 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Domain-Specific Features to Enhance Domain Generalization
Oct 18, 2021
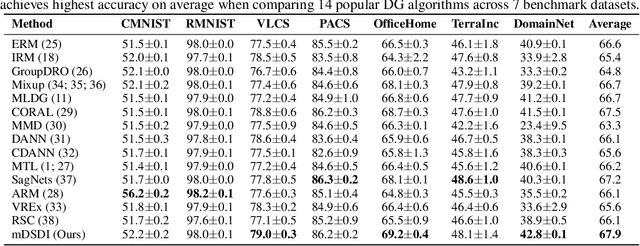

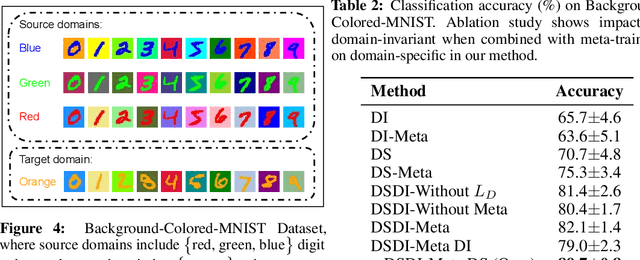
Domain Generalization (DG) aims to train a model, from multiple observed source domains, in order to perform well on unseen target domains. To obtain the generalization capability, prior DG approaches have focused on extracting domain-invariant information across sources to generalize on target domains, while useful domain-specific information which strongly correlates with labels in individual domains and the generalization to target domains is usually ignored. In this paper, we propose meta-Domain Specific-Domain Invariant (mDSDI) - a novel theoretically sound framework that extends beyond the invariance view to further capture the usefulness of domain-specific information. Our key insight is to disentangle features in the latent space while jointly learning both domain-invariant and domain-specific features in a unified framework. The domain-specific representation is optimized through the meta-learning framework to adapt from source domains, targeting a robust generalization on unseen domains. We empirically show that mDSDI provides competitive results with state-of-the-art techniques in DG. A further ablation study with our generated dataset, Background-Colored-MNIST, confirms the hypothesis that domain-specific is essential, leading to better results when compared with only using domain-invariant.
ReGVD: Revisiting Graph Neural Networks for Vulnerability Detection
Oct 14, 2021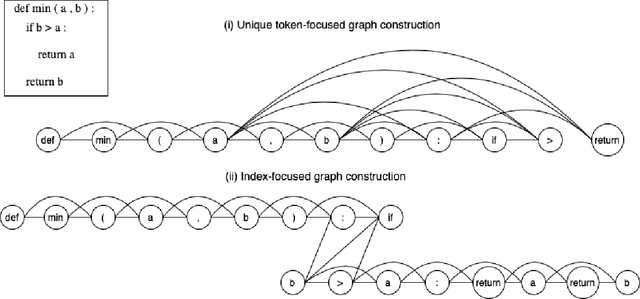
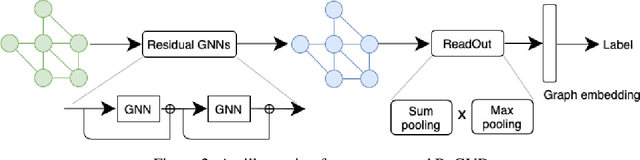
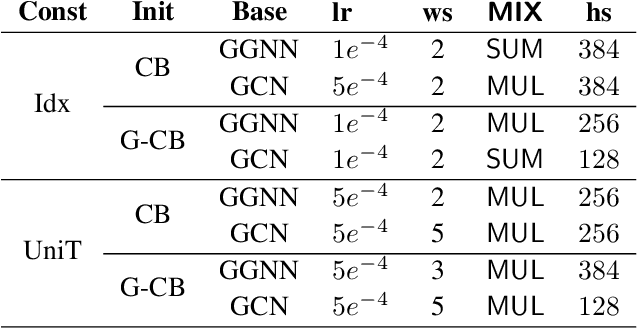
Identifying vulnerabilities in the source code is essential to protect the software systems from cyber security attacks. It, however, is also a challenging step that requires specialized expertise in security and code representation. Inspired by the successful applications of pre-trained programming language (PL) models such as CodeBERT and graph neural networks (GNNs), we propose ReGVD, a general and novel graph neural network-based model for vulnerability detection. In particular, ReGVD views a given source code as a flat sequence of tokens and then examines two effective methods of utilizing unique tokens and indexes respectively to construct a single graph as an input, wherein node features are initialized only by the embedding layer of a pre-trained PL model. Next, ReGVD leverages a practical advantage of residual connection among GNN layers and explores a beneficial mixture of graph-level sum and max poolings to return a graph embedding for the given source code. Experimental results demonstrate that ReGVD outperforms the existing state-of-the-art models and obtain the highest accuracy on the real-world benchmark dataset from CodeXGLUE for vulnerability detection.
