 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrelated Variational Auto-Encoders
May 16, 2019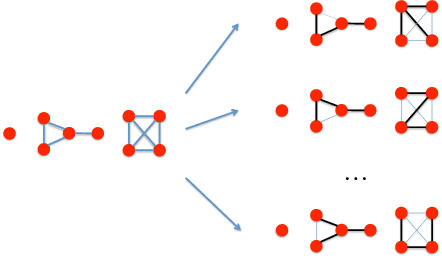
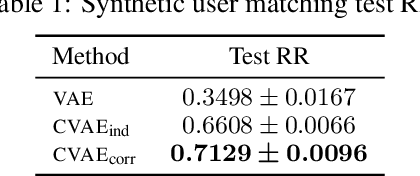

Variational Auto-Encoders (VAEs) are capable of learning latent representations for high dimensional data. However, due to the i.i.d. assumption, VAEs only optimize the singleton variational distributions and fail to account for the correlations between data points, which might be crucial for learning latent representations from dataset where a priori we know correlations exist. We propose Correlated Variational Auto-Encoders (CVAEs) that can take the correlation structure into consideration when learning latent representations with VAEs. CVAEs apply a prior based on the correlation structure. To address the intractability introduced by the correlated prior, we develop an approximation by average of a set of tractable lower bounds over all maximal acyclic subgraphs of the undirected correlation graph. Experimental results on matching and link prediction on public benchmark rating datasets and spectral clustering on a synthetic dataset show the effectiveness of the proposed method over baseline algorithms.
The Deconfounded Recommender: A Causal Inference Approach to Recommendation
Aug 20, 2018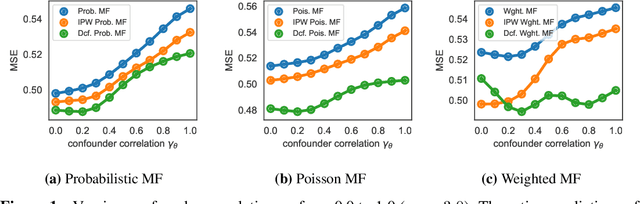
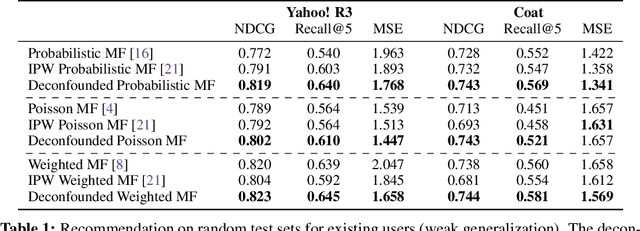
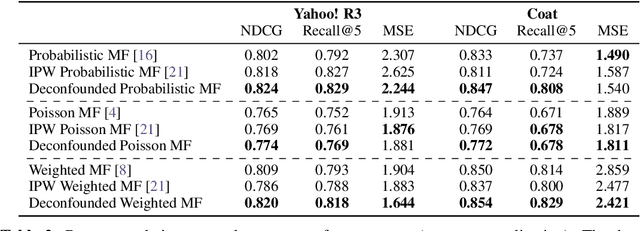
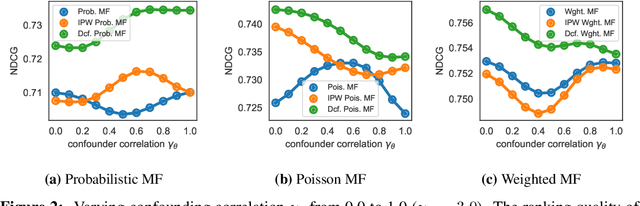
The goal of a recommender system is to show its users items that they will like. In forming its prediction, the recommender system tries to answer: "what would the rating be if we 'forced' the user to watch the movie?" This is a question about an intervention in the world, a causal question, and so traditional recommender systems are doing causal inference from observational data. This paper develops a causal inference approach to recommendation. Traditional recommenders are likely biased by unobserved confounders, variables that affect both the "treatment assignments" (which movies the users watch) and the "outcomes" (how they rate them). We develop the deconfounded recommender, a strategy to leverage classical recommendation models for causal predictions. The deconfounded recommender uses Poisson factorization on which movies users watched to infer latent confounders in the data; it then augments common recommendation models to correct for potential confounding bias. The deconfounded recommender improves recommendation and it enjoys stable performance against interventions on test sets.
