 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemisupervised Manifold Alignment of Multimodal Remote Sensing Images
Apr 15, 2021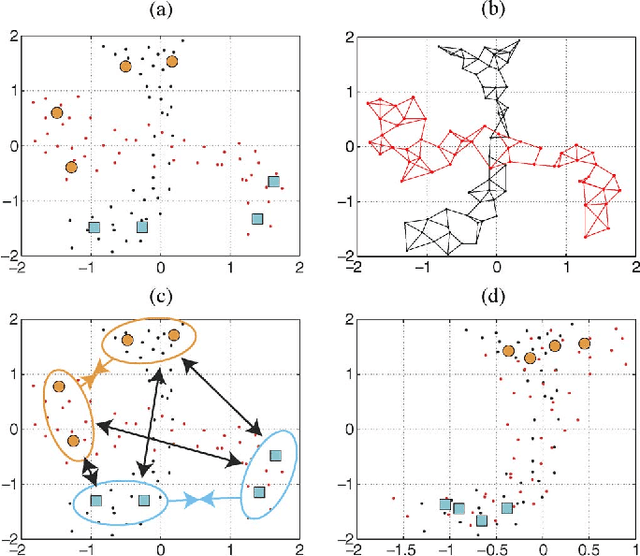
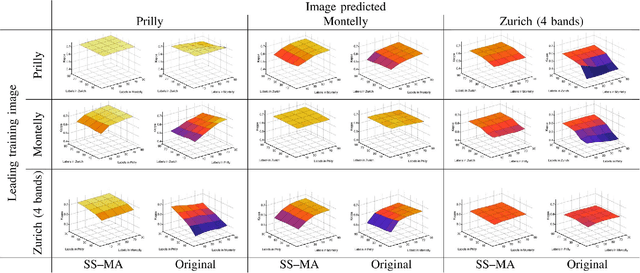
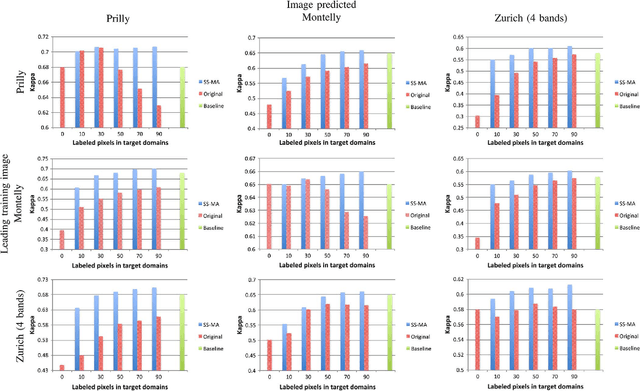

We introduce a method for manifold alignment of different modalities (or domains) of remote sensing images. The problem is recurrent when a set of multitemporal, multisource, multisensor and multiangular images is available. In these situations, images should ideally be spatially coregistred, corrected and compensated for differences in the image domains. Such procedures require the interaction of the user, involve tuning of many parameters and heuristics, and are usually applied separately. Changes of sensors and acquisition conditions translate into shifts, twists, warps and foldings of the image distributions (or manifolds). The proposed semisupervised manifold alignment (SS-MA) method aligns the images working directly on their manifolds, and is thus not restricted to images of the same resolutions, either spectral or spatial. SS-MA pulls close together samples of the same class while pushing those of different classes apart. At the same time, it preserves the geometry of each manifold along the transformation. The method builds a linear invertible transformation to a latent space where all images are alike, and reduces to solving a generalized eigenproblem of moderate size. We study the performance of SS-MA in toy examples and in real multiangular, multitemporal, and multisource image classification problems. The method performs well for strong deformations and leads to accurate classification for all domains.