Generalised Unsupervised Domain Adaptation of Neural Machine Translation with Cross-Lingual Data Selection
Sep 09, 2021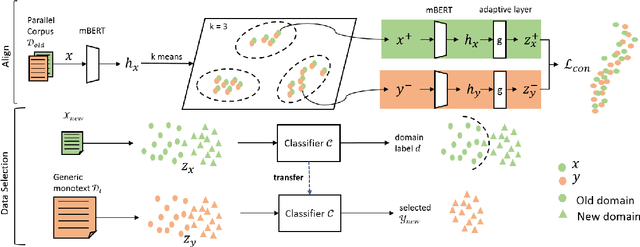
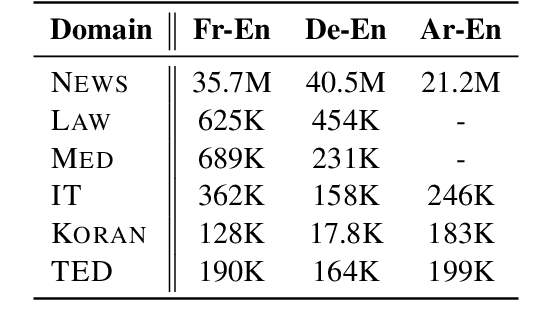
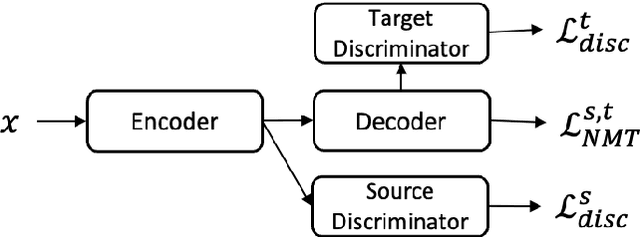
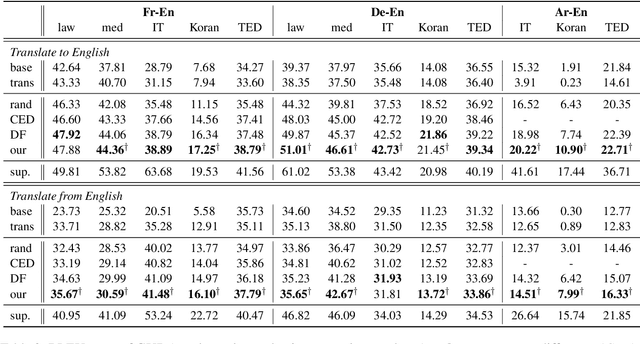
This paper considers the unsupervised domain adaptation problem for neural machine translation (NMT), where we assume the access to only monolingual text in either the source or target language in the new domain. We propose a cross-lingual data selection method to extract in-domain sentences in the missing language side from a large generic monolingual corpus. Our proposed method trains an adaptive layer on top of multilingual BERT by contrastive learning to align the representation between the source and target language. This then enables the transferability of the domain classifier between the languages in a zero-shot manner. Once the in-domain data is detected by the classifier, the NMT model is then adapted to the new domain by jointly learning translation and domain discrimination tasks. We evaluate our cross-lingual data selection method on NMT across five diverse domains in three language pairs, as well as a real-world scenario of translation for COVID-19. The results show that our proposed method outperforms other selection baselines up to +1.5 BLEU score.
