 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptron Theory for Predicting the Accuracy of Neural Networks
Dec 14, 2020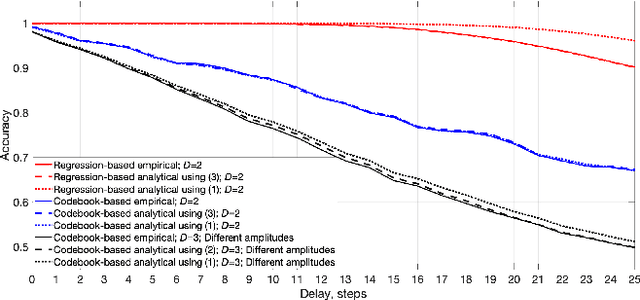
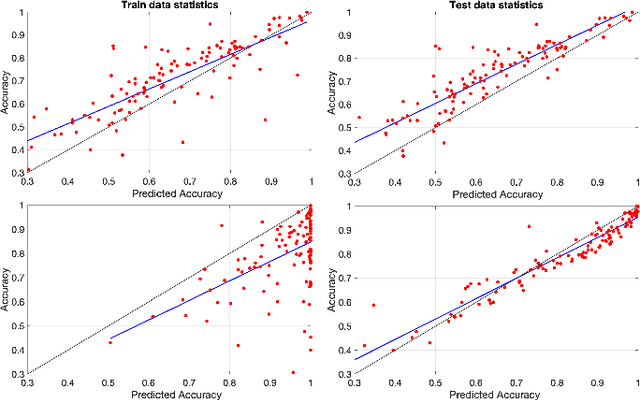
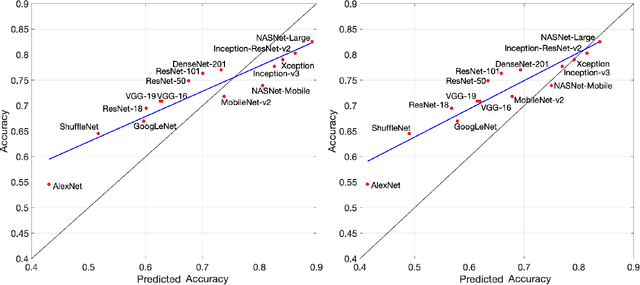
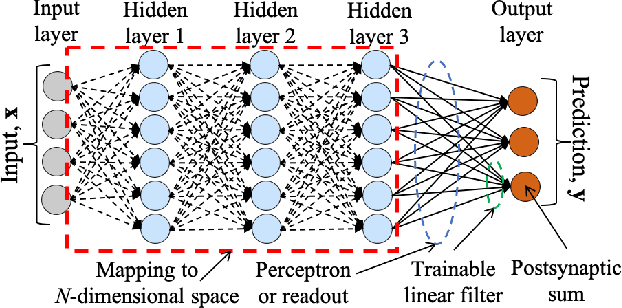
Many neural network models have been successful at classification problems, but their operation is still treated as a black box. Here, we developed a theory for one-layer perceptrons that can predict performance on classification tasks. This theory is a generalization of an existing theory for predicting the performance of Echo State Networks and connectionist models for symbolic reasoning known as Vector Symbolic Architectures. In this paper, we first show that the proposed perceptron theory can predict the performance of Echo State Networks, which could not be described by the previous theory. Second, we apply our perceptron theory to the last layers of shallow randomly connected and deep multi-layer networks. The full theory is based on Gaussian statistics, but it is analytically intractable. We explore numerical methods to predict network performance for problems with a small number of classes. For problems with a large number of classes, we investigate stochastic sampling methods and a tractable approximation to the full theory. The quality of predictions is assessed in three experimental settings, using reservoir computing networks on a memorization task, shallow randomly connected networks on a collection of classification datasets, and deep convolutional networks with the ImageNet dataset. This study offers a simple, bipartite approach to understand deep neural networks: the input is encoded by the last-but-one layers into a high-dimensional representation. This representation is mapped through the weights of the last layer into the postsynaptic sums of the output neurons. Specifically, the proposed perceptron theory uses the mean vector and covariance matrix of the postsynaptic sums to compute classification accuracies for the different classes. The first two moments of the distribution of the postsynaptic sums can predict the overall network performance quite accurately.
