 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Sensor Fusion for UAV Classification Based on Feature Maps of Image and Radar Data
Oct 21, 2024



The unique cost, flexibility, speed, and efficiency of modern UAVs make them an attractive choice in many applications in contemporary society. This, however, causes an ever-increasing number of reported malicious or accidental incidents, rendering the need for the development of UAV detection and classification mechanisms essential. We propose a methodology for developing a system that fuses already processed multi-sensor data into a new Deep Neural Network to increase its classification accuracy towards UAV detection. The DNN model fuses high-level features extracted from individual object detection and classification models associated with thermal, optronic, and radar data. Additionally, emphasis is given to the model's Convolutional Neural Network (CNN) based architecture that combines the features of the three sensor modalities by stacking the extracted image features of the thermal and optronic sensor achieving higher classification accuracy than each sensor alone.
SMOF: Streaming Modern CNNs on FPGAs with Smart Off-Chip Eviction
Mar 27, 2024



Convolutional Neural Networks (CNNs) have demonstrated their effectiveness in numerous vision tasks. However, their high processing requirements necessitate efficient hardware acceleration to meet the application's performance targets. In the space of FPGAs, streaming-based dataflow architectures are often adopted by users, as significant performance gains can be achieved through layer-wise pipelining and reduced off-chip memory access by retaining data on-chip. However, modern topologies, such as the UNet, YOLO, and X3D models, utilise long skip connections, requiring significant on-chip storage and thus limiting the performance achieved by such system architectures. The paper addresses the above limitation by introducing weight and activation eviction mechanisms to off-chip memory along the computational pipeline, taking into account the available compute and memory resources. The proposed mechanism is incorporated into an existing toolflow, expanding the design space by utilising off-chip memory as a buffer. This enables the mapping of such modern CNNs to devices with limited on-chip memory, under the streaming architecture design approach. SMOF has demonstrated the capacity to deliver competitive and, in some cases, state-of-the-art performance across a spectrum of computer vision tasks, achieving up to 10.65 X throughput improvement compared to previous works.
From Detection to Action Recognition: An Edge-Based Pipeline for Robot Human Perception
Dec 06, 2023



Mobile service robots are proving to be increasingly effective in a range of applications, such as healthcare, monitoring Activities of Daily Living (ADL), and facilitating Ambient Assisted Living (AAL). These robots heavily rely on Human Action Recognition (HAR) to interpret human actions and intentions. However, for HAR to function effectively on service robots, it requires prior knowledge of human presence (human detection) and identification of individuals to monitor (human tracking). In this work, we propose an end-to-end pipeline that encompasses the entire process, starting from human detection and tracking, leading to action recognition. The pipeline is designed to operate in near real-time while ensuring all stages of processing are performed on the edge, reducing the need for centralised computation. To identify the most suitable models for our mobile robot, we conducted a series of experiments comparing state-of-the-art solutions based on both their detection performance and efficiency. To evaluate the effectiveness of our proposed pipeline, we proposed a dataset comprising daily household activities. By presenting our findings and analysing the results, we demonstrate the efficacy of our approach in enabling mobile robots to understand and respond to human behaviour in real-world scenarios relying mainly on the data from their RGB cameras.
fpgaHART: A toolflow for throughput-oriented acceleration of 3D CNNs for HAR onto FPGAs
May 31, 2023



Surveillance systems, autonomous vehicles, human monitoring systems, and video retrieval are just few of the many applications in which 3D Convolutional Neural Networks are exploited. However, their extensive use is restricted by their high computational and memory requirements, especially when integrated into systems with limited resources. This study proposes a toolflow that optimises the mapping of 3D CNN models for Human Action Recognition onto FPGA devices, taking into account FPGA resources and off-chip memory characteristics. The proposed system employs Synchronous Dataflow (SDF) graphs to model the designs and introduces transformations to expand and explore the design space, resulting in high-throughput designs. A variety of 3D CNN models were evaluated using the proposed toolflow on multiple FPGA devices, demonstrating its potential to deliver competitive performance compared to earlier hand-tuned and model-specific designs.
FMM-X3D: FPGA-based modeling and mapping of X3D for Human Action Recognition
May 29, 2023



3D Convolutional Neural Networks are gaining increasing attention from researchers and practitioners and have found applications in many domains, such as surveillance systems, autonomous vehicles, human monitoring systems, and video retrieval. However, their widespread adoption is hindered by their high computational and memory requirements, especially when resource-constrained systems are targeted. This paper addresses the problem of mapping X3D, a state-of-the-art model in Human Action Recognition that achieves accuracy of 95.5\% in the UCF101 benchmark, onto any FPGA device. The proposed toolflow generates an optimised stream-based hardware system, taking into account the available resources and off-chip memory characteristics of the FPGA device. The generated designs push further the current performance-accuracy pareto front, and enable for the first time the targeting of such complex model architectures for the Human Action Recognition task.
HARFLOW3D: A Latency-Oriented 3D-CNN Accelerator Toolflow for HAR on FPGA Devices
Apr 11, 2023