Learning User's confidence for active learning
Apr 15, 2021
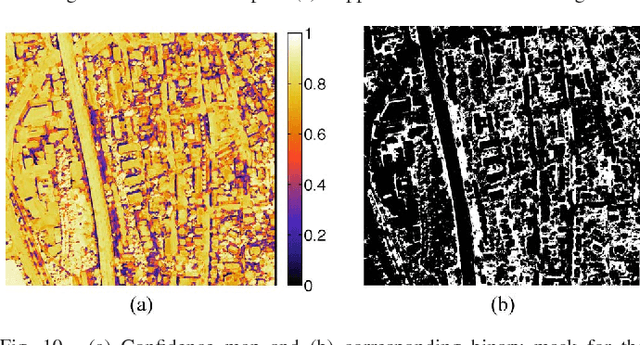
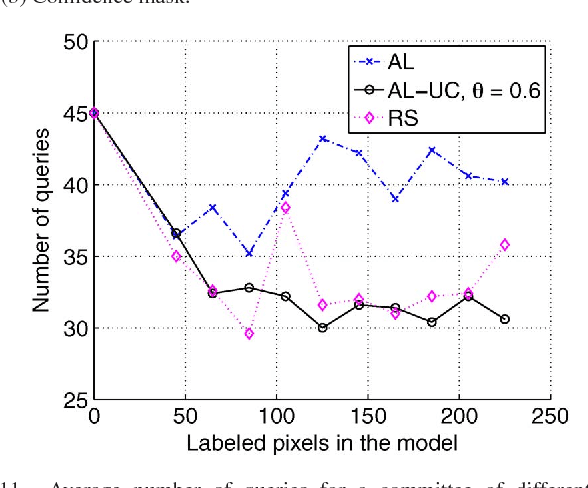
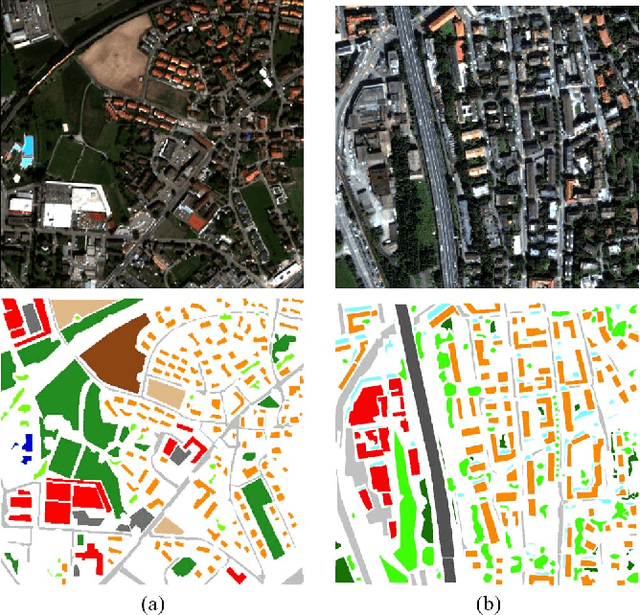
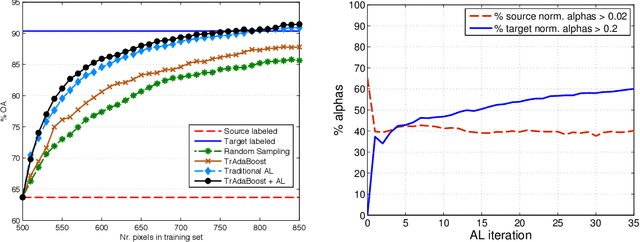
In this paper, we study the applicability of active learning in operative scenarios: more particularly, we consider the well-known contradiction between the active learning heuristics, which rank the pixels according to their uncertainty, and the user's confidence in labeling, which is related to both the homogeneity of the pixel context and user's knowledge of the scene. We propose a filtering scheme based on a classifier that learns the confidence of the user in labeling, thus minimizing the queries where the user would not be able to provide a class for the pixel. The capacity of a model to learn the user's confidence is studied in detail, also showing the effect of resolution is such a learning task. Experiments on two QuickBird images of different resolutions (with and without pansharpening) and considering committees of users prove the efficiency of the filtering scheme proposed, which maximizes the number of useful queries with respect to traditional active learning.