End to End Binarized Neural Networks for Text Classification
Oct 11, 2020
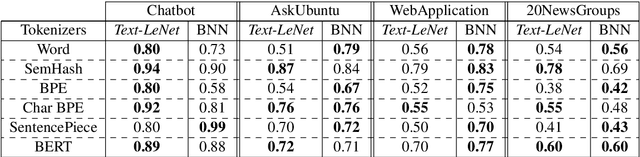

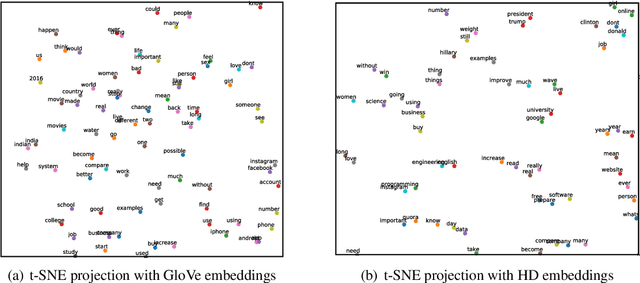
Deep neural networks have demonstrated their superior performance in almost every Natural Language Processing task, however, their increasing complexity raises concerns. In particular, these networks require high expenses on computational hardware, and training budget is a concern for many. Even for a trained network, the inference phase can be too demanding for resource-constrained devices, thus limiting its applicability. The state-of-the-art transformer models are a vivid example. Simplifying the computations performed by a network is one way of relaxing the complexity requirements. In this paper, we propose an end to end binarized neural network architecture for the intent classification task. In order to fully utilize the potential of end to end binarization, both input representations (vector embeddings of tokens statistics) and the classifier are binarized. We demonstrate the efficiency of such architecture on the intent classification of short texts over three datasets and for text classification with a larger dataset. The proposed architecture achieves comparable to the state-of-the-art results on standard intent classification datasets while utilizing ~ 20-40% lesser memory and training time. Furthermore, the individual components of the architecture, such as binarized vector embeddings of documents or binarized classifiers, can be used separately with not necessarily fully binary architectures.
Cellular Automata Can Reduce Memory Requirements of Collective-State Computing
Oct 07, 2020
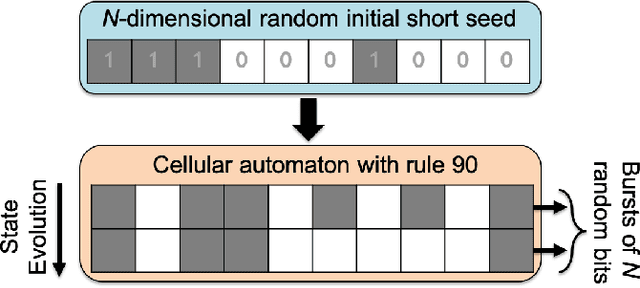
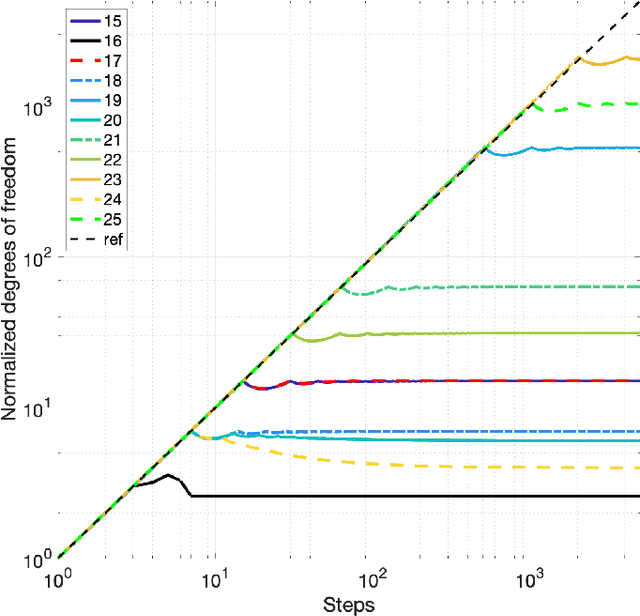
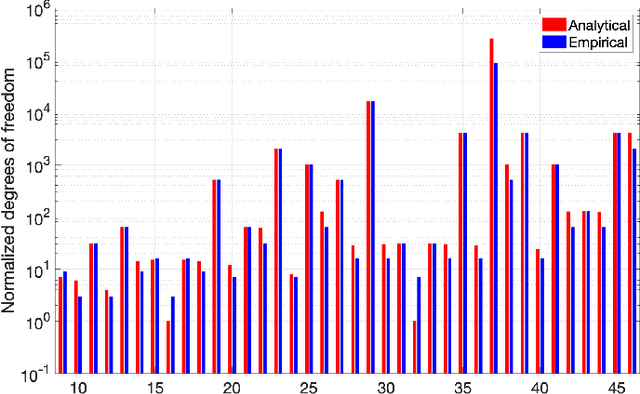
Various non-classical approaches of distributed information processing, such as neural networks, computation with Ising models, reservoir computing, vector symbolic architectures, and others, employ the principle of collective-state computing. In this type of computing, the variables relevant in a computation are superimposed into a single high-dimensional state