 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtomVLA: Scalable Post-Training for Robotic Manipulation via Predictive Latent World Models
Mar 09, 2026Vision-Language-Action (VLA) models demonstrate remarkable potential for generalizable robotic manipulation. The execution of complex multi-step behaviors in VLA models can be improved by robust instruction grounding, a critical component for effective control. However, current paradigms predominantly rely on coarse, high-level task instructions during supervised fine-tuning. This instruction grounding gap leaves models without explicit intermediate guidance, leading to severe compounding errors in long-horizon tasks. Therefore, bridging this instruction gap and providing scalable post-training for VLA models is urgent. To tackle this problem, we propose \method, the first subtask-aware VLA framework integrated with a scalable offline post-training pipeline. Our framework leverages a large language model to decompose high-level demonstrations into fine-grained atomic subtasks. This approach utilizes a pretrained predictive world model to score candidate action chunks against subtask goals in the latent space, mitigating error accumulation while significantly improving long-horizon robustness. Furthermore, this approach enables highly efficient Group Relative Policy Optimization without the prohibitive expenses associated with online rollouts on physical robots. Extensive simulations validate that our AtomVLA maintains strong robustness under perturbations. When evaluated against fundamental baseline models, it achieves an average success rate of 97.0\% on the LIBERO benchmark and 48.0\% on the LIBERO-PRO benchmark. Finally, experiments conducted in the real world using the Galaxea R1 Lite platform confirm its broad applicability across diverse tasks, especially long-horizon tasks. All datasets, checkpoints, and code will be released to the public domain following the acceptance of this work for future research.
Calibration of the internal and external parameters of wheeled robot mobile chasses and inertial measurement units based on nonlinear optimization
May 17, 2020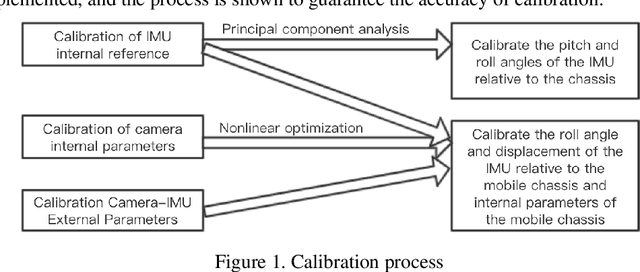
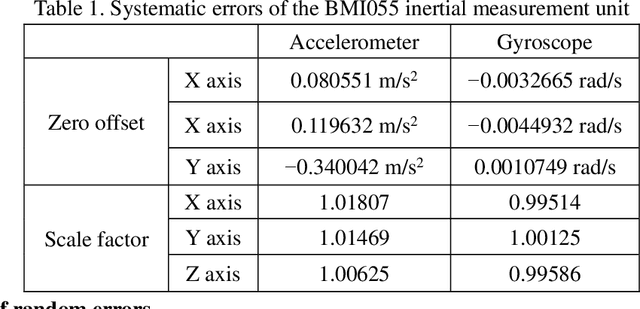
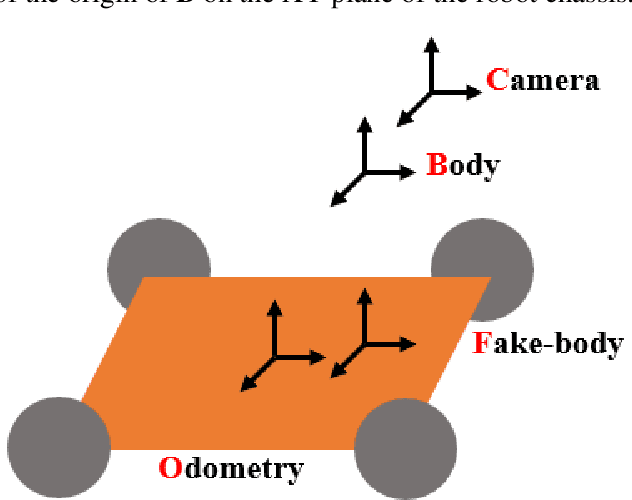
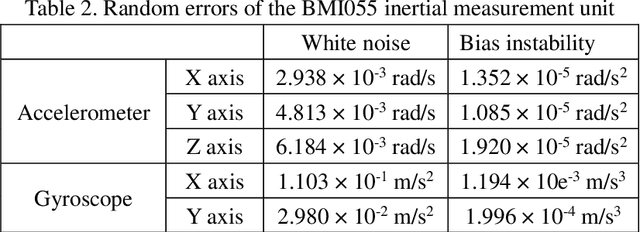
Mobile robot positioning, mapping, and navigation systems generally employ an inertial measurement unit (IMU) to obtain the acceleration and angular velocity of the robot. However, errors in the internal and external parameters of an IMU arising from defective calibration directly affect the accuracy of robot positioning and pose estimation. While this issue has been addressed by the mature internal reference calibration methods available for IMUs, external reference calibration methods between the IMU and the chassis of a mobile robot are lacking. This study addresses this issue by proposing a novel chassis-IMU internal and external parameter calibration algorithm based on nonlinear optimization, which is designed for robots equipped with cameras, IMUs, and wheel speed odometers, and functions under the premise of accurate calibrations for the internal parameters of the IMU and the internal and external parameters of the camera. All of the internal and external reference calibrations are conducted using the robot's existing equipment without the need for additional calibration aids. The feasibility of the method is verified by its application to a Mecanum wheel omnidirectional mobile platform as an example, as well as suitable for other type chassis of mobile robots. The proposed calibration method is thereby demonstrated to guarantee the accuracy of robot pose estimation.