 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinBackProp -- Backpropagating through Minimal Solvers
Apr 27, 2024We present an approach to backpropagating through minimal problem solvers in end-to-end neural network training. Traditional methods relying on manually constructed formulas, finite differences, and autograd are laborious, approximate, and unstable for complex minimal problem solvers. We show that using the Implicit function theorem to calculate derivatives to backpropagate through the solution of a minimal problem solver is simple, fast, and stable. We compare our approach to (i) using the standard autograd on minimal problem solvers and relate it to existing backpropagation formulas through SVD-based and Eig-based solvers and (ii) implementing the backprop with an existing PyTorch Deep Declarative Networks (DDN) framework. We demonstrate our technique on a toy example of training outlier-rejection weights for 3D point registration and on a real application of training an outlier-rejection and RANSAC sampling network in image matching. Our method provides $100\%$ stability and is 10 times faster compared to autograd, which is unstable and slow, and compared to DDN, which is stable but also slow.
Image Manipulation with Perceptual Discriminators
Sep 05, 2018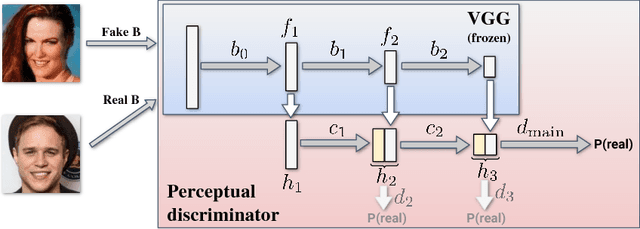
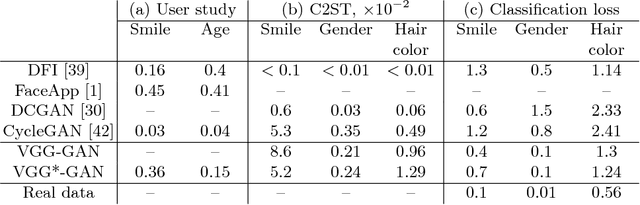


Systems that perform image manipulation using deep convolutional networks have achieved remarkable realism. Perceptual losses and losses based on adversarial discriminators are the two main classes of learning objectives behind these advances. In this work, we show how these two ideas can be combined in a principled and non-additive manner for unaligned image translation tasks. This is accomplished through a special architecture of the discriminator network inside generative adversarial learning framework. The new architecture, that we call a perceptual discriminator, embeds the convolutional parts of a pre-trained deep classification network inside the discriminator network. The resulting architecture can be trained on unaligned image datasets while benefiting from the robustness and efficiency of perceptual losses. We demonstrate the merits of the new architecture in a series of qualitative and quantitative comparisons with baseline approaches and state-of-the-art frameworks for unaligned image translation.
DeepWarp: Photorealistic Image Resynthesis for Gaze Manipulation
Jul 26, 2016
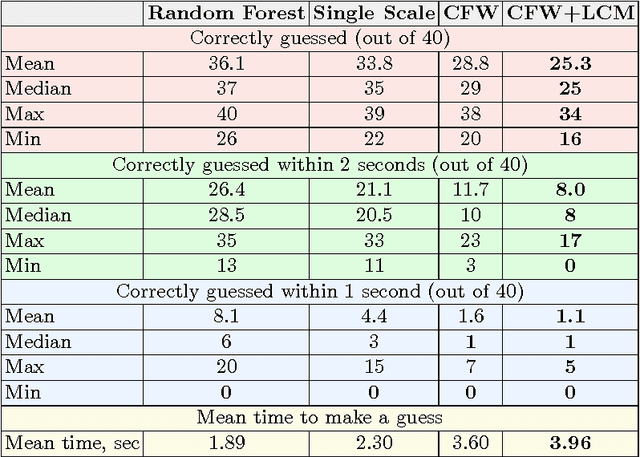
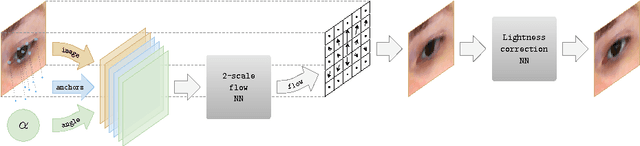
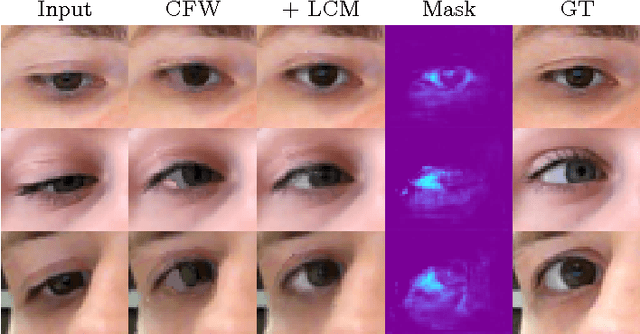
In this work, we consider the task of generating highly-realistic images of a given face with a redirected gaze. We treat this problem as a specific instance of conditional image generation and suggest a new deep architecture that can handle this task very well as revealed by numerical comparison with prior art and a user study. Our deep architecture performs coarse-to-fine warping with an additional intensity correction of individual pixels. All these operations are performed in a feed-forward manner, and the parameters associated with different operations are learned jointly in the end-to-end fashion. After learning, the resulting neural network can synthesize images with manipulated gaze, while the redirection angle can be selected arbitrarily from a certain range and provided as an input to the network.