vector, the collective-state. The variable encoding uses a fixed set of random patterns, which has to be stored and kept available during the computation. Here we show that an elementary cellular automaton with rule 90 (CA90) enables space-time tradeoff for collective-state computing models that use random dense binary representations, i.e., memory requirements can be traded off with computation running CA90. We investigate the randomization behavior of CA90, in particular, the relation between the length of the randomization period and the size of the grid, and how CA90 preserves similarity in the presence of the initialization noise. Based on these analyses we discuss how to optimize a collective-state computing model, in which CA90 expands representations on the fly from short seed patterns - rather than storing the full set of random patterns. The CA90 expansion is applied and tested in concrete scenarios using reservoir computing and vector symbolic architectures. Our experimental results show that collective-state computing with CA90 expansion performs similarly compared to traditional collective-state models, in which random patterns are generated initially by a pseudo-random number generator and then stored in a large memory.
Variable Binding for Sparse Distributed Representations: Theory and Applications
Sep 14, 2020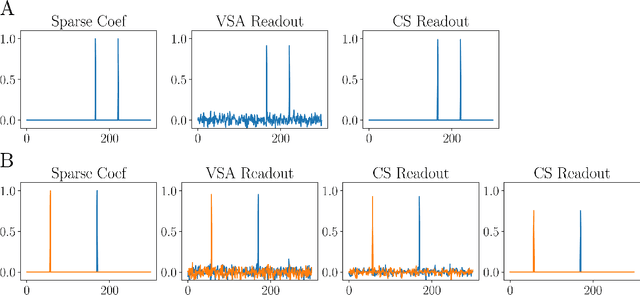
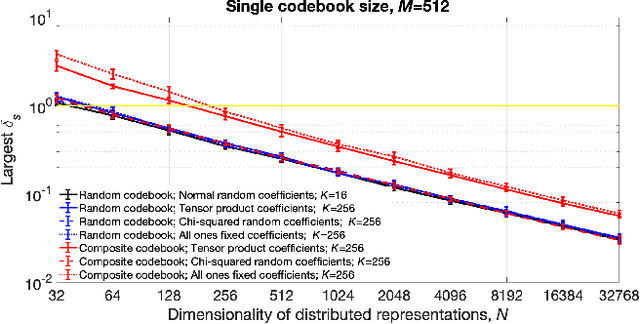
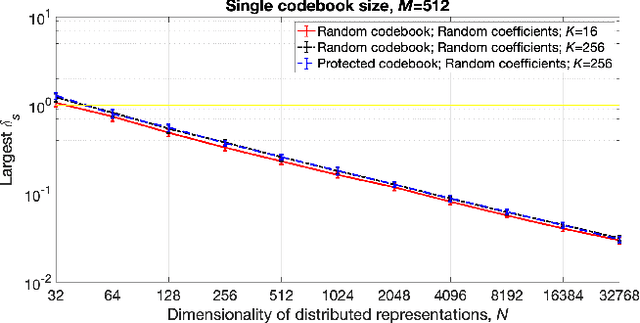
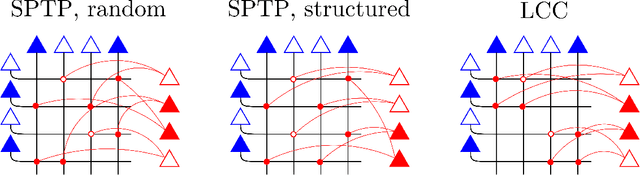
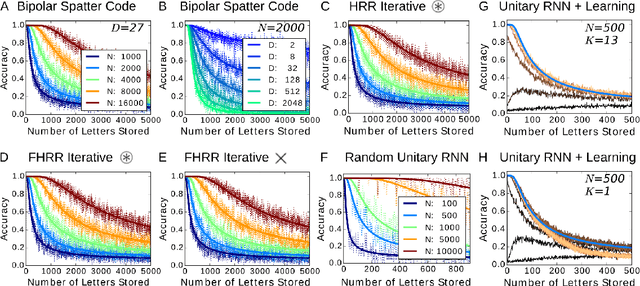
Symbolic reasoning and neural networks are often considered incompatible approaches. Connectionist models known as Vector Symbolic Architectures (VSAs) can potentially bridge this gap. However, classical VSAs and neural networks are still considered incompatible. VSAs encode symbols by dense pseudo-random vectors, where information is distributed throughout the entire neuron population. Neural networks encode features locally, often forming sparse vectors of neural activation. Following Rachkovskij (2001); Laiho et al. (2015), we explore symbolic reasoning with sparse distributed representations. The core operations