Elastic Architecture Search for Diverse Tasks with Different Resources
Aug 03, 2021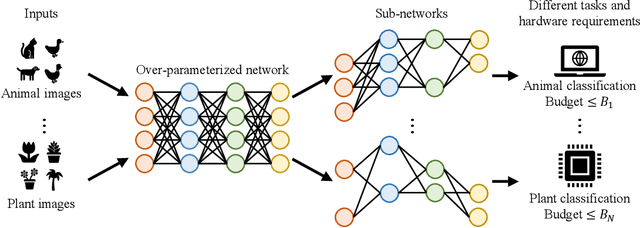
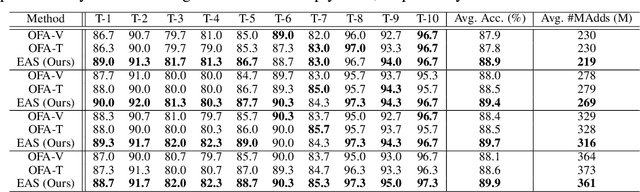
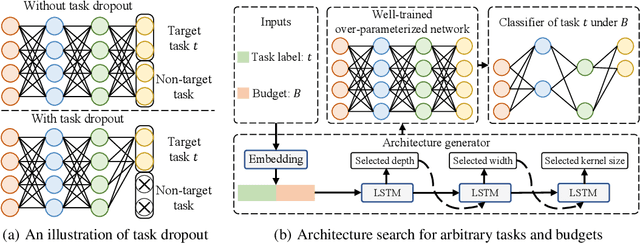
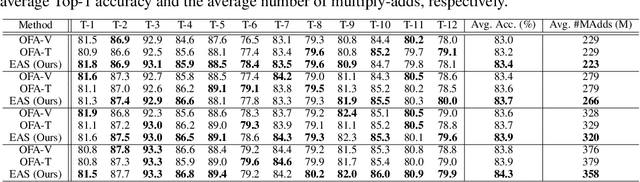
We study a new challenging problem of efficient deployment for diverse tasks with different resources, where the resource constraint and task of interest corresponding to a group of classes are dynamically specified at testing time. Previous NAS approaches seek to design architectures for all classes simultaneously, which may not be optimal for some individual tasks. A straightforward solution is to search an architecture from scratch for each deployment scenario, which however is computation-intensive and impractical. To address this, we present a novel and general framework, called Elastic Architecture Search (EAS), permitting instant specializations at runtime for diverse tasks with various resource constraints. To this end, we first propose to effectively train the over-parameterized network via a task dropout strategy to disentangle the tasks during training. In this way, the resulting model is robust to the subsequent task dropping at inference time. Based on the well-trained over-parameterized network, we then propose an efficient architecture generator to obtain optimal architectures within a single forward pass. Experiments on two image classification datasets show that EAS is able to find more compact networks with better performance while remarkably being orders of magnitude faster than state-of-the-art NAS methods. For example, our proposed EAS finds compact architectures within 0.1 second for 50 deployment scenarios.