For Human Action Recognition tasks (HAR), 3D Convolutional Neural Networks have proven to be highly effective, achieving state-of-the-art results. This study introduces a novel streaming architecture based toolflow for mapping such models onto FPGAs considering the model's inherent characteristics and the features of the targeted FPGA device. The HARFLOW3D toolflow takes as input a 3D CNN in ONNX format and a description of the FPGA characteristics, generating a design that minimizes the latency of the computation. The toolflow is comprised of a number of parts, including i) a 3D CNN parser, ii) a performance and resource model, iii) a scheduling algorithm for executing 3D models on the generated hardware, iv) a resource-aware optimization engine tailored for 3D models, v) an automated mapping to synthesizable code for FPGAs. The ability of the toolflow to support a broad range of models and devices is shown through a number of experiments on various 3D CNN and FPGA system pairs. Furthermore, the toolflow has produced high-performing results for 3D CNN models that have not been mapped to FPGAs before, demonstrating the potential of FPGA-based systems in this space. Overall, HARFLOW3D has demonstrated its ability to deliver competitive latency compared to a range of state-of-the-art hand-tuned approaches being able to achieve up to 5$\times$ better performance compared to some of the existing works.
Open Challenges in Synthetic Speech Detection
Sep 15, 2022
In this paper the current status and open challenges of synthetic speech detection are addressed. The work comprises an initial analysis of available open datasets and of existing detection methods, a description of the requirements for new research datasets compliant with regulations and better representing real-case scenarios, and a discussion of the desired characteristics of future trustworthy detection methods in terms of both functional and non-functional requirements. Compared to other works, based on specific detection solutions or presenting single dataset of synthetic speeches, our paper is meant to orient future state-of-the-art research in the domain, to quickly lessen the current gap between synthesis and detection approaches.
A Survey of Robotic Harvesting Systems and Enabling Technologies
Jul 22, 2022
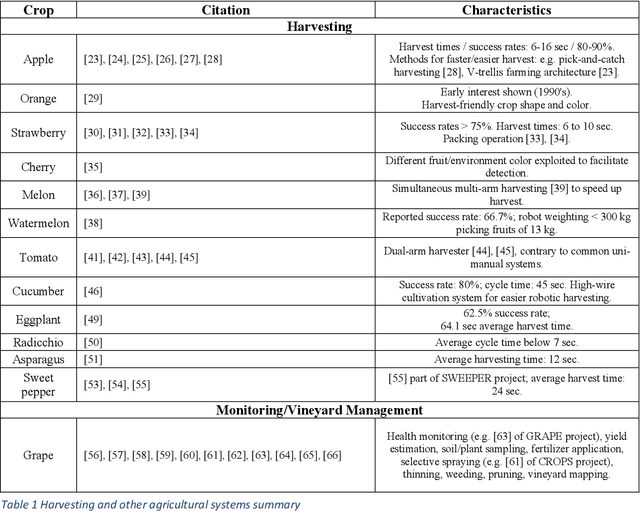

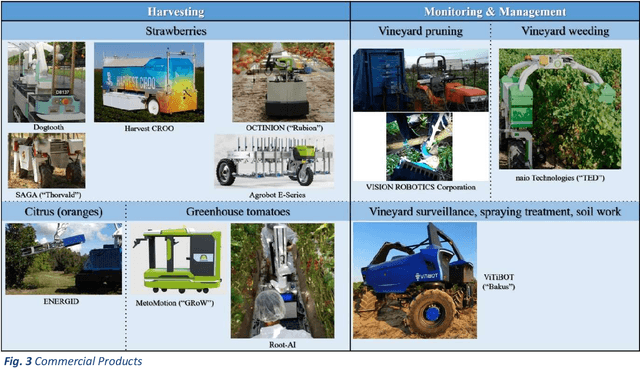
This paper presents a comprehensive review of ground agricultural robotic systems and applications with special focus on harvesting that span research and commercial products and results, as well as their enabling technologies. The majority of literature concerns the development of crop detection, field navigation via vision and their related challenges. Health monitoring, yield estimation, water status inspection, seed planting and weed removal are frequently encountered tasks. Regarding robotic harvesting, apples, strawberries, tomatoes and sweet peppers are mainly the crops considered in publications, research projects and commercial products. The reported harvesting agricultural robotic solutions, typically consist of a mobile platform, a single robotic arm/manipulator and various navigation/vision systems. This paper reviews reported development of specific functionalities and hardware, typically required by an operating agricultural robot harvester; they include (a) vision systems, (b) motion planning/navigation methodologies (for the robotic platform and/or arm), (c) Human-Robot-Interaction (HRI) strategies with 3D visualization, (d) system operation planning & grasping strategies and (e) robotic end-effector/gripper design. Clearly, automated agriculture and specifically autonomous harvesting via robotic systems is a research area that remains wide open, offering several challenges where new contributions can be made.
A Deep Learning Framework for Simulation and Defect Prediction Applied in Microelectronics
Feb 25, 2020

