 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDavid Sontag
Evaluating Robustness to Dataset Shift via Parametric Robustness Sets
May 31, 2022
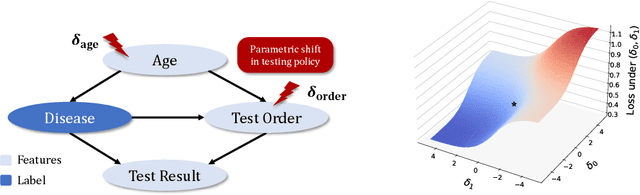

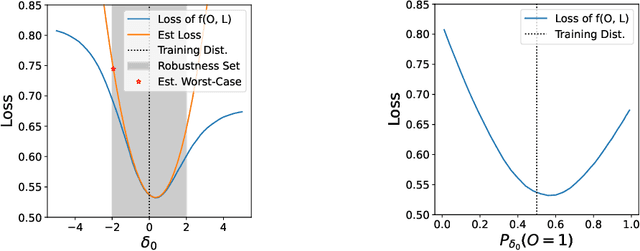
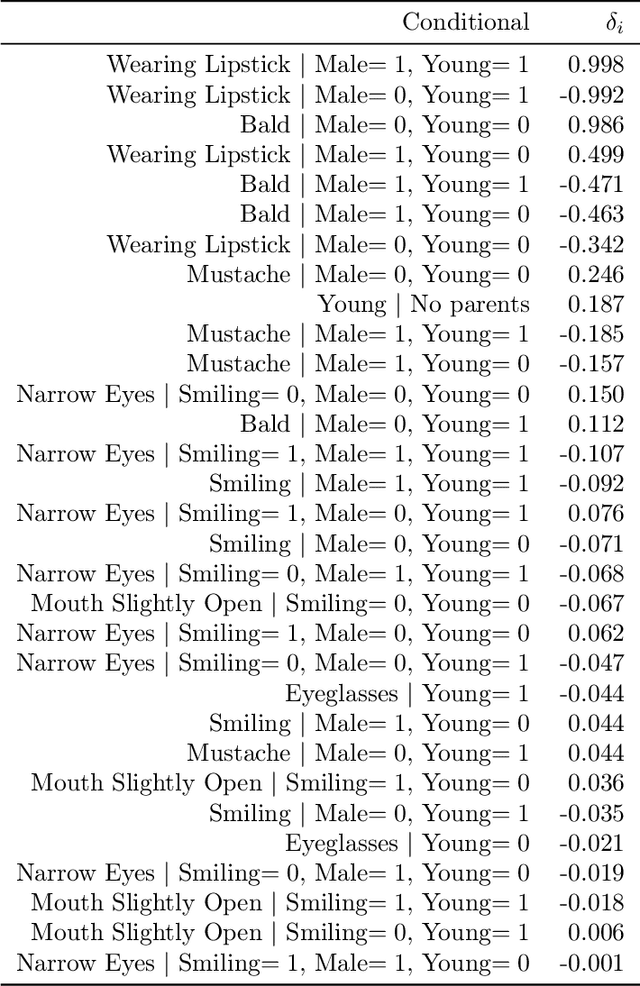
We give a method for proactively identifying small, plausible shifts in distribution which lead to large differences in model performance. To ensure that these shifts are plausible, we parameterize them in terms of interpretable changes in causal mechanisms of observed variables. This defines a parametric robustness set of plausible distributions and a corresponding worst-case loss. While the loss under an individual parametric shift can be estimated via reweighting techniques such as importance sampling, the resulting worst-case optimization problem is non-convex, and the estimate may suffer from large variance. For small shifts, however, we can construct a local second-order approximation to the loss under shift and cast the problem of finding a worst-case shift as a particular non-convex quadratic optimization problem, for which efficient algorithms are available. We demonstrate that this second-order approximation can be estimated directly for shifts in conditional exponential family models, and we bound the approximation error. We apply our approach to a computer vision task (classifying gender from images), revealing sensitivity to shifts in non-causal attributes.
