 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Prediction Length for Time Series with Sequence to Sequence Networks
Jul 02, 2018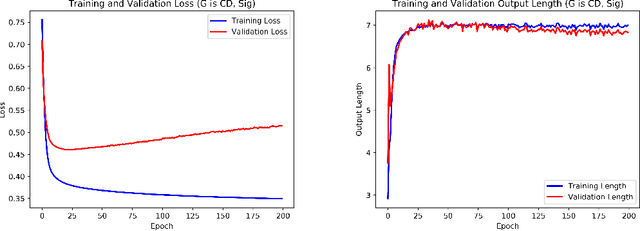
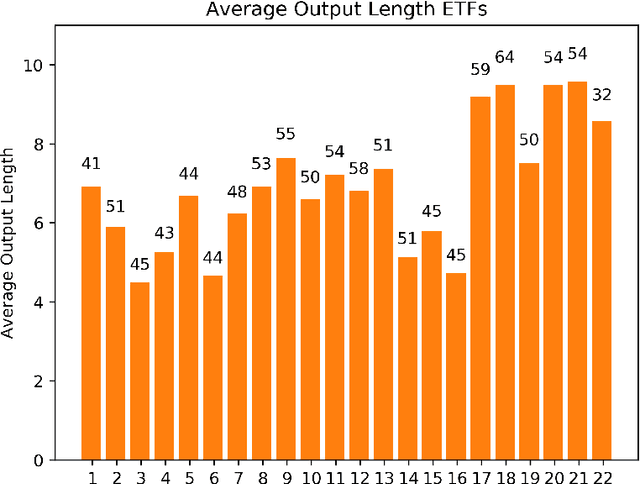
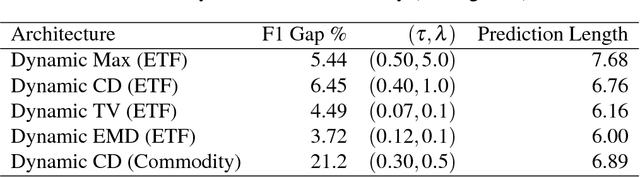
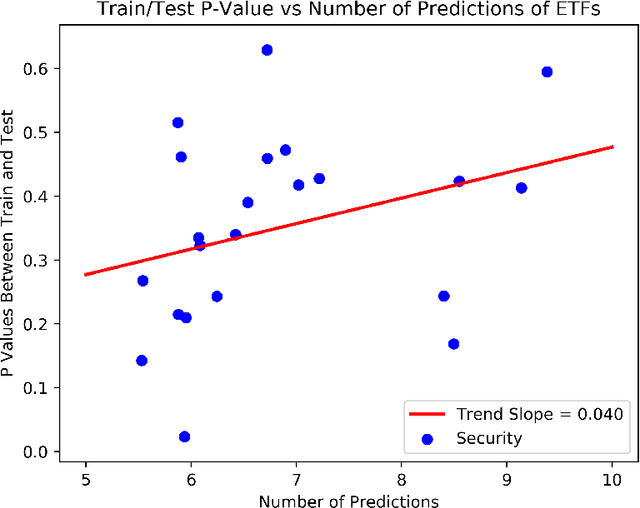
Recurrent neural networks and sequence to sequence models require a predetermined length for prediction output length. Our model addresses this by allowing the network to predict a variable length output in inference. A new loss function with a tailored gradient computation is developed that trades off prediction accuracy and output length. The model utilizes a function to determine whether a particular output at a time should be evaluated or not given a predetermined threshold. We evaluate the model on the problem of predicting the prices of securities. We find that the model makes longer predictions for more stable securities and it naturally balances prediction accuracy and length.