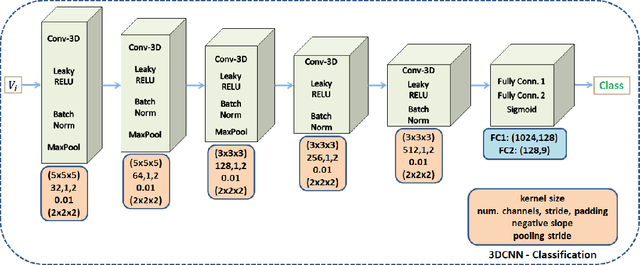
The prediction of upcoming events in industrial processes has been a long-standing research goal since it enables optimization of manufacturing parameters, planning of equipment maintenance and more importantly prediction and eventually prevention of defects. While existing approaches have accomplished substantial progress, they are mostly limited to processing of one dimensional signals or require parameter tuning to model environmental parameters. In this paper, we propose an alternative approach based on deep neural networks that simulates changes in the 3D structure of a monitored object in a batch based on previous 3D measurements. In particular, we propose an architecture based on 3D Convolutional Neural Networks (3DCNN) in order to model the geometric variations in manufacturing parameters and predict upcoming events related to sub-optimal performance. We validate our framework on a microelectronics use-case using the recently published PCB scans dataset where we simulate changes on the shape and volume of glue deposited on an Liquid Crystal Polymer (LCP) substrate before the attachment of integrated circuits (IC). Experimental evaluation examines the impact of different choices in the cost function during training and shows that the proposed method can be efficiently used for defect prediction.
* 21 pages, 5 figures
Fault Diagnosis in Microelectronics Attachment via Deep Learning Analysis of 3D Laser Scans
Feb 25, 2020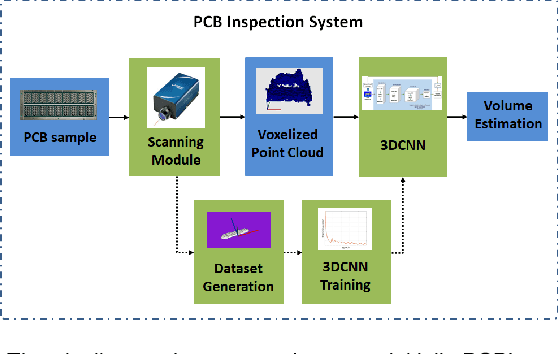
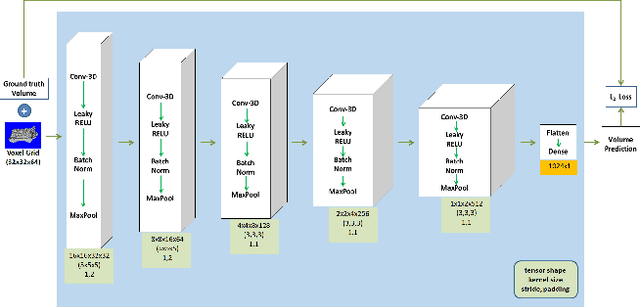
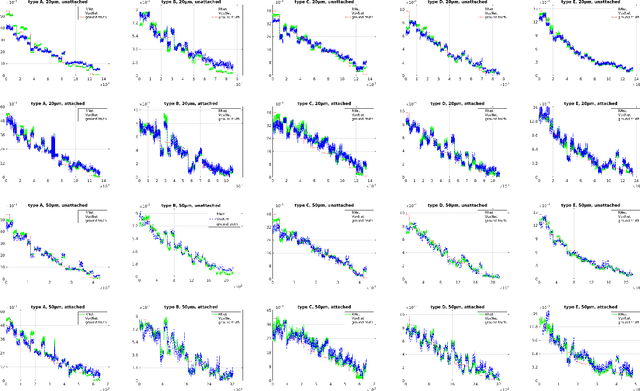

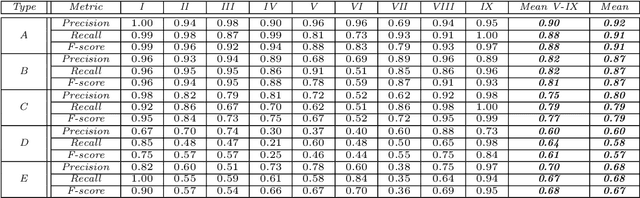
A common source of defects in manufacturing miniature Printed Circuits Boards (PCB) is the attachment of silicon die or other wire bondable components on a Liquid Crystal Polymer (LCP) substrate. Typically, a conductive glue is dispensed prior to attachment with defects caused either by insufficient or excessive glue. The current practice in electronics industry is to examine the deposited glue by a human operator a process that is both time consuming and inefficient especially in preproduction runs where the error rate is high. In this paper we propose a system that automates fault diagnosis by accurately estimating the volume of glue deposits before and even after die attachment. To this end a modular scanning system is deployed that produces high resolution point clouds whereas the actual estimation of glue volume is performed by (R)egression-Net (RNet), a 3D Convolutional Neural Network (3DCNN). RNet outperforms other deep architectures and is able to estimate the volume either directly from the point cloud of a glue deposit or more interestingly after die attachment when only a small part of glue is visible around each die. The entire methodology is evaluated under operational conditions where the proposed system achieves accurate results without delaying the manufacturing process.