Large Language Models are Zero-Shot Clinical Information Extractors
May 25, 2022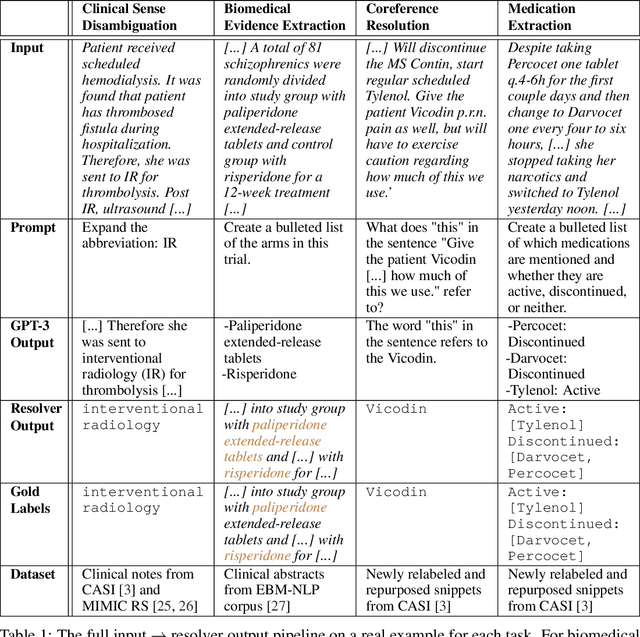


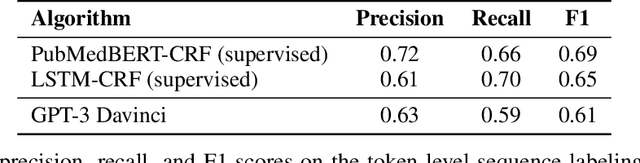
We show that large language models, such as GPT-3, perform well at zero-shot information extraction from clinical text despite not being trained specifically for the clinical domain. We present several examples showing how to use these models as tools for the diverse tasks of (i) concept disambiguation, (ii) evidence extraction, (iii) coreference resolution, and (iv) concept extraction, all on clinical text. The key to good performance is the use of simple task-specific programs that map from the language model outputs to the label space of the task. We refer to these programs as resolvers, a generalization of the verbalizer, which defines a mapping between output tokens and a discrete label space. We show in our examples that good resolvers share common components (e.g., "safety checks" that ensure the language model outputs faithfully match the input data), and that the common patterns across tasks make resolvers lightweight and easy to create. To better evaluate these systems, we also introduce two new datasets for benchmarking zero-shot clinical information extraction based on manual relabeling of the CASI dataset (Moon et al., 2014) with labels for new tasks. On the clinical extraction tasks we studied, the GPT-3 + resolver systems significantly outperform existing zero- and few-shot baselines.
Co-training Improves Prompt-based Learning for Large Language Models
Feb 02, 2022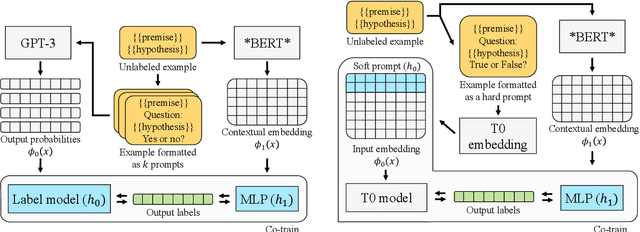
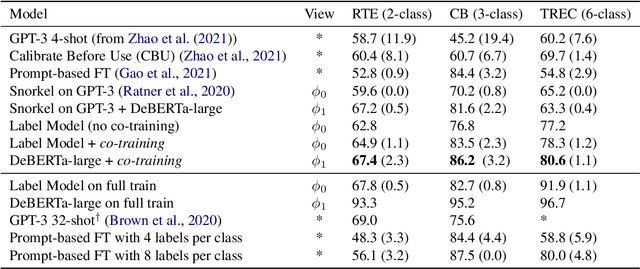
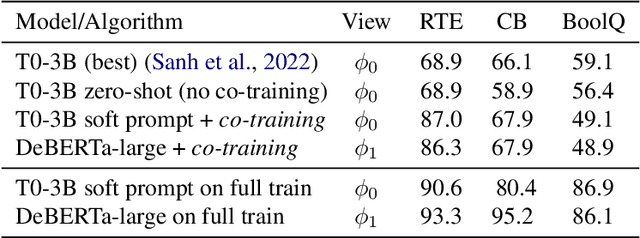
We demonstrate that co-training (Blum & Mitchell, 1998) can improve the performance of prompt-based learning by using unlabeled data. While prompting has emerged as a promising paradigm for few-shot and zero-shot learning, it is often brittle and requires much larger models compared to the standard supervised setup. We find that co-training makes it possible to improve the original prompt model and at the same time learn a smaller, downstream task-specific model. In the case where we only have partial access to a prompt model (e.g., output probabilities from GPT-3 (Brown et al., 2020)) we learn a calibration model over the prompt outputs. When we have full access to the prompt model's gradients but full finetuning remains prohibitively expensive (e.g., T0 (Sanh et al., 2021)), we learn a set of soft prompt continuous vectors to iteratively update the prompt model. We find that models trained in this manner can significantly improve performance on challenging datasets where there is currently a large gap between prompt-based learning and fully-supervised models.