A survey of active learning algorithms for supervised remote sensing image classification
Apr 15, 2021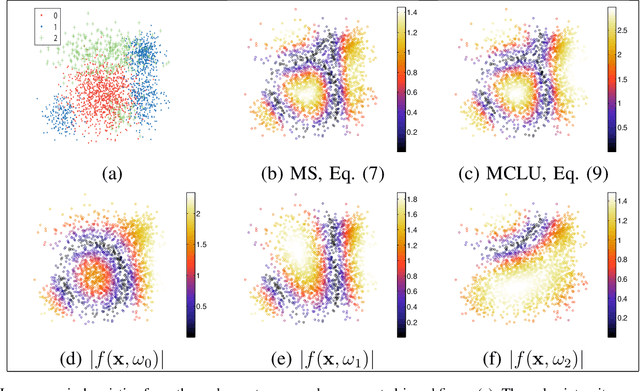
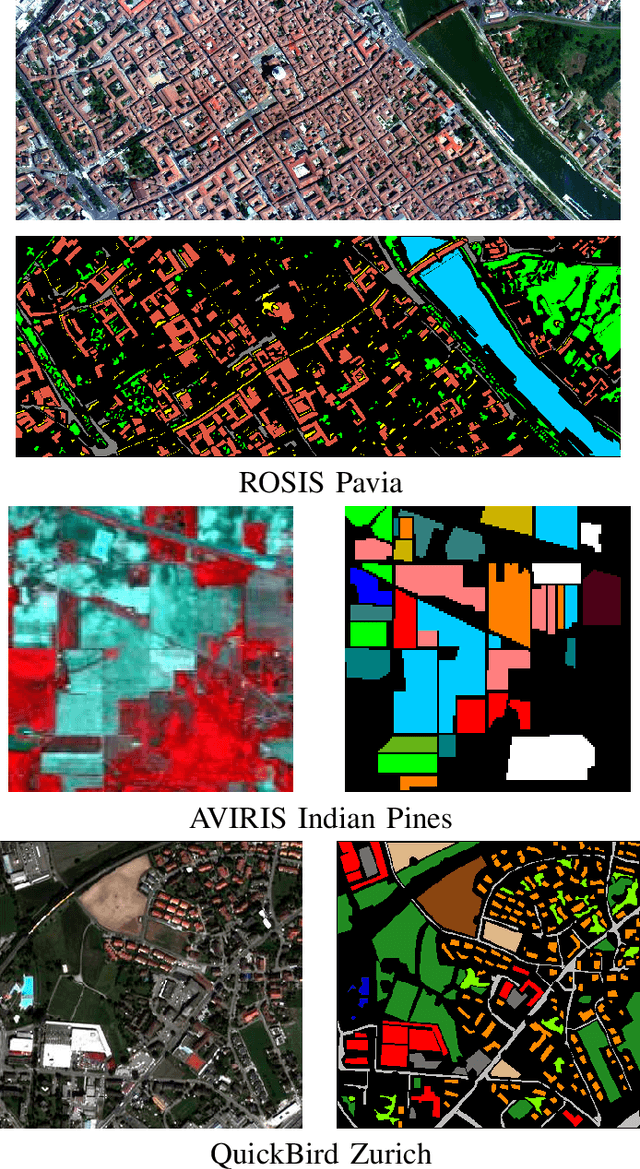

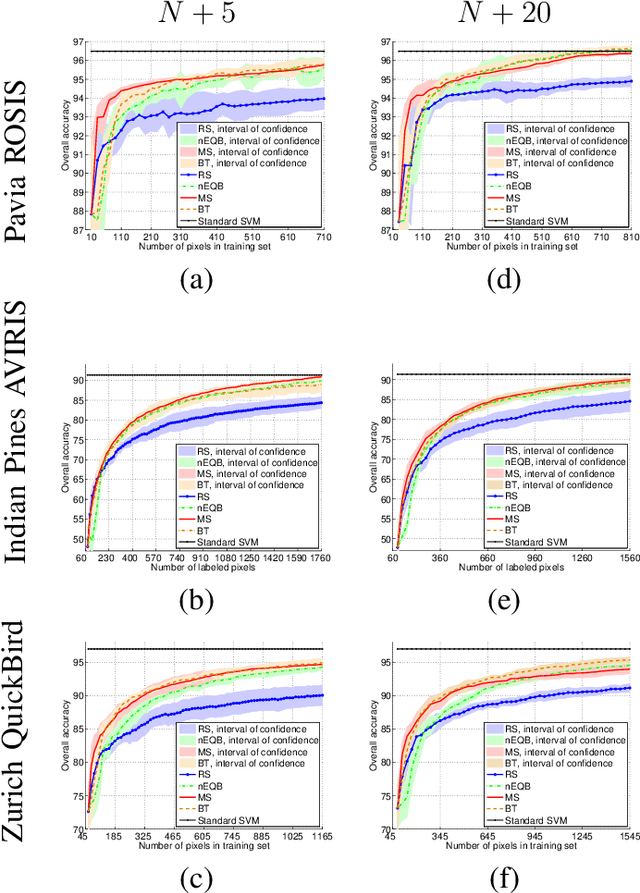
Defining an efficient training set is one of the most delicate phases for the success of remote sensing image classification routines. The complexity of the problem, the limited temporal and financial resources, as well as the high intraclass variance can make an algorithm fail if it is trained with a suboptimal dataset. Active learning aims at building efficient training sets by iteratively improving the model performance through sampling. A user-defined heuristic ranks the unlabeled pixels according to a function of the uncertainty of their class membership and then the user is asked to provide labels for the most uncertain pixels. This paper reviews and tests the main families of active learning algorithms: committee, large margin and posterior probability-based. For each of them, the most recent advances in the remote sensing community are discussed and some heuristics are detailed and tested. Several challenging remote sensing scenarios are considered, including very high spatial resolution and hyperspectral image classification. Finally, guidelines for choosing the good architecture are provided for new and/or unexperienced user.
Recent Advances in Domain Adaptation for the Classification of Remote Sensing Data
Apr 15, 2021
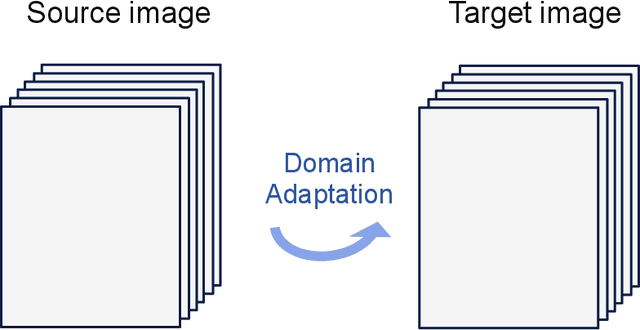