in VSAs are dyadic operations between vectors to express variable binding and the representation of sets. Thus, algebraic manipulations enable VSAs to represent and process data structures in a vector space of fixed dimensionality. Using techniques from compressed sensing, we first show that variable binding between dense vectors in VSAs is mathematically equivalent to tensor product binding between sparse vectors, an operation which increases dimensionality. This result implies that dimensionality-preserving binding for general sparse vectors must include a reduction of the tensor matrix into a single sparse vector. Two options for sparsity-preserving variable binding are investigated. One binding method for general sparse vectors extends earlier proposals to reduce the tensor product into a vector, such as circular convolution. The other method is only defined for sparse block-codes, block-wise circular convolution. Our experiments reveal that variable binding for block-codes has ideal properties, whereas binding for general sparse vectors also works, but is lossy, similar to previous proposals. We demonstrate a VSA with sparse block-codes in example applications, cognitive reasoning and classification, and discuss its relevance for neuroscience and neural networks.
Commentaries on "Learning Sensorimotor Control with Neuromorphic Sensors: Toward Hyperdimensional Active Perception" [Science Robotics Vol. 4 Issue 30 (2019) 1-10
Mar 25, 2020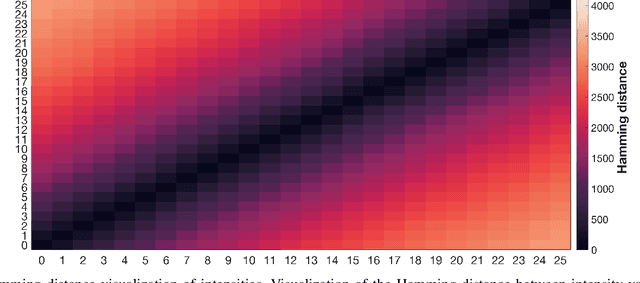
This correspondence comments on the findings reported in a recent Science Robotics article by Mitrokhin et al. [1]. The main goal of this commentary is to expand on some of the issues touched on in that article. Our experience is that hyperdimensional computing is very different from other approaches to computation and that it can take considerable exposure to its concepts before attaining practically useful understanding. Therefore, in order to provide an overview of the area to the first time reader of [1], the commentary includes a brief historic overview as well as connects the findings of the article to a larger body of literature existing in the area.