Teaching Humans When To Defer to a Classifier via Examplars
Nov 22, 2021

Expert decision makers are starting to rely on data-driven automated agents to assist them with various tasks. For this collaboration to perform properly, the human decision maker must have a mental model of when and when not to rely on the agent. In this work, we aim to ensure that human decision makers learn a valid mental model of the agent's strengths and weaknesses. To accomplish this goal, we propose an exemplar-based teaching strategy where humans solve the task with the help of the agent and try to formulate a set of guidelines of when and when not to defer. We present a novel parameterization of the human's mental model of the AI that applies a nearest neighbor rule in local regions surrounding the teaching examples. Using this model, we derive a near-optimal strategy for selecting a representative teaching set. We validate the benefits of our teaching strategy on a multi-hop question answering task using crowd workers and find that when workers draw the right lessons from the teaching stage, their task performance improves, we furthermore validate our method on a set of synthetic experiments.
Leveraging Time Irreversibility with Order-Contrastive Pre-training
Nov 04, 2021
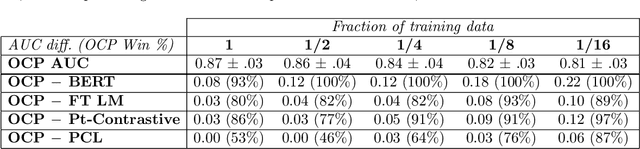
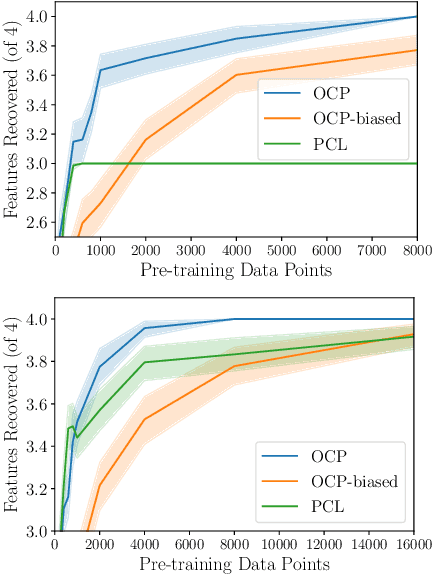

Label-scarce, high-dimensional domains such as healthcare present a challenge for modern machine learning techniques. To overcome the difficulties posed by a lack of labeled data, we explore an "order-contrastive" method for self-supervised pre-training on longitudinal data. We sample pairs of time segments, switch the order for half of them, and train a model to predict whether a given pair is in the correct order. Intuitively, the ordering task allows the model to attend to the least time-reversible features (for example, features that indicate progression of a chronic disease). The same features are often useful for downstream tasks of interest. To quantify this, we study a simple theoretical setting where we prove a finite-sample guarantee for the downstream error of a representation learned with order-contrastive pre-training. Empirically, in synthetic and longitudinal healthcare settings, we demonstrate the effectiveness of order-contrastive pre-training in the small-data regime over supervised learning and other self-supervised pre-training baselines. Our results indicate that pre-training methods designed for particular classes of distributions and downstream tasks can improve the performance of self-supervised learning.