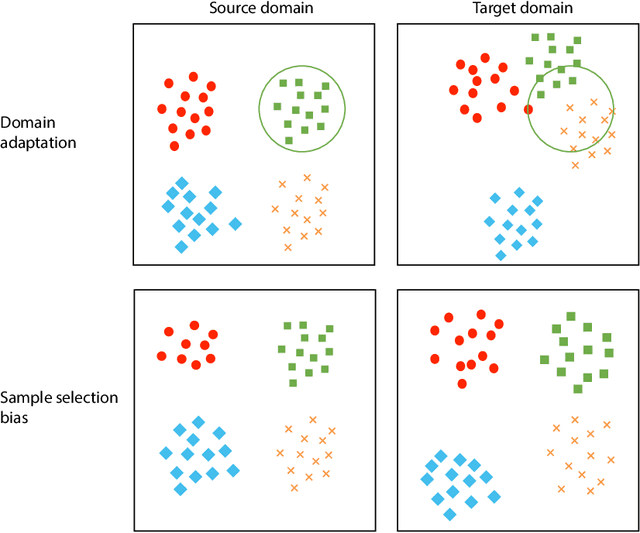
The success of supervised classification of remotely sensed images acquired over large geographical areas or at short time intervals strongly depends on the representativity of the samples used to train the classification algorithm and to define the model. When training samples are collected from an image (or a spatial region) different from the one used for mapping, spectral shifts between the two distributions are likely to make the model fail. Such shifts are generally due to differences in acquisition and atmospheric conditions or to changes in the nature of the object observed. In order to design classification methods that are robust to data-set shifts, recent remote sensing literature has considered solutions based on domain adaptation (DA) approaches. Inspired by machine learning literature, several DA methods have been proposed to solve specific problems in remote sensing data classification. This paper provides a critical review of the recent advances in DA for remote sensing and presents an overview of methods divided into four categories: i) invariant feature selection; ii) representation matching; iii) adaptation of classifiers and iv) selective sampling. We provide an overview of recent methodologies, as well as examples of application of the considered techniques to real remote sensing images characterized by very high spatial and spectral resolution. Finally, we propose guidelines to the selection of the method to use in real application scenarios.