Multi-Label Image Classification with Contrastive Learning
Jul 24, 2021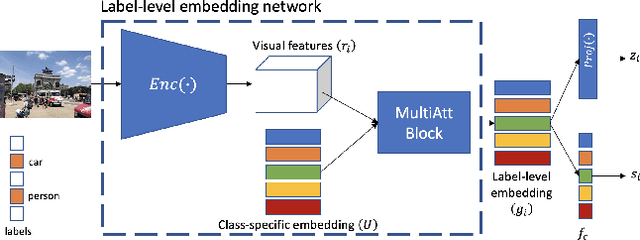
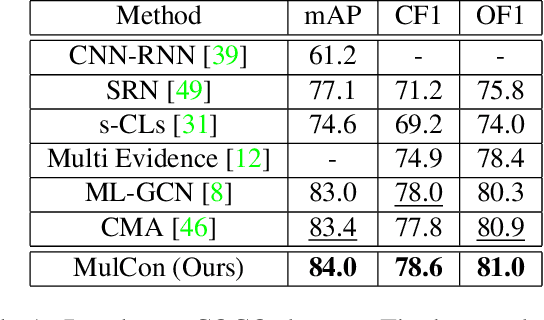
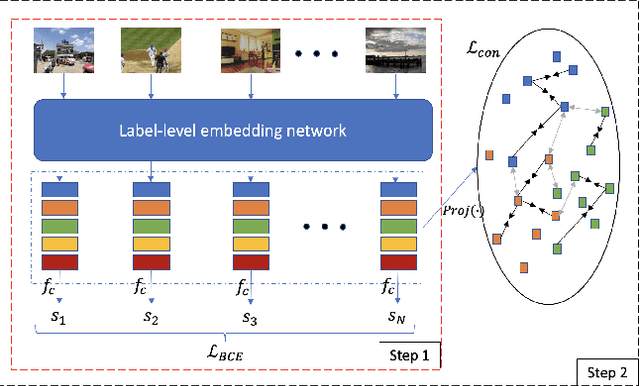
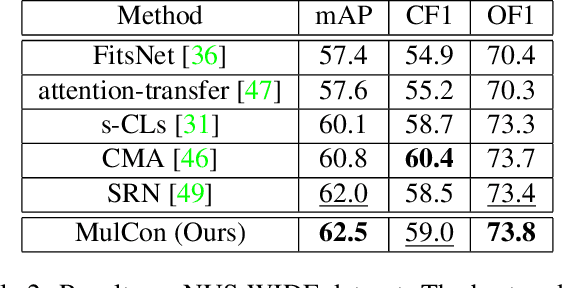
Recently, as an effective way of learning latent representations, contrastive learning has been increasingly popular and successful in various domains. The success of constrastive learning in single-label classifications motivates us to leverage this learning framework to enhance distinctiveness for better performance in multi-label image classification. In this paper, we show that a direct application of contrastive learning can hardly improve in multi-label cases. Accordingly, we propose a novel framework for multi-label classification with contrastive learning in a fully supervised setting, which learns multiple representations of an image under the context of different labels. This facilities a simple yet intuitive adaption of contrastive learning into our model to boost its performance in multi-label image classification. Extensive experiments on two benchmark datasets show that the proposed framework achieves state-of-the-art performance in the comparison with the advanced methods in multi-label classification.
Improved and Efficient Text Adversarial Attacks using Target Information
May 02, 2021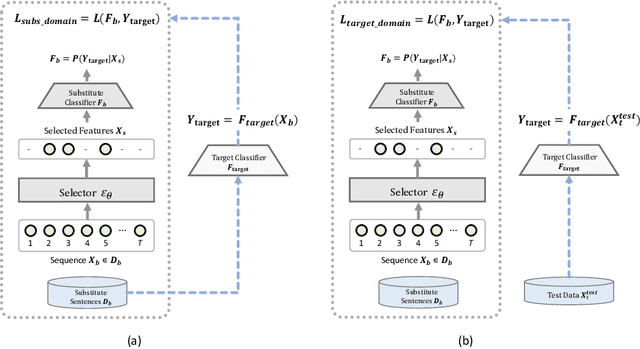
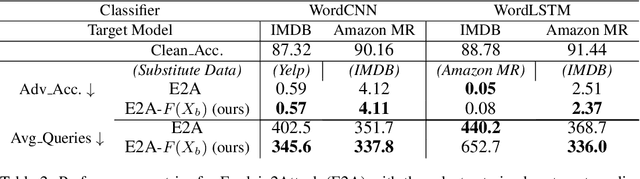
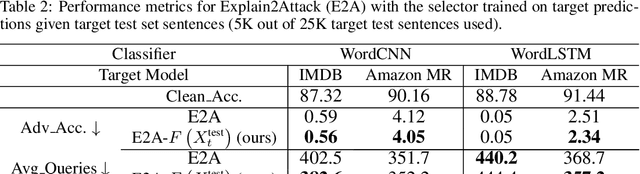
There has been recently a growing interest in studying adversarial examples on natural language models in the black-box setting. These methods attack natural language classifiers by perturbing certain important words until the classifier label is changed. In order to find these important words, these methods rank all words by importance by querying the target model word by word for each input sentence, resulting in high query inefficiency. A new interesting approach was introduced that addresses this problem through interpretable learning to learn the word ranking instead of previous expensive search. The main advantage of using this approach is that it achieves comparable attack rates to the state-of-the-art methods, yet faster and with fewer queries, where fewer queries are desirable to avoid suspicion towards the attacking agent. Nonetheless, this approach sacrificed the useful information that could be leveraged from the target classifier for that sake of query efficiency. In this paper we study the effect of leveraging the target model outputs and data on both attack rates and average number of queries, and we show that both can be improved, with a limited overhead of additional queries.