Using Time-Series Privileged Information for Provably Efficient Learning of Prediction Models
Oct 28, 2021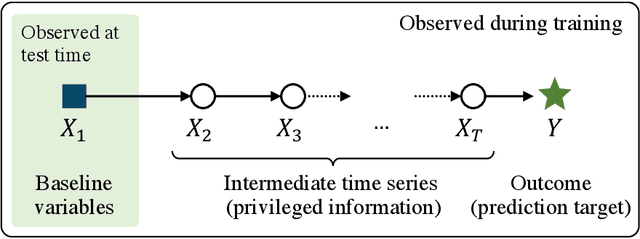
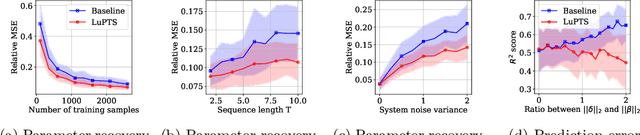
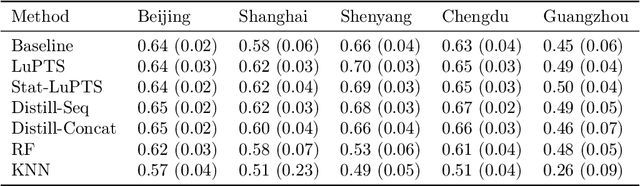
We study prediction of future outcomes with supervised models that use privileged information during learning. The privileged information comprises samples of time series observed between the baseline time of prediction and the future outcome; this information is only available at training time which differs from the traditional supervised learning. Our question is when using this privileged data leads to more sample-efficient learning of models that use only baseline data for predictions at test time. We give an algorithm for this setting and prove that when the time series are drawn from a non-stationary Gaussian-linear dynamical system of fixed horizon, learning with privileged information is more efficient than learning without it. On synthetic data, we test the limits of our algorithm and theory, both when our assumptions hold and when they are violated. On three diverse real-world datasets, we show that our approach is generally preferable to classical learning, particularly when data is scarce. Finally, we relate our estimator to a distillation approach both theoretically and empirically.
Finding Regions of Heterogeneity in Decision-Making via Expected Conditional Covariance
Oct 27, 2021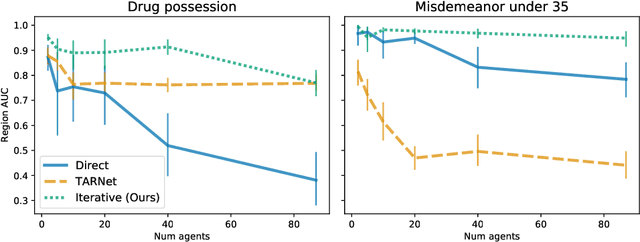
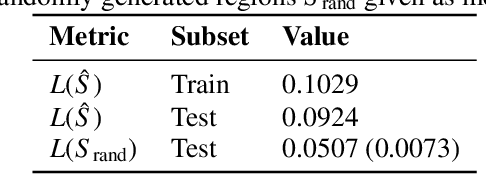
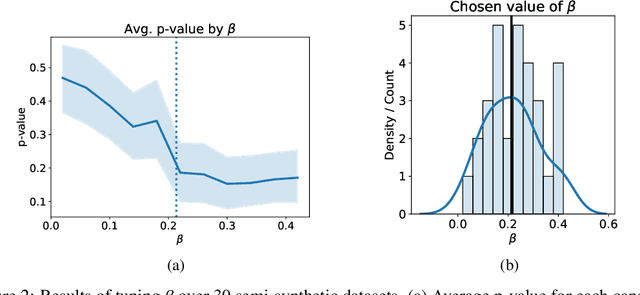

Individuals often make different decisions when faced with the same context, due to personal preferences and background. For instance, judges may vary in their leniency towards certain drug-related offenses, and doctors may vary in their preference for how to start treatment for certain types of patients. With these examples in mind, we present an algorithm for identifying types of contexts (e.g., types of cases or patients) with high inter-decision-maker disagreement. We formalize this as a causal inference problem, seeking a region where the assignment of decision-maker has a large causal effect on the decision. Our algorithm finds such a region by maximizing an empirical objective, and we give a generalization bound for its performance. In a semi-synthetic experiment, we show that our algorithm recovers the correct region of heterogeneity accurately compared to baselines. Finally, we apply our algorithm to real-world healthcare datasets, recovering variation that aligns with existing clinical knowledge.