Variational Autoencoders for Collaborative Filtering
Feb 16, 2018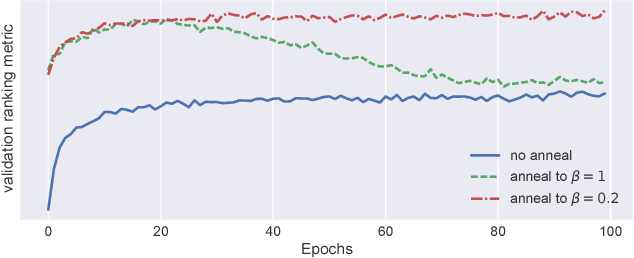
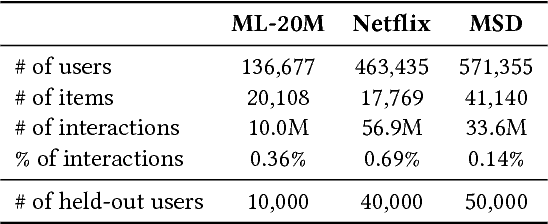
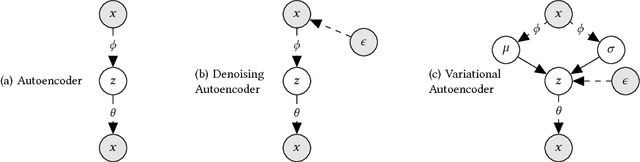
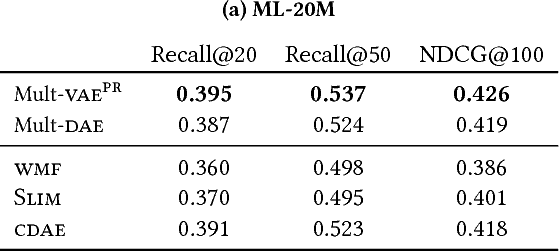
We extend variational autoencoders (VAEs) to collaborative filtering for implicit feedback. This non-linear probabilistic model enables us to go beyond the limited modeling capacity of linear factor models which still largely dominate collaborative filtering research.We introduce a generative model with multinomial likelihood and use Bayesian inference for parameter estimation. Despite widespread use in language modeling and economics, the multinomial likelihood receives less attention in the recommender systems literature. We introduce a different regularization parameter for the learning objective, which proves to be crucial for achieving competitive performance. Remarkably, there is an efficient way to tune the parameter using annealing. The resulting model and learning algorithm has information-theoretic connections to maximum entropy discrimination and the information bottleneck principle. Empirically, we show that the proposed approach significantly outperforms several state-of-the-art baselines, including two recently-proposed neural network approaches, on several real-world datasets. We also provide extended experiments comparing the multinomial likelihood with other commonly used likelihood functions in the latent factor collaborative filtering literature and show favorable results. Finally, we identify the pros and cons of employing a principled Bayesian inference approach and characterize settings where it provides the most significant improvements.
On the challenges of learning with inference networks on sparse, high-dimensional data
Oct 17, 2017
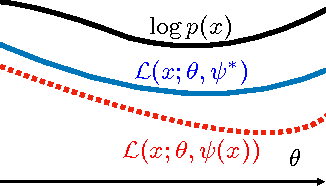
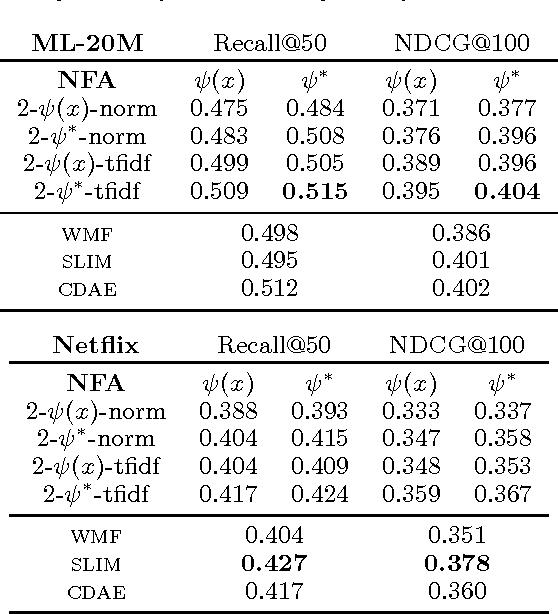
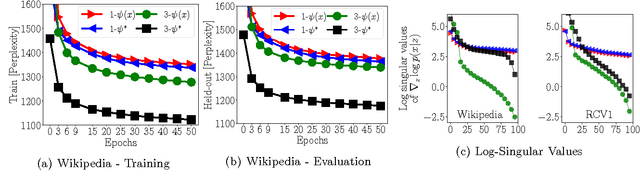
We study parameter estimation in Nonlinear Factor Analysis (NFA) where the generative model is parameterized by a deep neural network. Recent work has focused on learning such models using inference (or recognition) networks; we identify a crucial problem when modeling large, sparse, high-dimensional datasets -- underfitting. We study the extent of underfitting, highlighting that its severity increases with the sparsity of the data. We propose methods to tackle it via iterative optimization inspired by stochastic variational inference \citep{hoffman2013stochastic} and improvements in the sparse data representation used for inference. The proposed techniques drastically improve the ability of these powerful models to fit sparse data, achieving state-of-the-art results on a benchmark text-count dataset and excellent results on the task of top-N recommendation.