Online Adaptive Machine Learning Based Algorithm for Implied Volatility Surface Modeling
Jun 07, 2018
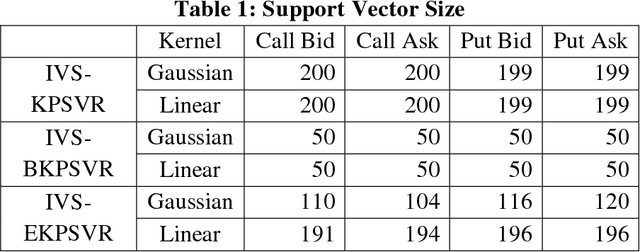
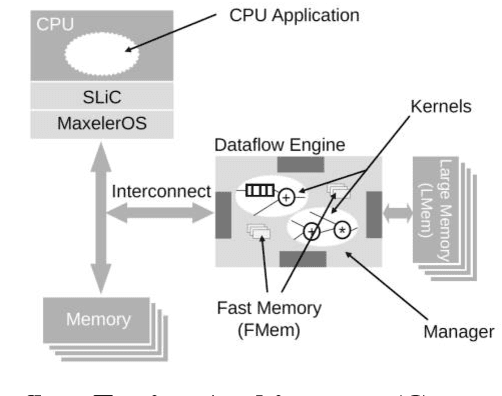
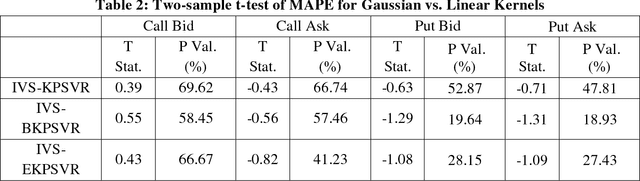
In this work, we design a machine learning based method, online adaptive primal support vector regression (SVR), to model the implied volatility surface (IVS). The algorithm proposed is the first derivation and implementation of an online primal kernel SVR. It features enhancements that allow efficient online adaptive learning by embedding the idea of local fitness and budget maintenance to dynamically update support vectors upon pattern drifts. For algorithm acceleration, we implement its most computationally intensive parts in a Field Programmable Gate Arrays hardware, where a 132x speedup over CPU is achieved during online prediction. Using intraday tick data from the E-mini S&P 500 options market, we show that the Gaussian kernel outperforms the linear kernel in regulating the size of support vectors, and that our empirical IVS algorithm beats two competing online methods with regards to model complexity and regression errors (the mean absolute percentage error of our algorithm is up to 13%). Best results are obtained at the center of the IVS grid due to its larger number of adjacent support vectors than the edges of the grid. Sensitivity analysis is also presented to demonstrate how hyper parameters affect the error rates and model complexity.
Competitive Multi-agent Inverse Reinforcement Learning with Sub-optimal Demonstrations
Jun 05, 2018
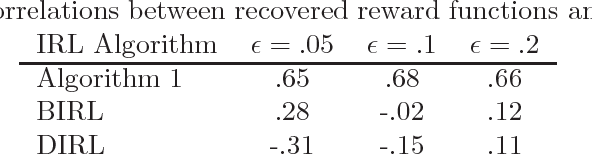
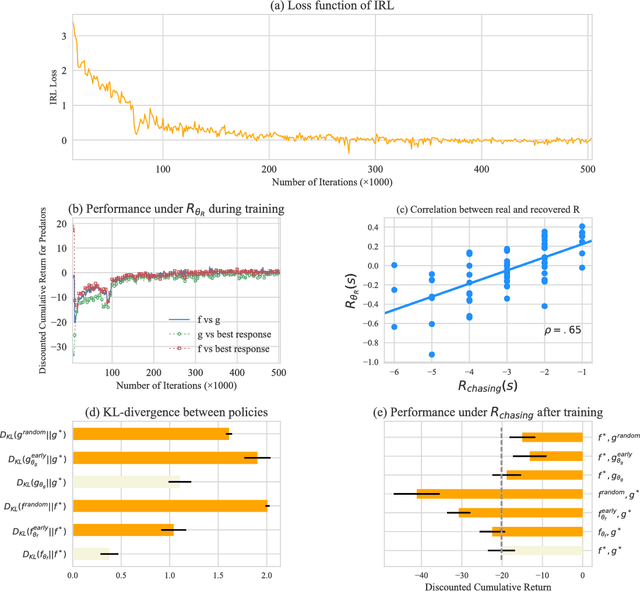