CLIP: A Dataset for Extracting Action Items for Physicians from Hospital Discharge Notes
Jun 04, 2021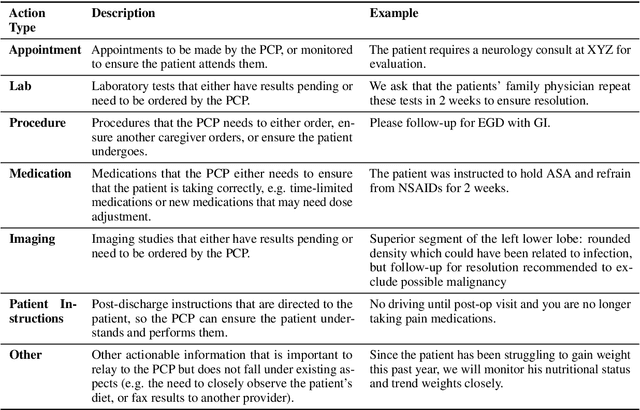

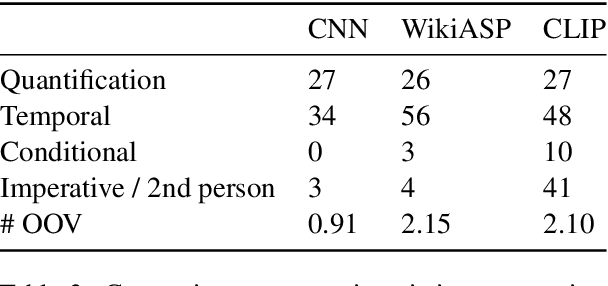
Continuity of care is crucial to ensuring positive health outcomes for patients discharged from an inpatient hospital setting, and improved information sharing can help. To share information, caregivers write discharge notes containing action items to share with patients and their future caregivers, but these action items are easily lost due to the lengthiness of the documents. In this work, we describe our creation of a dataset of clinical action items annotated over MIMIC-III, the largest publicly available dataset of real clinical notes. This dataset, which we call CLIP, is annotated by physicians and covers 718 documents representing 100K sentences. We describe the task of extracting the action items from these documents as multi-aspect extractive summarization, with each aspect representing a type of action to be taken. We evaluate several machine learning models on this task, and show that the best models exploit in-domain language model pre-training on 59K unannotated documents, and incorporate context from neighboring sentences. We also propose an approach to pre-training data selection that allows us to explore the trade-off between size and domain-specificity of pre-training datasets for this task.
Regularizing towards Causal Invariance: Linear Models with Proxies
Mar 03, 2021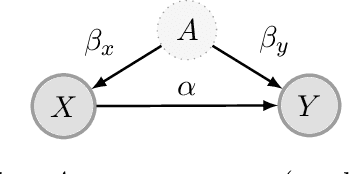
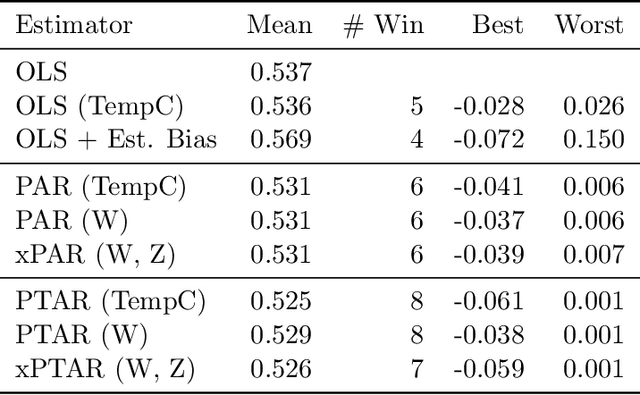
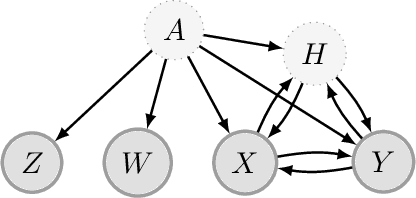
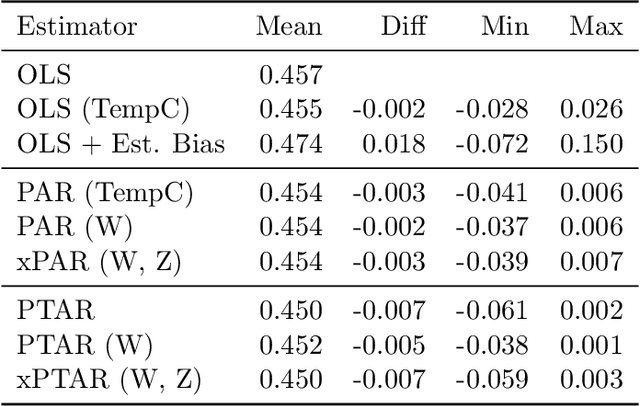
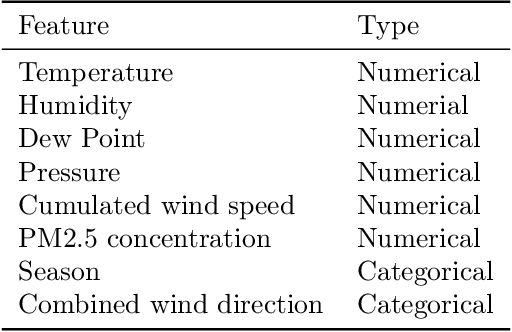
