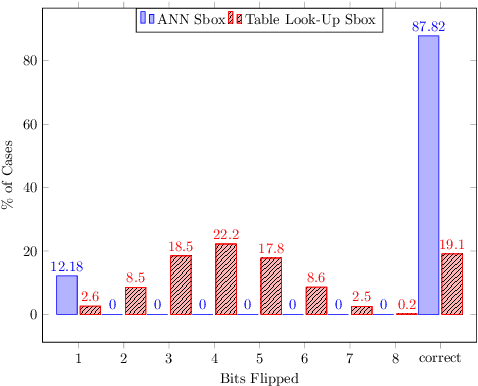

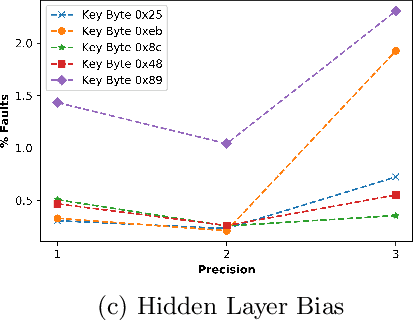
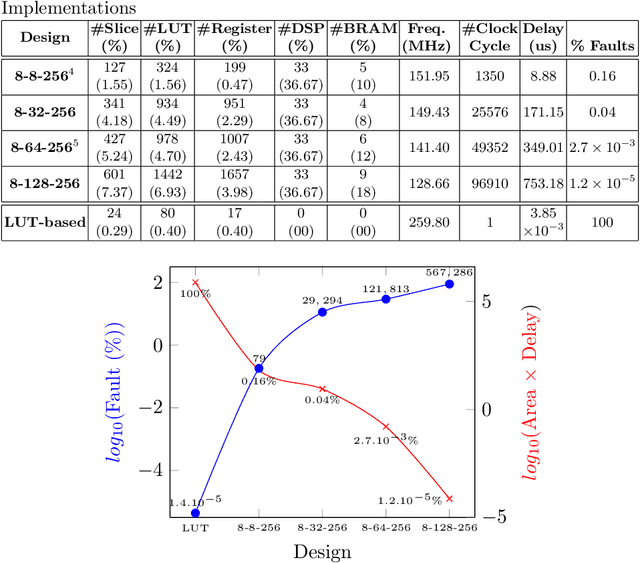
Neural Networks (NN) have recently emerged as backbone of several sensitive applications like automobile, medical image, security, etc. NNs inherently offer Partial Fault Tolerance (PFT) in their architecture; however, the biased PFT of NNs can lead to severe consequences in applications like cryptography and security critical scenarios. In this paper, we propose a revised implementation which enhances the PFT property of NN significantly with detailed mathematical analysis. We evaluated the performance of revised NN considering both software and FPGA implementation for a cryptographic primitive like AES SBox. The results show that the PFT of NNs can be significantly increased with the proposed methodology.
DeepLaser: Practical Fault Attack on Deep Neural Networks
Sep 29, 2018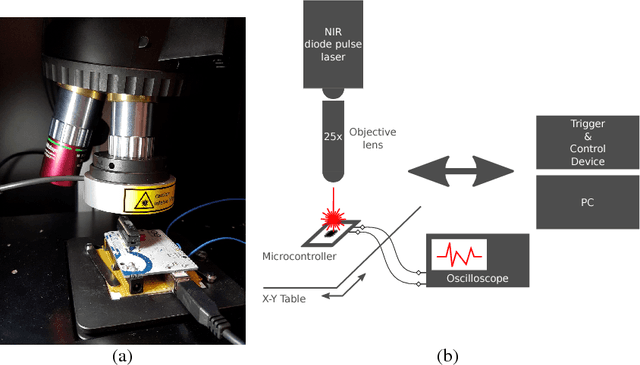
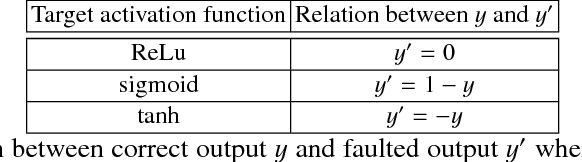
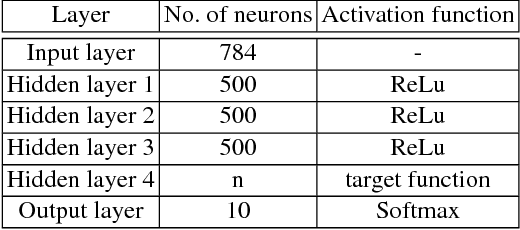
As deep learning systems are widely adopted in safety- and security-critical applications, such as autonomous vehicles, banking systems, etc., malicious faults and attacks become a tremendous concern, which potentially could lead to catastrophic consequences. In this paper, we initiate the first study of leveraging physical fault injection attacks on Deep Neural Networks (DNNs), by using laser injection technique on embedded systems. In particular, our exploratory study targets four widely used activation functions in DNNs development, that are the general main building block of DNNs that creates non-linear behaviors -- ReLu, softmax, sigmoid, and tanh. Our results show that by targeting these functions, it is possible to achieve a misclassification by injecting faults into the hidden layer of the network. Such result can have practical implications for real-world applications, where faults can be introduced by simpler means (such as altering the supply voltage).