This paper considers the problem of inverse reinforcement learning in zero-sum stochastic games when expert demonstrations are known to be not optimal. Compared to previous works that decouple agents in the game by assuming optimality in expert strategies, we introduce a new objective function that directly pits experts against Nash Equilibrium strategies, and we design an algorithm to solve for the reward function in the context of inverse reinforcement learning with deep neural networks as model approximations. In our setting the model and algorithm do not decouple by agent. In order to find Nash Equilibrium in large-scale games, we also propose an adversarial training algorithm for zero-sum stochastic games, and show the theoretical appeal of non-existence of local optima in its objective function. In our numerical experiments, we demonstrate that our Nash Equilibrium and inverse reinforcement learning algorithms address games that are not amenable to previous approaches using tabular representations. Moreover, with sub-optimal expert demonstrations our algorithms recover both reward functions and strategies with good quality.
Forecasting Crime with Deep Learning
Jun 05, 2018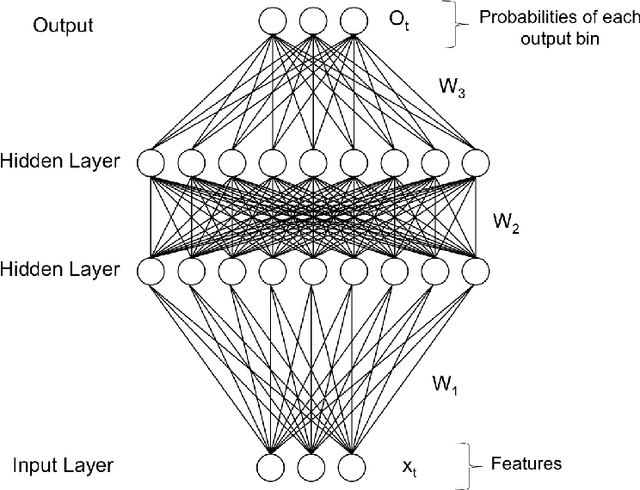

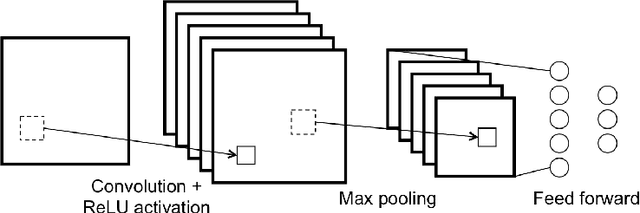
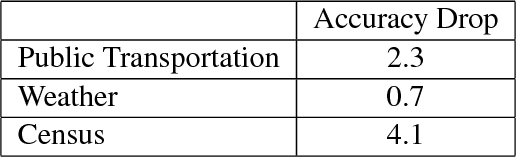
The objective of this work is to take advantage of deep neural networks in order to make next day crime count predictions in a fine-grain city partition. We make predictions using Chicago and Portland crime data, which is augmented with additional datasets covering weather, census data, and public transportation. The crime counts are broken into 10 bins and our model predicts the most likely bin for a each spatial region at a daily level. We train this data using increasingly complex neural network structures, including variations that are suited to the spatial and temporal aspects of the crime prediction problem. With our best model we are able to predict the correct bin for overall crime count with 75.6% and 65.3% accuracy for Chicago and Portland, respectively. The results show the efficacy of neural networks for the prediction problem and the value of using external datasets in addition to standard crime data.