Edward: A library for probabilistic modeling, inference, and criticism
Feb 01, 2017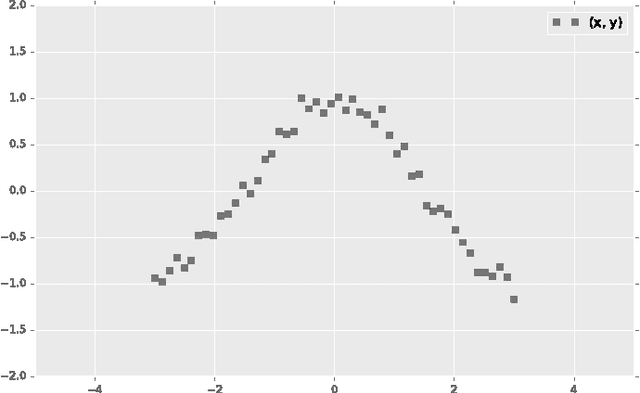
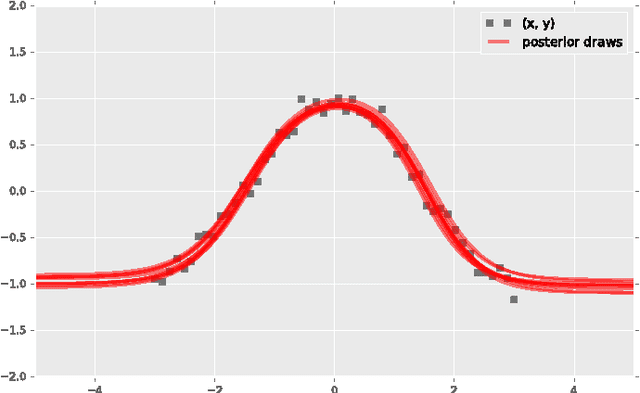
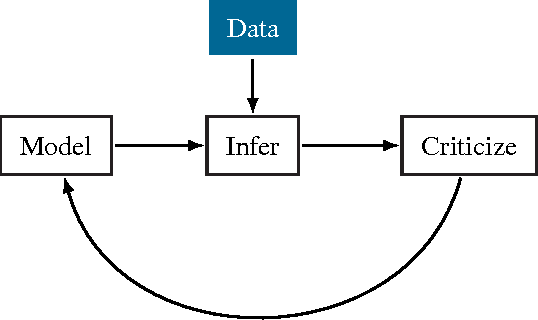
Probabilistic modeling is a powerful approach for analyzing empirical information. We describe Edward, a library for probabilistic modeling. Edward's design reflects an iterative process pioneered by George Box: build a model of a phenomenon, make inferences about the model given data, and criticize the model's fit to the data. Edward supports a broad class of probabilistic models, efficient algorithms for inference, and many techniques for model criticism. The library builds on top of TensorFlow to support distributed training and hardware such as GPUs. Edward enables the development of complex probabilistic models and their algorithms at a massive scale.
Modeling User Exposure in Recommendation
Feb 04, 2016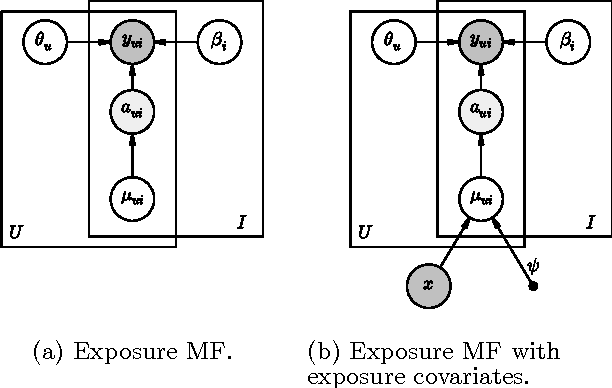
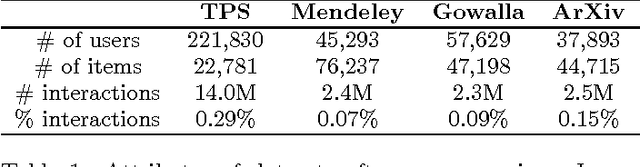

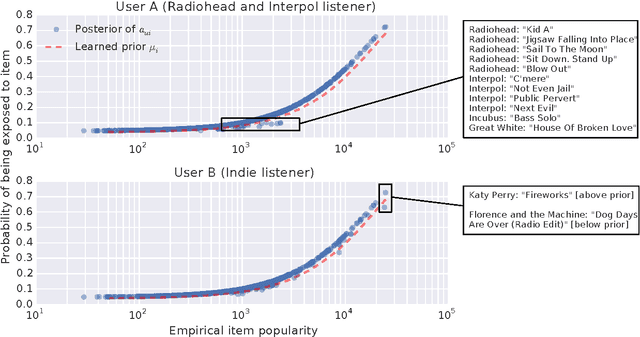
Collaborative filtering analyzes user preferences for items (e.g., books, movies, restaurants, academic papers) by exploiting the similarity patterns across users. In implicit feedback settings, all the items, including the ones that a user did not consume, are taken into consideration. But this assumption does not accord with the common sense understanding that users have a limited scope and awareness of items. For example, a user might not have heard of a certain paper, or might live too far away from a restaurant to experience it. In the language of causal analysis, the assignment mechanism (i.e., the items that a user is exposed to) is a latent variable that may change for various user/item combinations. In this paper, we propose a new probabilistic approach that directly incorporates user exposure to items into collaborative filtering. The exposure is modeled as a latent variable and the model infers its value from data. In doing so, we recover one of the most successful state-of-the-art approaches as a special case of our model, and provide a plug-in method for conditioning exposure on various forms of exposure covariates (e.g., topics in text, venue locations). We show that our scalable inference algorithm outperforms existing benchmarks in four different domains both with and without exposure covariates.