Text Generation with Deep Variational GAN
Apr 27, 2021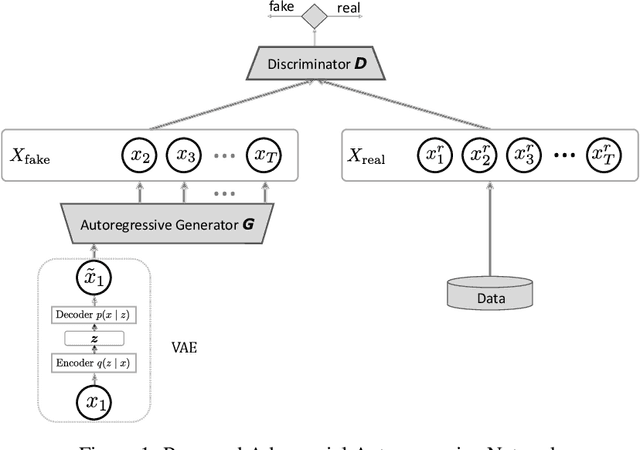


Generating realistic sequences is a central task in many machine learning applications. There has been considerable recent progress on building deep generative models for sequence generation tasks. However, the issue of mode-collapsing remains a main issue for the current models. In this paper we propose a GAN-based generic framework to address the problem of mode-collapse in a principled approach. We change the standard GAN objective to maximize a variational lower-bound of the log-likelihood while minimizing the Jensen-Shanon divergence between data and model distributions. We experiment our model with text generation task and show that it can generate realistic text with high diversity.
Node Co-occurrence based Graph Neural Networks for Knowledge Graph Link Prediction
Apr 15, 2021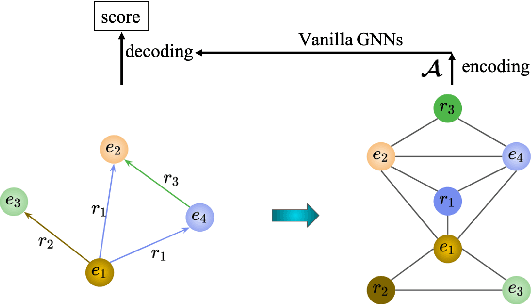
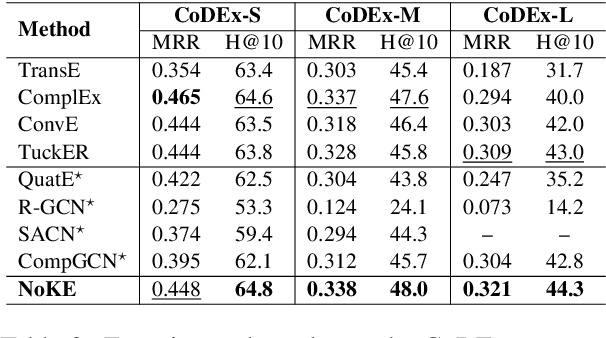
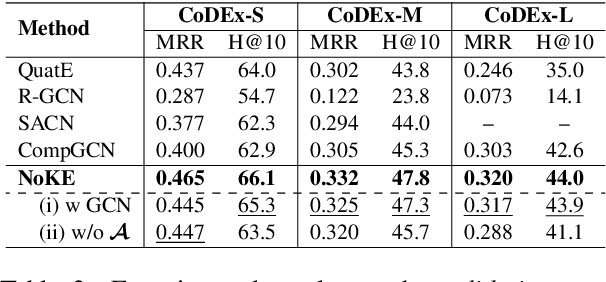
We introduce a novel embedding model, named NoKE, which aims to integrate co-occurrence among entities and relations into graph neural networks to improve knowledge graph completion (i.e., link prediction). Given a knowledge graph, NoKE constructs a single graph considering entities and relations as individual nodes. NoKE then computes weights for edges among nodes based on the co-occurrence of entities and relations. Next, NoKE utilizes vanilla GNNs to update vector representations for entity and relation nodes and then adopts a score function to produce the triple scores. Comprehensive experimental results show that our NoKE obtains state-of-the-art results on three new, challenging, and difficult benchmark datasets CoDEx for knowledge graph completion, demonstrating the power of its simplicity and effectiveness.