Towards a Collective Agenda on AI for Earth Science Data Analysis
Apr 11, 2021
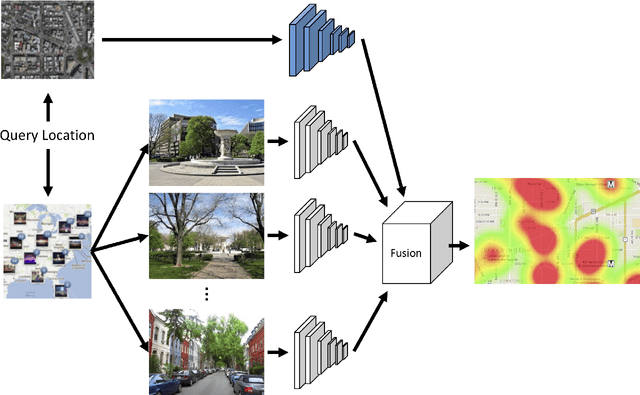
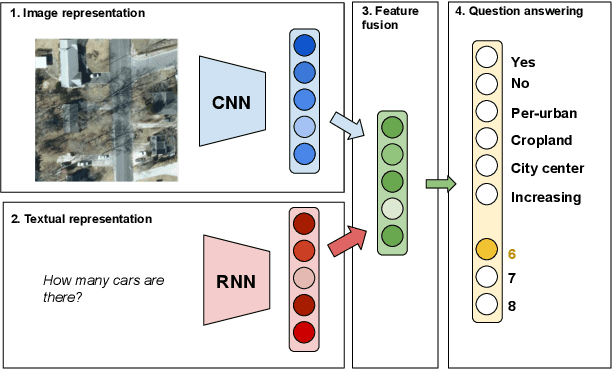

In the last years we have witnessed the fields of geosciences and remote sensing and artificial intelligence to become closer. Thanks to both the massive availability of observational data, improved simulations, and algorithmic advances, these disciplines have found common objectives and challenges to advance the modeling and understanding of the Earth system. Despite such great opportunities, we also observed a worrying tendency to remain in disciplinary comfort zones applying recent advances from artificial intelligence on well resolved remote sensing problems. Here we take a position on research directions where we think the interface between these fields will have the most impact and become potential game changers. In our declared agenda for AI on Earth sciences, we aim to inspire researchers, especially the younger generations, to tackle these challenges for a real advance of remote sensing and the geosciences.
Self-supervised pre-training enhances change detection in Sentinel-2 imagery
Jan 20, 2021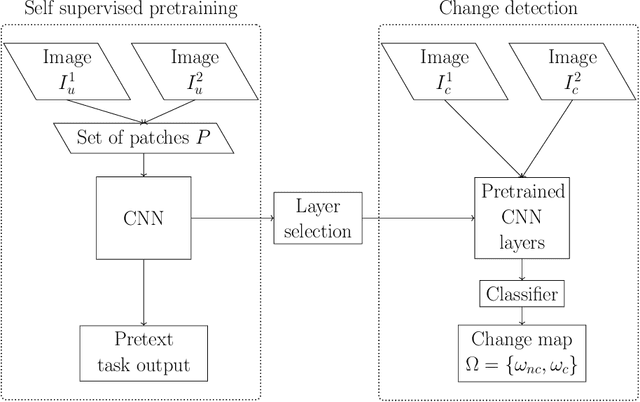
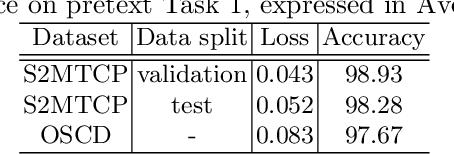
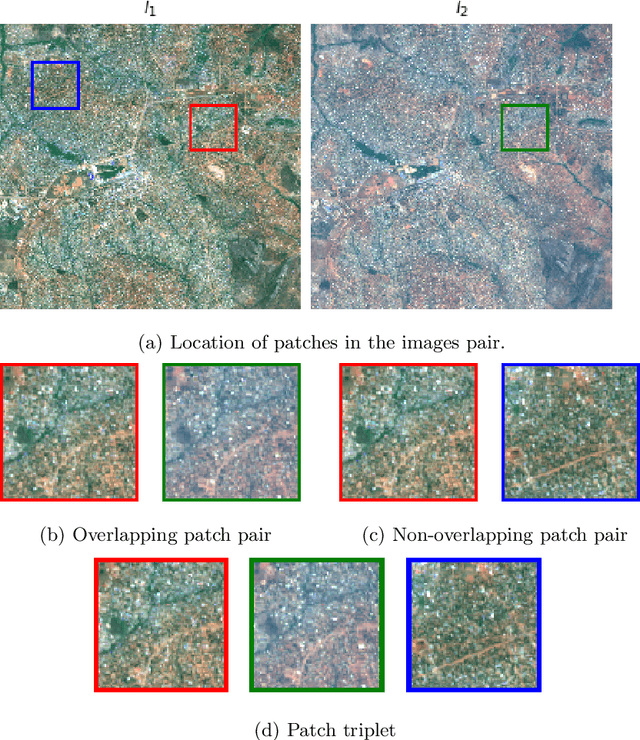
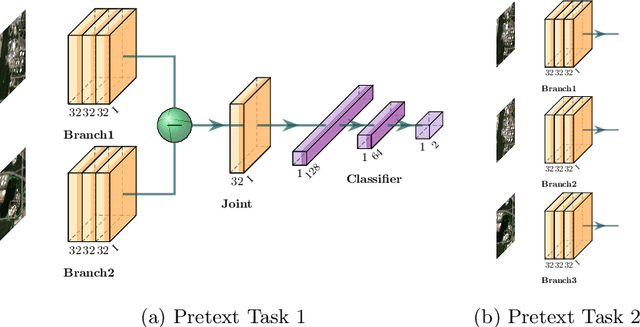