HyperEmbed: Tradeoffs Between Resources and Performance in NLP Tasks with Hyperdimensional Computing enabled Embedding of n-gram Statistics
Mar 03, 2020
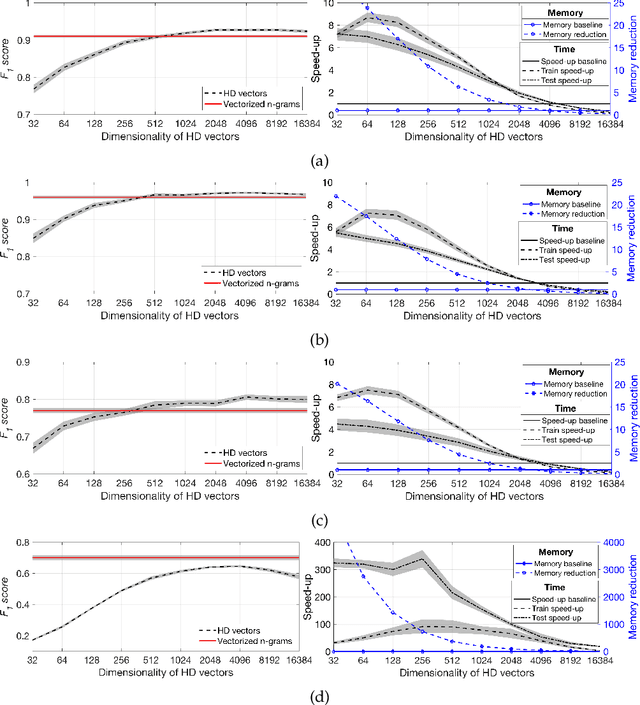
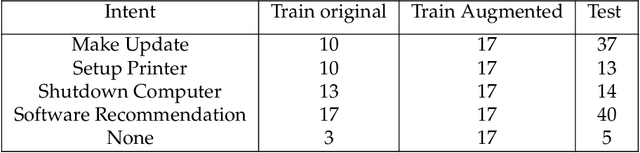
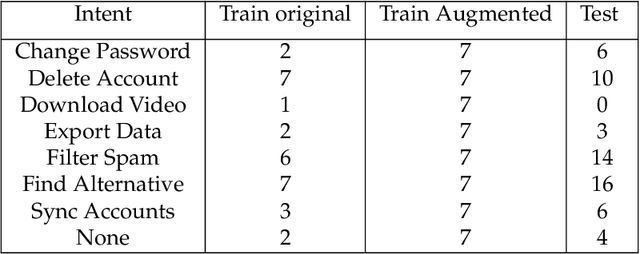
Recent advances in Deep Learning have led to a significant performance increase on several NLP tasks, however, the models become more and more computationally demanding. Therefore, this paper tackles the domain of computationally efficient algorithms for NLP tasks. In particular, it investigates distributed representations of n-gram statistics of texts. The representations are formed using hyperdimensional computing enabled embedding. These representations then serve as features, which are used as input to standard classifiers. We investigate the applicability of the embedding on one large and three small standard datasets for classification tasks using nine classifiers. The embedding achieved on par F1 scores while decreasing the time and memory requirements by several times compared to the conventional n-gram statistics, e.g., for one of the classifiers on a small dataset, the memory reduction was 6.18 times; while train and test speed-ups were 4.62 and 3.84 times, respectively. For many classifiers on the large dataset, the memory reduction was about 100 times and train and test speed-ups were over 100 times. More importantly, the usage of distributed representations formed via hyperdimensional computing allows dissecting the strict dependency between the dimensionality of the representation and the parameters of n-gram statistics, thus, opening a room for tradeoffs.