Topic Modelling Meets Deep Neural Networks: A Survey
Feb 28, 2021
Topic modelling has been a successful technique for text analysis for almost twenty years. When topic modelling met deep neural networks, there emerged a new and increasingly popular research area, neural topic models, with over a hundred models developed and a wide range of applications in neural language understanding such as text generation, summarisation and language models. There is a need to summarise research developments and discuss open problems and future directions. In this paper, we provide a focused yet comprehensive overview of neural topic models for interested researchers in the AI community, so as to facilitate them to navigate and innovate in this fast-growing research area. To the best of our knowledge, ours is the first review focusing on this specific topic.
BoMb-OT: On Batch of Mini-batches Optimal Transport
Feb 11, 2021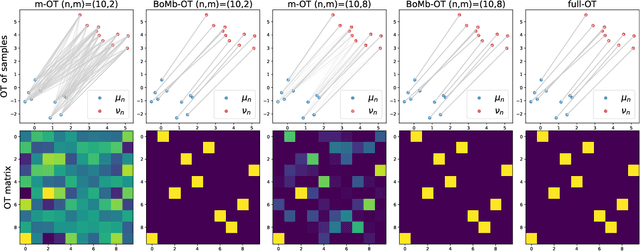
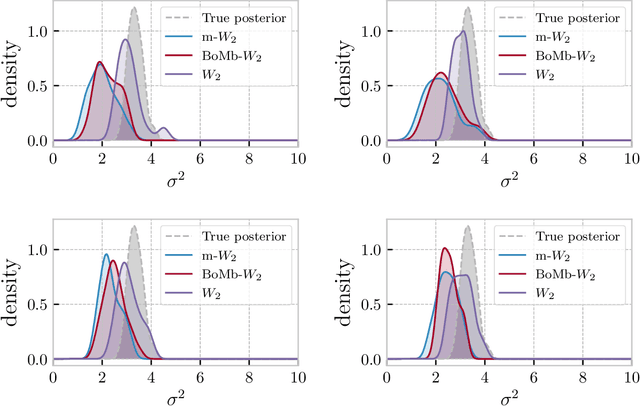


Mini-batch optimal transport (m-OT) has been successfully used in practical applications that involve probability measures with intractable density, or probability measures with a very high number of supports. The m-OT solves several sparser optimal transport problems and then returns the average of their costs and transportation plans. Despite its scalability advantage, m-OT is not a proper metric between probability measures since it does not satisfy the identity property. To address this problem, we propose a novel mini-batching scheme for optimal transport, named Batch of Mini-batches Optimal Transport (BoMb-OT), that can be formulated as a well-defined distance on the space of probability measures. Furthermore, we show that the m-OT is a limit of the entropic regularized version of the proposed BoMb-OT when the regularized parameter goes to infinity. We carry out extensive experiments to show that the new mini-batching scheme can estimate a better transportation plan between two original measures than m-OT. It leads to a favorable performance of BoMb-OT in the matching and color transfer tasks. Furthermore, we observe that BoMb-OT also provides a better objective loss than m-OT for doing approximate Bayesian computation, estimating parameters of interest in parametric generative models, and learning non-parametric generative models with gradient flow.