While annotated images for change detection using satellite imagery are scarce and costly to obtain, there is a wealth of unlabeled images being generated every day. In order to leverage these data to learn an image representation more adequate for change detection, we explore methods that exploit the temporal consistency of Sentinel-2 times series to obtain a usable self-supervised learning signal. For this, we build and make publicly available (https://zenodo.org/record/4280482) the Sentinel-2 Multitemporal Cities Pairs (S2MTCP) dataset, containing multitemporal image pairs from 1520 urban areas worldwide. We test the results of multiple self-supervised learning methods for pre-training models for change detection and apply it on a public change detection dataset made of Sentinel-2 image pairs (OSCD).
Semantic Segmentation of Remote Sensing Images with Sparse Annotations
Jan 10, 2021

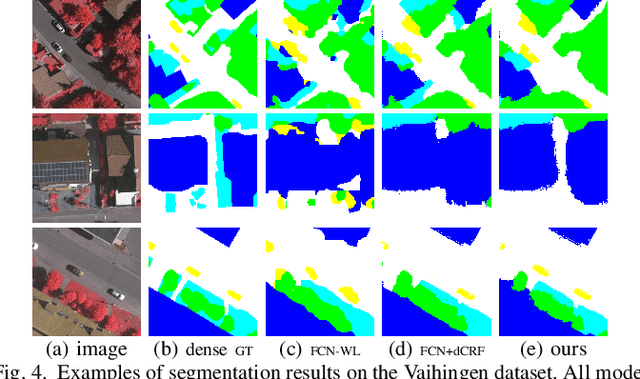
Training Convolutional Neural Networks (CNNs) for very high resolution images requires a large quantity of high-quality pixel-level annotations, which is extremely labor- and time-consuming to produce. Moreover, professional photo interpreters might have to be involved for guaranteeing the correctness of annotations. To alleviate such a burden, we propose a framework for semantic segmentation of aerial images based on incomplete annotations, where annotators are asked to label a few pixels with easy-to-draw scribbles. To exploit these sparse scribbled annotations, we propose the FEature and Spatial relaTional regulArization (FESTA) method to complement the supervised task with an unsupervised learning signal that accounts for neighbourhood structures both in spatial and feature terms.