Bayesian active learning for choice models with deep Gaussian processes
May 04, 2018
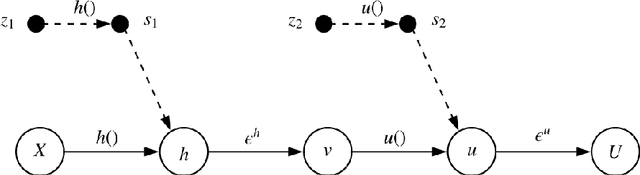
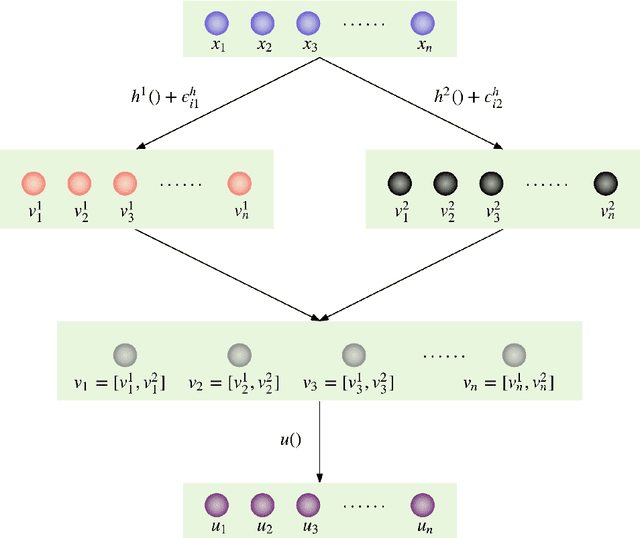
In this paper, we propose an active learning algorithm and models which can gradually learn individual's preference through pairwise comparisons. The active learning scheme aims at finding individual's most preferred choice with minimized number of pairwise comparisons. The pairwise comparisons are encoded into probabilistic models based on assumptions of choice models and deep Gaussian processes. The next-to-compare decision is determined by a novel acquisition function. We benchmark the proposed algorithm and models using functions with multiple local optima and one public airline itinerary dataset. The experiments indicate the effectiveness of our active learning algorithm and models.
k-Nearest Neighbors by Means of Sequence to Sequence Deep Neural Networks and Memory Networks
May 02, 2018



k-Nearest Neighbors is one of the most fundamental but effective classification models. In this paper, we propose two families of models built on a sequence to sequence model and a memory network model to mimic the k-Nearest Neighbors model, which generate a sequence of labels, a sequence of out-of-sample feature vectors and a final label for classification, and thus they could also function as oversamplers. We also propose 'out-of-core' versions of our models which assume that only a small portion of data can be loaded into memory. Computational experiments show that our models outperform k-Nearest Neighbors, a feed-forward neural network and a memory network, due to the fact that our models must produce additional output and not just the label. As an oversample on imbalanced datasets, the sequence to sequence kNN model often outperforms Synthetic Minority Over-sampling Technique and Adaptive Synthetic Sampling.
Improved Classification Based on Deep Belief Networks
Apr 25, 2018
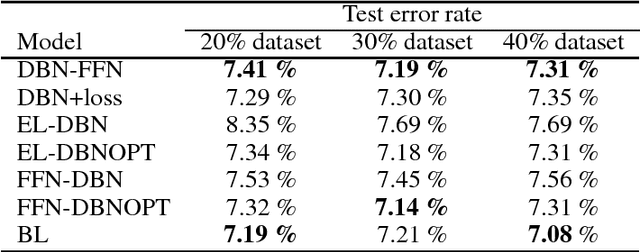
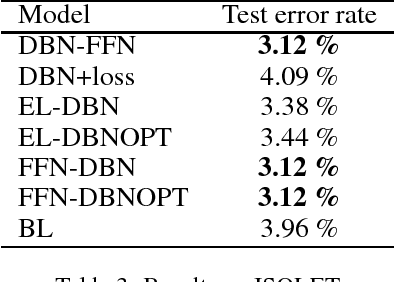
For better classification generative models are used to initialize the model and model features before training a classifier. Typically it is needed to solve separate unsupervised and supervised learning problems. Generative restricted Boltzmann machines and deep belief networks are widely used for unsupervised learning. We developed several supervised models based on DBN in order to improve this two-phase strategy. Modifying the loss function to account for expectation with respect to the underlying generative model, introducing weight bounds, and multi-level programming are applied in model development. The proposed models capture both unsupervised and supervised objectives effectively. The computational study verifies that our models perform better than the two-phase training approach.