We propose a method for learning linear models whose predictive performance is robust to causal interventions on unobserved variables, when noisy proxies of those variables are available. Our approach takes the form of a regularization term that trades off between in-distribution performance and robustness to interventions. Under the assumption of a linear structural causal model, we show that a single proxy can be used to create estimators that are prediction optimal under interventions of bounded strength. This strength depends on the magnitude of the measurement noise in the proxy, which is, in general, not identifiable. In the case of two proxy variables, we propose a modified estimator that is prediction optimal under interventions up to a known strength. We further show how to extend these estimators to scenarios where additional information about the "test time" intervention is available during training. We evaluate our theoretical findings in synthetic experiments and using real data of hourly pollution levels across several cities in China.
Beyond Perturbation Stability: LP Recovery Guarantees for MAP Inference on Noisy Stable Instances
Feb 26, 2021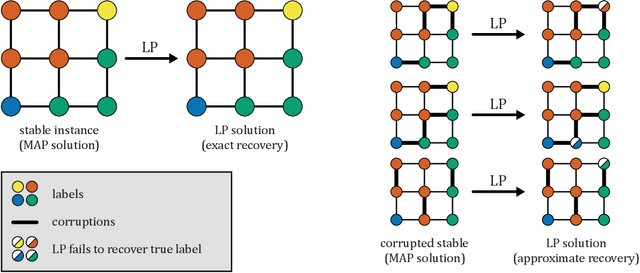

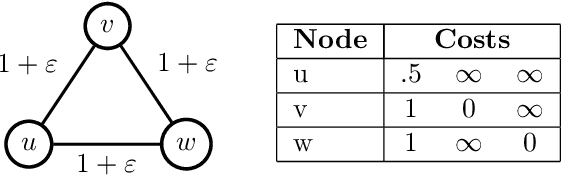

Several works have shown that perturbation stable instances of the MAP inference problem in Potts models can be solved exactly using a natural linear programming (LP) relaxation. However, most of these works give few (or no) guarantees for the LP solutions on instances that do not satisfy the relatively strict perturbation stability definitions. In this work, we go beyond these stability results by showing that the LP approximately recovers the MAP solution of a stable instance even after the instance is corrupted by noise. This "noisy stable" model realistically fits with practical MAP inference problems: we design an algorithm for finding "close" stable instances, and show that several real-world instances from computer vision have nearby instances that are perturbation stable. These results suggest a new theoretical explanation for the excellent performance of this LP relaxation in practice.