A deep network approach to multitemporal cloud detection
Dec 09, 2020
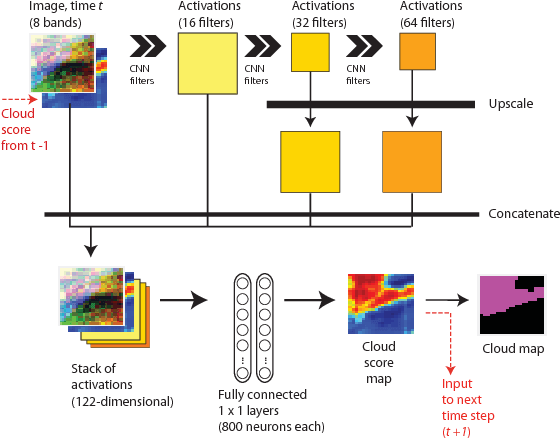
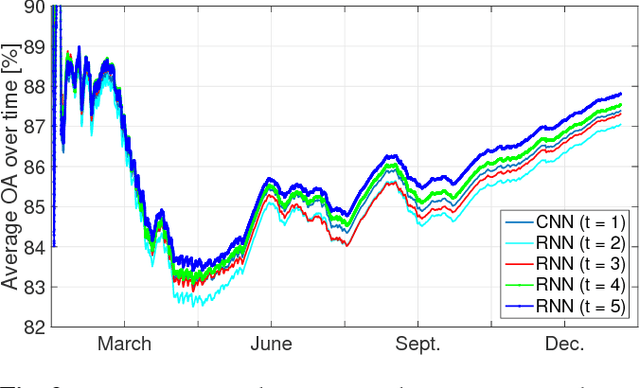
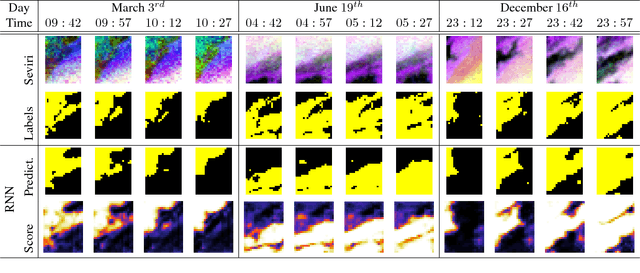
We present a deep learning model with temporal memory to detect clouds in image time series acquired by the Seviri imager mounted on the Meteosat Second Generation (MSG) satellite. The model provides pixel-level cloud maps with related confidence and propagates information in time via a recurrent neural network structure. With a single model, we are able to outline clouds along all year and during day and night with high accuracy.
Multi-temporal and multi-source remote sensing image classification by nonlinear relative normalization
Dec 07, 2020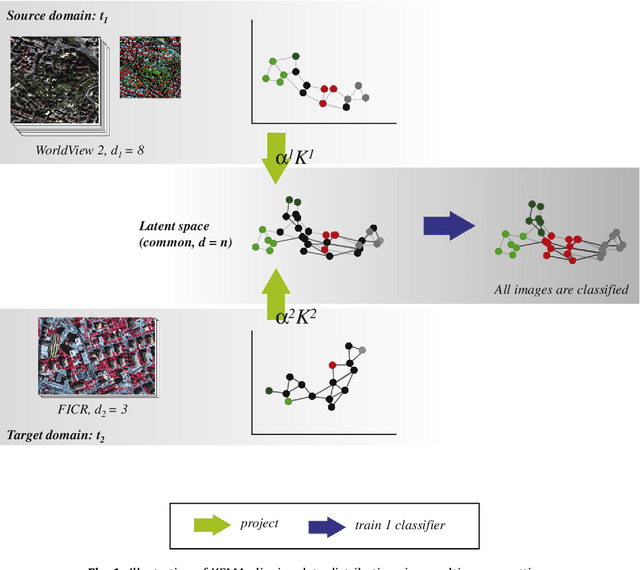


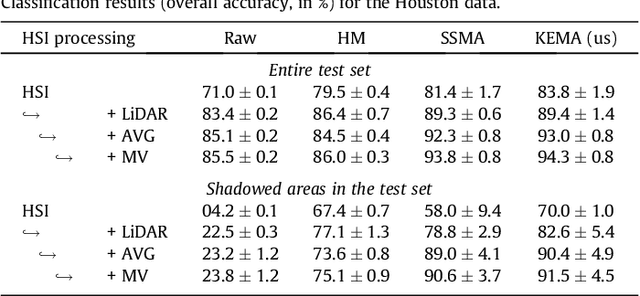
Remote sensing image classification exploiting multiple sensors is a very challenging problem: data from different modalities are affected by spectral distortions and mis-alignments of all kinds, and this hampers re-using models built for one image to be used successfully in other scenes. In order to adapt and transfer models across image acquisitions, one must be able to cope with datasets that are not co-registered, acquired under different illumination and atmospheric conditions, by different sensors, and with scarce ground references. Traditionally, methods based on histogram matching have been used. However, they fail when densities have very different shapes or when there is no corresponding band to be matched between the images. An alternative builds upon \emph{manifold alignment}. Manifold alignment performs a multidimensional relative normalization of the data prior to product generation that can cope with data of different dimensionality (e.g. different number of bands) and possibly unpaired examples. Aligning data distributions is an appealing strategy, since it allows to provide data spaces that are more similar to each other, regardless of the subsequent use of the transformed data. In this paper, we study a methodology that aligns data from different domains