A Stochastic Large-scale Machine Learning Algorithm for Distributed Features and Observations
Mar 29, 2018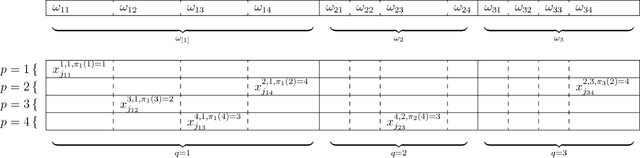

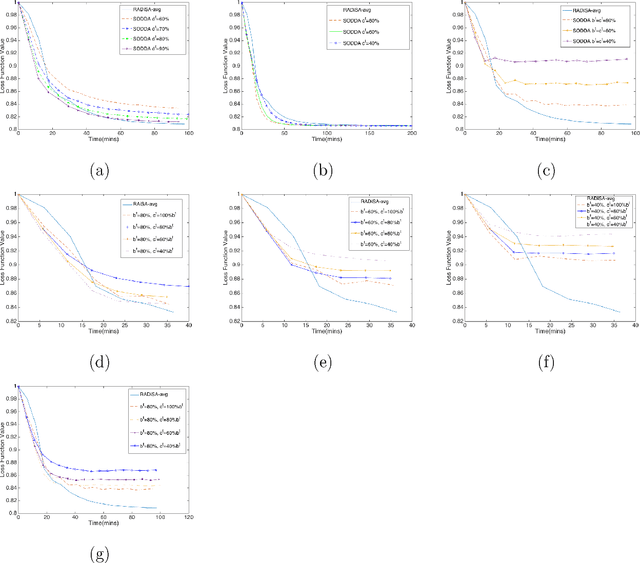
As the size of modern data sets exceeds the disk and memory capacities of a single computer, machine learning practitioners have resorted to parallel and distributed computing. Given that optimization is one of the pillars of machine learning and predictive modeling, distributed optimization methods have recently garnered ample attention, in particular when either observations or features are distributed, but not both. We propose a general stochastic algorithm where observations, features, and gradient components can be sampled in a double distributed setting, i.e., with both features and observations distributed. Very technical analyses establish convergence properties of the algorithm under different conditions on the learning rate (diminishing to zero or constant). Computational experiments in Spark demonstrate a superior performance of our algorithm versus a benchmark in early iterations of the algorithm, which is due to the stochastic components of the algorithm.
