 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffQue: Estimating Relative Difficulty of Questions in Community Question Answering Services
Jun 01, 2019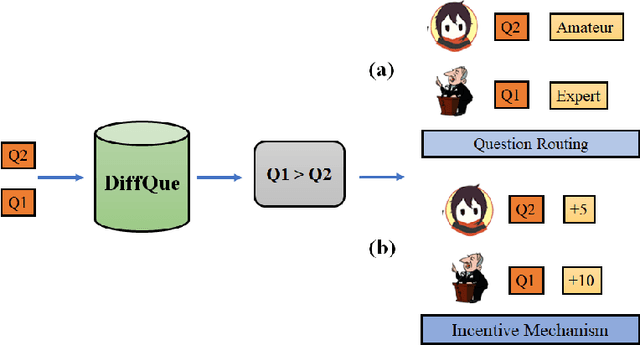
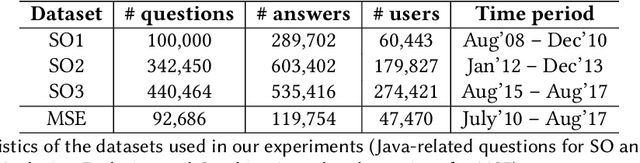
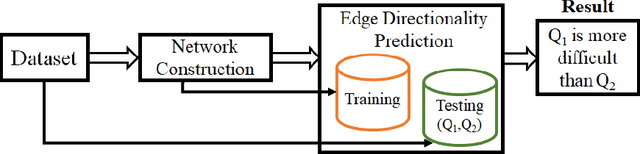
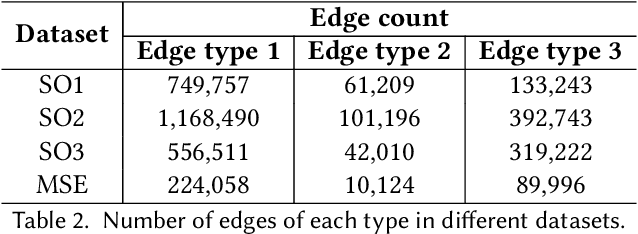
Automatic estimation of relative difficulty of a pair of questions is an important and challenging problem in community question answering (CQA) services. There are limited studies which addressed this problem. Past studies mostly leveraged expertise of users answering the questions and barely considered other properties of CQA services such as metadata of users and posts, temporal information and textual content. In this paper, we propose DiffQue, a novel system that maps this problem to a network-aided edge directionality prediction problem. DiffQue starts by constructing a novel network structure that captures different notions of difficulties among a pair of questions. It then measures the relative difficulty of two questions by predicting the direction of a (virtual) edge connecting these two questions in the network. It leverages features extracted from the network structure, metadata of users/posts and textual description of questions and answers. Experiments on datasets obtained from two CQA sites (further divided into four datasets) with human annotated ground-truth show that DiffQue outperforms four state-of-the-art methods by a significant margin (28.77% higher F1 score and 28.72% higher AUC than the best baseline). As opposed to the other baselines, (i) DiffQue appropriately responds to the training noise, (ii) DiffQue is capable of adapting multiple domains (CQA datasets), and (iii) DiffQue can efficiently handle 'cold start' problem which may arise due to the lack of information for newly posted questions or newly arrived users.
Crowd Sourced Data Analysis: Mapping of Programming Concepts to Syntactical Patterns
Mar 28, 2019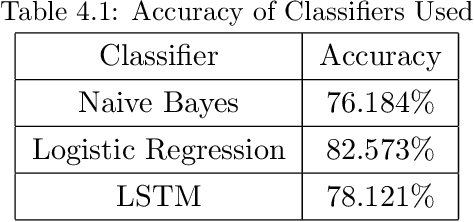

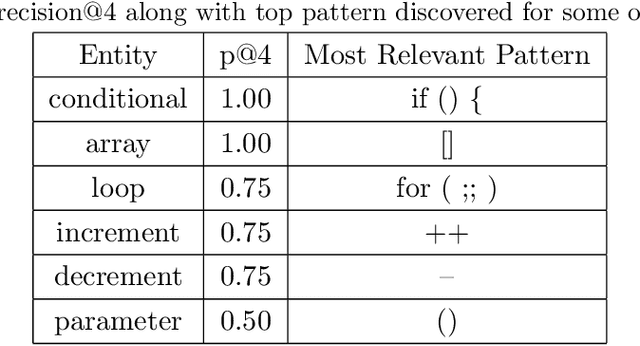
Since programming concepts do not match their syntactic representations, code search is a very tedious task. For instance in Java or C, array doesn't match [], so using "array" as a query, one cannot find what they are looking for. Often developers have to search code whether to understand any code, or to reuse some part of that code, or just to read it, without natural language searching, developers have to often scroll back and forth or use variable names as their queries. In our work, we have used Stackoverflow (SO) question and answers to make a mapping of programming concepts with their respective natural language keywords, and then tag these natural language terms to every line of code, which can further we used in searching using natural language keywords.