Density Encoding Enables Resource-Efficient Randomly Connected Neural Networks
Sep 19, 2019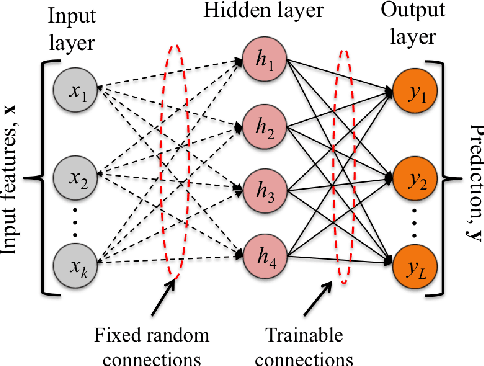
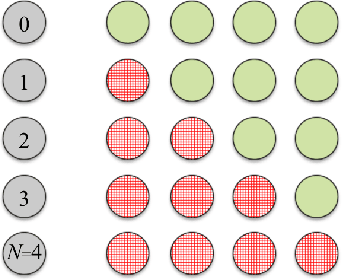
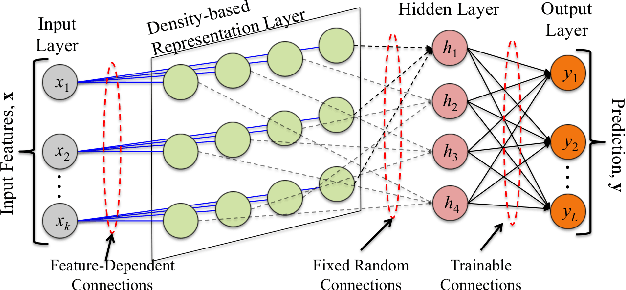
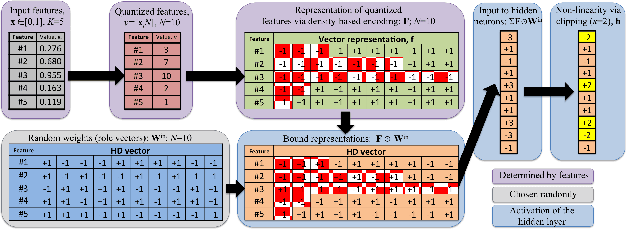
The deployment of machine learning algorithms on resource-constrained edge devices is an important challenge from both theoretical and applied points of view. In this article, we focus on resource-efficient randomly connected neural networks known as Random Vector Functional Link (RVFL) networks since their simple design and extremely fast training time make them very attractive for solving many applied classification tasks. We propose to represent input features via the density-based encoding known in the area of stochastic computing and use the operations of binding and bundling from the area of hyperdimensional computing for obtaining the activations of the hidden neurons. Using a collection of 121 real-world datasets from the UCI Machine Learning Repository, we empirically show that the proposed approach demonstrates higher average accuracy than the conventional RVFL. We also demonstrate that it is possible to represent the readout matrix using only integers in a limited range with minimal loss in the accuracy. In this case, the proposed approach operates only on small n-bits integers, which results in a computationally efficient architecture. Finally, through hardware FPGA implementations, we show that such an approach consumes approximately eleven times less energy than that of the conventional RVFL.