Truth Validation with Evidence
Feb 15, 2018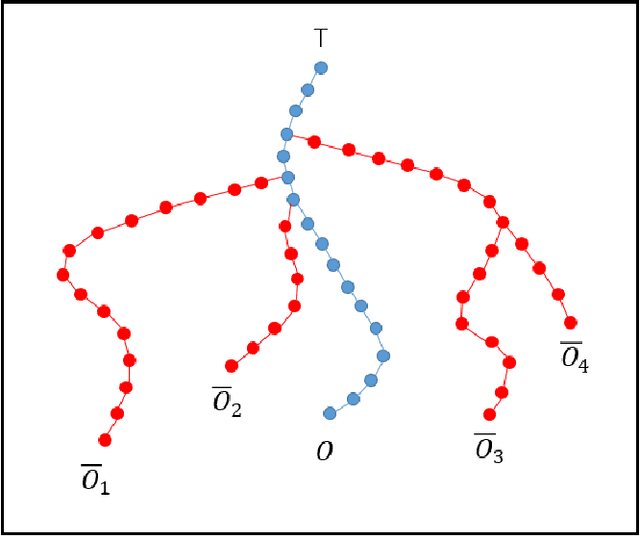

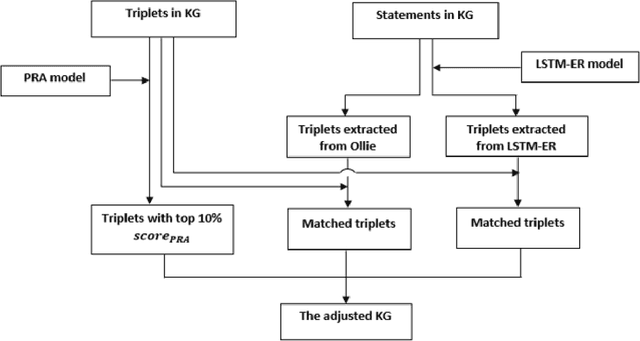
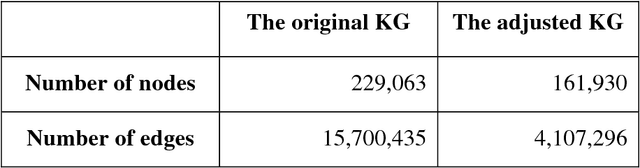
In the modern era, abundant information is easily accessible from various sources, however only a few of these sources are reliable as they mostly contain unverified contents. We develop a system to validate the truthfulness of a given statement together with underlying evidence. The proposed system provides supporting evidence when the statement is tagged as false. Our work relies on an inference method on a knowledge graph (KG) to identify the truthfulness of statements. In order to extract the evidence of falseness, the proposed algorithm takes into account combined knowledge from KG and ontologies. The system shows very good results as it provides valid and concise evidence. The quality of KG plays a role in the performance of the inference method which explicitly affects the performance of our evidence-extracting algorithm.
Predicting Shot Making in Basketball Learnt from Adversarial Multiagent Trajectories
Dec 28, 2017

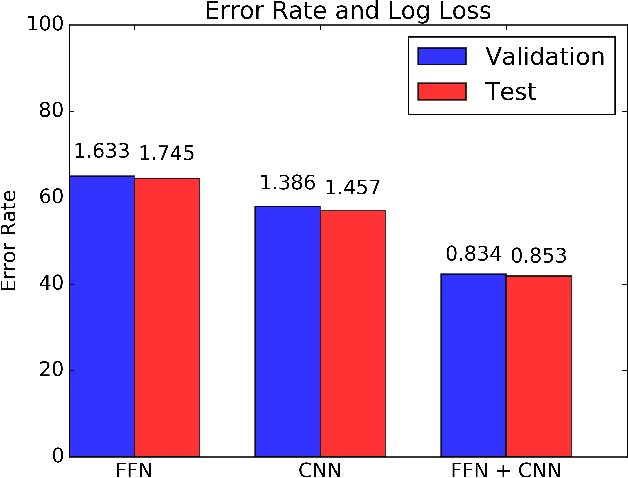
In this paper, we predict the likelihood of a player making a shot in basketball from multiagent trajectories. Previous approaches to similar problems center on hand-crafting features to capture domain specific knowledge. Although intuitive, recent work in deep learning has shown this approach is prone to missing important predictive features. To circumvent this issue, we present a convolutional neural network (CNN) approach where we initially represent the multiagent behavior as an image. To encode the adversarial nature of basketball, we use a multi-channel image which we then feed into a CNN. Additionally, to capture the temporal aspect of the trajectories we "fade" the player trajectories. We find that this approach is superior to a traditional FFN model. By using gradient ascent to create images using an already trained CNN, we discover what features the CNN filters learn. Last, we find that a combined CNN+FFN is the best performing network with an error rate of 39%.