Beta Process Non-negative Matrix Factorization with Stochastic Structured Mean-Field Variational Inference
Dec 02, 2014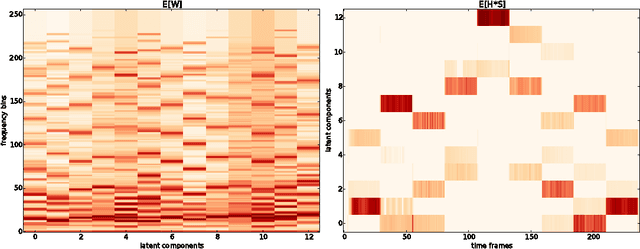

Beta process is the standard nonparametric Bayesian prior for latent factor model. In this paper, we derive a structured mean-field variational inference algorithm for a beta process non-negative matrix factorization (NMF) model with Poisson likelihood. Unlike the linear Gaussian model, which is well-studied in the nonparametric Bayesian literature, NMF model with beta process prior does not enjoy the conjugacy. We leverage the recently developed stochastic structured mean-field variational inference to relax the conjugacy constraint and restore the dependencies among the latent variables in the approximating variational distribution. Preliminary results on both synthetic and real examples demonstrate that the proposed inference algorithm can reasonably recover the hidden structure of the data.
A Generative Product-of-Filters Model of Audio
Nov 25, 2014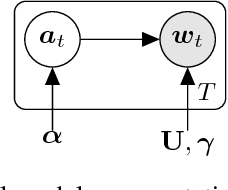
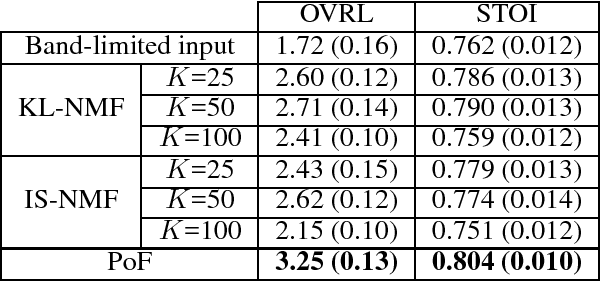
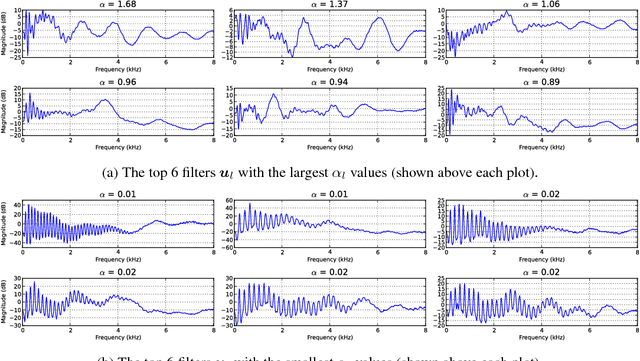

We propose the product-of-filters (PoF) model, a generative model that decomposes audio spectra as sparse linear combinations of "filters" in the log-spectral domain. PoF makes similar assumptions to those used in the classic homomorphic filtering approach to signal processing, but replaces hand-designed decompositions built of basic signal processing operations with a learned decomposition based on statistical inference. This paper formulates the PoF model and derives a mean-field method for posterior inference and a variational EM algorithm to estimate the model's free parameters. We demonstrate PoF's potential for audio processing on a bandwidth expansion task, and show that PoF can serve as an effective unsupervised feature extractor for a speaker identification task.