Integer Echo State Networks: Hyperdimensional Reservoir Computing
Sep 22, 2018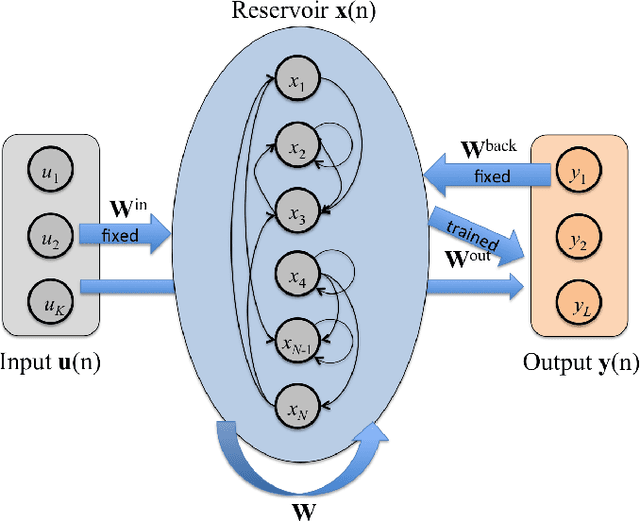
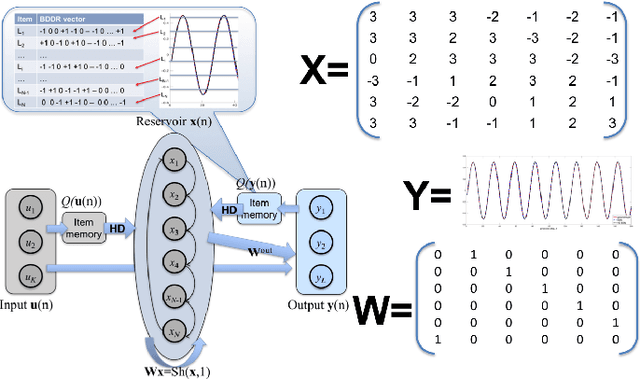
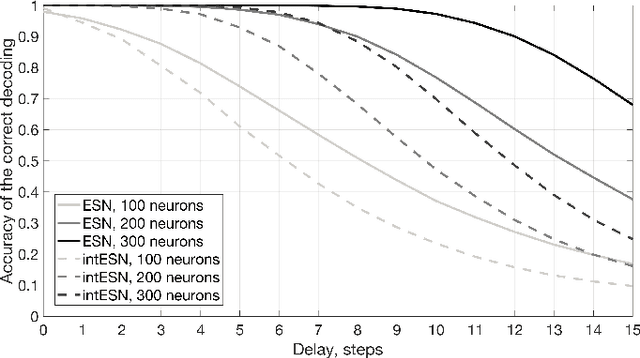
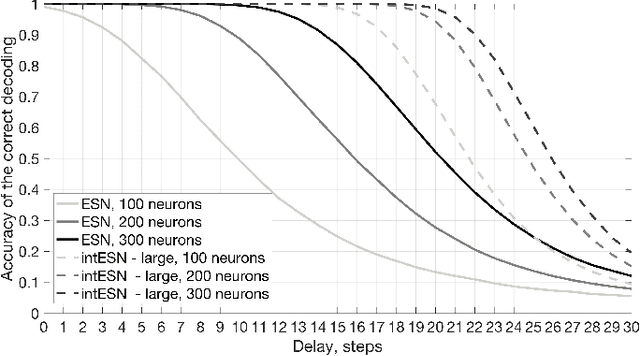
We propose an approximation of Echo State Networks (ESN) that can be efficiently implemented on digital hardware based on the mathematics of hyperdimensional computing. The reservoir of the proposed Integer Echo State Network (intESN) is a vector containing only n-bits integers (where n<8 is normally sufficient for a satisfactory performance). The recurrent matrix multiplication is replaced with an efficient cyclic shift operation. The intESN architecture is verified with typical tasks in reservoir computing: memorizing of a sequence of inputs; classifying time-series; learning dynamic processes. Such an architecture results in dramatic improvements in memory footprint and computational efficiency, with minimal performance loss.