in a nonlinear way through {\em kernelization}. We introduce the Kernel Manifold Alignment (KEMA) method, which provides a flexible and discriminative projection map, exploits only a few labeled samples (or semantic ties) in each domain, and reduces to solving a generalized eigenvalue problem. We successfully test KEMA in multi-temporal and multi-source very high resolution classification tasks, as well as on the task of making a model invariant to shadowing for hyperspectral imaging.
Contextual Semantic Interpretability
Sep 18, 2020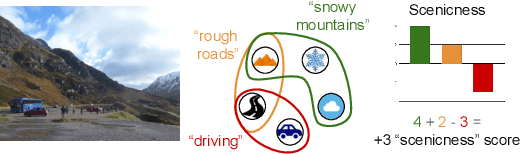
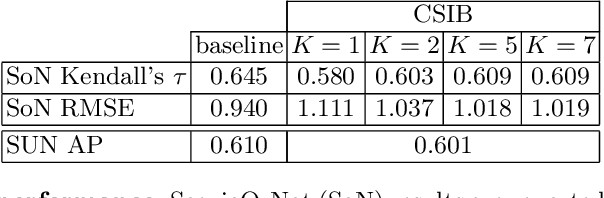
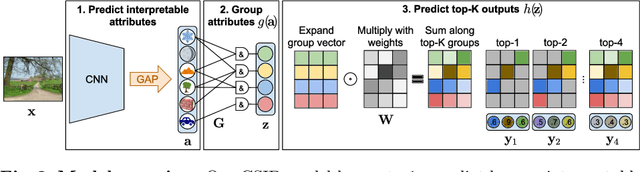
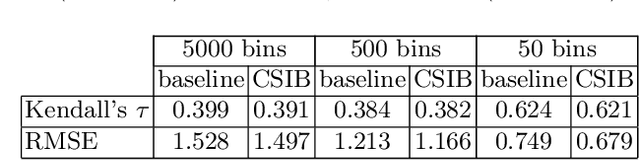
Convolutional neural networks (CNN) are known to learn an image representation that captures concepts relevant to the task, but do so in an implicit way that hampers model interpretability. However, one could argue that such a representation is hidden in the neurons and can be made explicit by teaching the model to recognize semantically interpretable attributes that are present in the scene. We call such an intermediate layer a \emph{semantic bottleneck}. Once the attributes are learned, they can be re-combined to reach the final decision and provide both an accurate prediction and an explicit reasoning behind the CNN decision. In this paper, we look into semantic bottlenecks that capture context: we want attributes to be in groups of a few meaningful elements and participate jointly to the final decision. We use a two-layer semantic bottleneck that gathers attributes into interpretable, sparse groups, allowing them contribute differently to the final output depending on the context. We test our contextual semantic interpretable bottleneck (CSIB) on the task of landscape scenicness estimation and train the semantic interpretable bottleneck using an auxiliary database (SUN Attributes). Our model yields in predictions as accurate as a non-interpretable baseline when applied to a real-world test set of Flickr images, all while providing clear and interpretable explanations for each prediction.