A theory of sequence indexing and working memory in recurrent neural networks
Feb 28, 2018To accommodate structured approaches of neural computation, we propose a class of recurrent neural networks for indexing and storing sequences of symbols or analog data vectors. These networks with randomized input weights and orthogonal recurrent weights implement coding principles previously described in vector symbolic architectures (VSA), and leverage properties of reservoir computing. In general, the storage in reservoir computing is lossy and crosstalk noise limits the retrieval accuracy and information capacity. A novel theory to optimize memory performance in such networks is presented and compared with simulation experiments. The theory describes linear readout of analog data, and readout with winner-take-all error correction of symbolic data as proposed in VSA models. We find that diverse VSA models from the literature have universal performance properties, which are superior to what previous analyses predicted. Further, we propose novel VSA models with the statistically optimal Wiener filter in the readout that exhibit much higher information capacity, in particular for storing analog data. The presented theory also applies to memory buffers, networks with gradual forgetting, which can operate on infinite data streams without memory overflow. Interestingly, we find that different forgetting mechanisms, such as attenuating recurrent weights or neural nonlinearities, produce very similar behavior if the forgetting time constants are aligned. Such models exhibit extensive capacity when their forgetting time constant is optimized for given noise conditions and network size. These results enable the design of new types of VSA models for the online processing of data streams.
Theory of the superposition principle for randomized connectionist representations in neural networks
Jul 05, 2017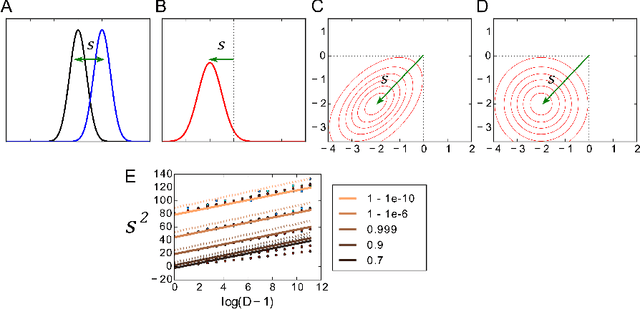
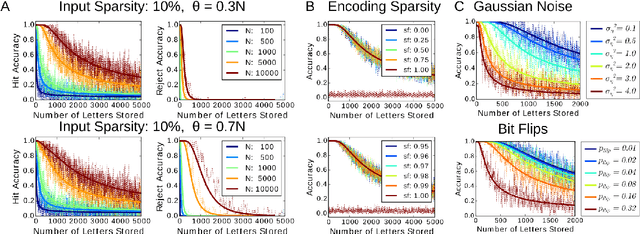
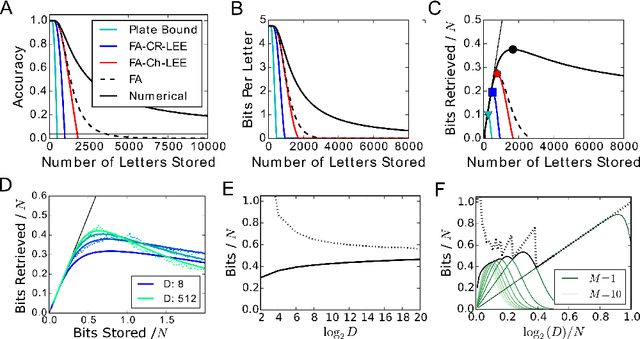
To understand cognitive reasoning in the brain, it has been proposed that symbols and compositions of symbols are represented by activity patterns (vectors) in a large population of neurons. Formal models implementing this idea [Plate 2003], [Kanerva 2009], [Gayler 2003], [Eliasmith 2012] include a reversible superposition operation for representing with a single vector an entire set of symbols or an ordered sequence of symbols. If the representation space is high-dimensional, large sets of symbols can be superposed and individually retrieved. However, crosstalk noise limits the accuracy of retrieval and information capacity. To understand information processing in the brain and to design artificial neural systems for cognitive reasoning, a theory of this superposition operation is essential. Here, such a theory is presented. The superposition operations in different existing models are mapped to linear neural networks with unitary recurrent matrices, in which retrieval accuracy can be analyzed by a single equation. We show that networks representing information in superposition can achieve a channel capacity of about half a bit per neuron, a significant fraction of the total available entropy. Going beyond existing models, superposition operations with recency effects are proposed that avoid catastrophic forgetting when representing the history of infinite data streams. These novel models correspond to recurrent networks with non-unitary matrices or with nonlinear neurons, and can be analyzed and optimized with an extension of our theory.